有这样一张表,“non_response_num”是真实非应答次数,“predict_non_response_num”是模型预测的非应答次数。

想计算每个时间片内不同group_id的所有hex_center的MAE值,用groupby方法:
from sklearn import metrics merge_df.groupby(['time_slot', 'booking_groupid'])
.apply(lambda x: metrics.mean_absolute_error(x.non_response_num, x.predict_non_response_num))
.reset_index(name='MAE')
groupby后加apply,lambda匿名函数中x表示当前聚到一起的行,利用sklearn计算MAE的值。
这里groupby返回的结果是series,keys为'time_slot', 'booking_groupid' ,values为计算得出的MAE
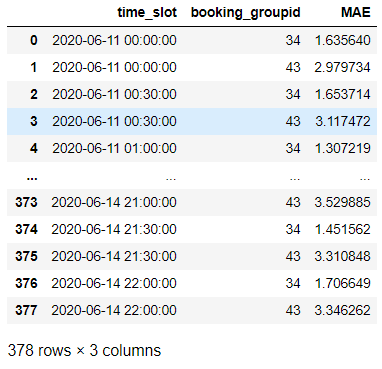
想将此series转换成dataframe,有三种方法:
1、在apply()之后用.reset_index()方法,参数name是列名
2、用.to_frame()方法
3、将series的key和value取出,构建新的frame
dict = {'index':test_series.keys, 'MAE':test_series.values}
df = pd.DataFrame(dict)
第一种方法得到结果