为什么re.match匹配不到?re.match匹配规则怎样?(捕一下seo)
re.match(pattern, string[, flags])
pattern为匹配规则,即输入正则表达式。
string为,待匹配的文本或字符串。
网上的定义【 从要匹配的字符串的头部开始,当匹配到string的尾部还没有匹配结束时,返回None;
当匹配过程中出现了无法匹配的字母,返回None。】
但我觉得要强调关键一句【仅从要匹配的字符串头部开始匹配!】
看看例子,你就明白了!!!想用的话,一定要看!

出现<_src.SRE_Match object at .....>表示匹配成功。
出现None表示,匹配失败或未匹配到。
总结:re.match只从待匹配的字符串或文本的开头开始匹配,即如果匹配的字符串不在开头,而是在中间或结尾,则无法匹配!
———————————————————分割线——————————————————
顺便对比下re.match、re.search、re.findall的区别
match()函数只在string的开始位置匹配(例子如上图)。
search()会扫描整个string查找匹配,会扫描整个字符串并返回第一个成功的匹配。

re.findall()将返回一个所匹配的字符串的字符串列表。

———————————————————分割线——————————————————
《用python写网络爬虫》中1.4.4链接爬虫中,下图为有异议代码

这里的输出经测试,根本啥也没有,如下图

查了很久,应该是因为re.match一直匹配不到数据引起的,毕竟他只匹配开头。
我将re.match改为re.search,再测试,可正常下载
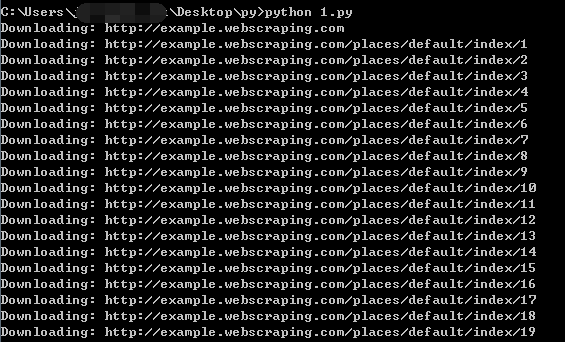
分析:可能是由于书编写时,http://example.webscraping.com/页面所带的链接都是:/index/1、/index/2……且输入匹配表达式为 【 /(index/view) 】,使用的是re.match匹配,如果匹配上述的url则没问题,而现在该网站页面所带的链接为:/places/default/index/1、/places/default/index/2……所以,上文讲到的re.match的特点,从开头开始匹配,则这时候re.match就会一直匹配不上!我将它换位re.search就可以解决这个问题了。
如有错误,麻烦及时指正,谢谢!