目标:爬取某网站比赛赛程,动态网页,则需找到对应ajax请求(具体可参考:https://blog.csdn.net/you_are_my_dream/article/details/53399949)
# -*- coding:utf-8 -*- import sys import re import urllib.request link = "https://***" r = urllib.request.Request(link) r.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36') html = urllib.request.urlopen(r,timeout=500).read() html = bytes.decode(html,encoding="gbk")
#返回大量json,需提取 #找出返回json中对应正则匹配的字符串 js = re.findall('"n":"(.*?)"',html) i=0 #循环打印比赛信息 try: while(1):
#将字符串Unicode转化为中文,并输出 print (js[i].encode('utf-8').decode('unicode_escape'),js[i+1].encode('utf-8').decode('unicode_escape'),"VS",js[i+2].encode('utf-8').decode('unicode_escape')) i=i+3
#当所有赛程爬取结束时,会报错“IndexError:list index out of range”,所以进行异常处理 except IndexError: print ("finished")
总结注意点:
1、python 3 采用这个import urllib.request
因为urllib和urllib2合体了。
2、字符串Unicode转为中文需注意python3与python2的表示方法不同:
python3:print 字符串.encode('utf-8').decode('unicode_escape')
python2:print 字符串.decode('unicode_escape')
3、re.findall()
关于这个函数,他的输出内容规律可以参考我之前写的:http://www.cnblogs.com/4wheel/p/8497121.html
【"n":"(.*?)"】 这个表达式只输出(.*?)这部分(为什么,还是参考我之前写的那篇文章),加上问号就是非贪婪模式,不加就是贪婪模式,顺便实践解释下贪婪模式
example:
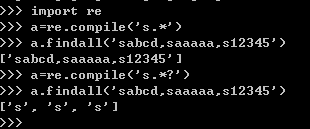
总结:非贪婪模式就是在满足正则表达式的情况下,尽可能少的匹配。
相反,贪婪模式就是在满足正则表达式的情况下,尽可能多的匹配。
so,爬取结果为:
