- 为什么需要 Raft?
- Raft 是什么?
- Raft 的目标
- 前置条件:复制状态机
- Raft 基础
- Leader 选举(选举安全特性)
- 日志复制(Leader只附加、日志匹配)
- 安全
- 学习资料
- 使用 Raft 的应用?
- 扩展:ZooKeeper ZAB 协议
- 扩展:ZooKeeper 是什么?
为什么需要 Raft?
- 要提高
系统的容错率,需要分布式系统 - 分布式系统有多个实例,对于给定的一组操作,需要协议让
所有实例达成一致(分布式一致性) - Paxos 是分布式一致性协议的标准,但难以理解、实现
- Raft 提供了和 Paxos 算法相同的功能,但更好理解、构建实际的系统
Raft 是什么?
- Replicated And Fault Tolerant,
复制和容错 - 管理复制
日志的一致性算法
Raft 的目标
- 简单易理解
- 提供完整的实现系统,减少开发者的工作量
- 保证所有条件下都是安全的,在大部分情况下是可用的
- 常用操作是高效的
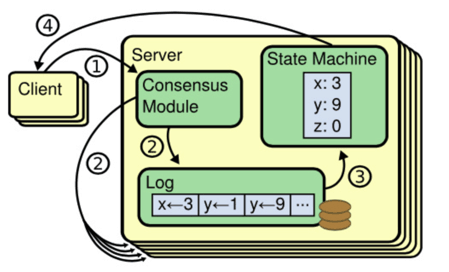
前置条件:复制状态机
- Raft 相当于复制状态机中的“
一致性模块” - 一致性模块(Consensus Module):管理来自客户端的指令,接入 log
- 日志(Log)
- 状态机(State Machine):执行日志的指令,得到 Server 状态
Raft 基础
- 节点状态:
Leader(领导者):系统只有一个节点处是 Leader,处理所有客户端的请求并同步给 FollowerFollower(跟随者):只响应其他服务器(Leader、Candidate)的请求Candidate(候选者):在选举领导的时候出现
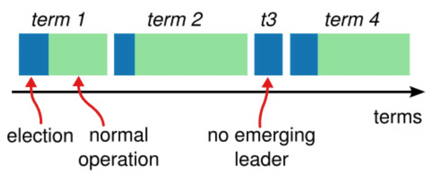
- term(任期):
- 一段选举的任期(选举开始+正常工作)
- term 号自动 +1
- 如果选票均分,则该 term 直接结束,进入下一个 term
- Raft 中的
「逻辑时钟」,可发现过期信息,规则:- 每个节点会存储当前 term 号,term 编号单调递增
- 节点间通信,交换 term 号
- (1)节点当前 term 号 < 他人 term 号,更新 term 号
- (2)节点当前 term 号 > 他人 term 号,拒绝请求
- (3)Candidate、Leader 发现自己的 term < 他人 term,立即变成 Follower
- 节点通信:使用
RPC- 请求投票(RequestVote) RPCs:选举阶段,Candidate 节点发送给他人
- 附加条目(AppendEntries)RPCs:非选举阶段,Leader 发给所有节点,复制日志+心跳
- 特性(Raft 保证在任何时候都成立)
- 选举安全:对一个给定的 term 号,最多选举出一个 Leader
- Leader 只附加原则:Leader 不会删除、覆盖自己的日志,只会增加
- 日志匹配:若两个日志在相同索引位置的日志的 term 号相同,则日志从头到该索引位置全部相同
- Leader 完整特性:选举出的 Leader,会包含所有已提交的日志
- 状态机安全特性:Leader 已经将给定的索引值位置的日志条目应用到状态机,其他任何服务器都已执行
Leader 选举(选举安全特性)
- Raft 使用心跳机制触发 Leader 选举
- 集群存在 Leader,Leader 节点周期性发心跳包
- 一个 Follower 没有收到任何消息(固定区间随机的时间),发起选举
- 集群启动时,所有节点都处于 Follower 状态
- 节点到达超时时间后,会进入 Candidate 状态,增加自己的 term 号,发送请求投票给自己
- Candidate 状态机
- 节点得票最多的,变成 Leader
- 收到来自其他节点的“声明自己是 Leader”的请求
- 一段时间后,没有获得多数票,也没有收到其他节点的 Leader 通知(平分选票)
- 避免选举的平分选票:随机选举超时时间
- 每个节点随机选择选举超时时间,到达时间后成为 Candidate
- 大多数情况下,只有一个节点率先进入 Candidate
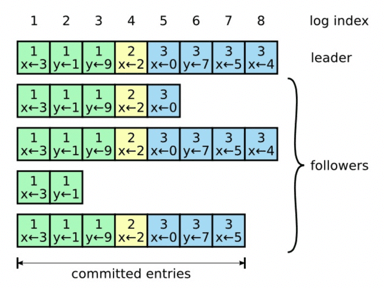
日志复制(Leader只附加、日志匹配)
- Leader 会接收客户端的请求,请求指令作为一个“日志条目”添加到日志中
- 向所有 Follower 发送附加条目 RPC,让他们复制这个日志条目
- 得到大多数节点回复后,Leader 会把日志写入复制状态机,持久化,把执行结果返回给客户端
- 日志非安全的;进入状态机中是安全的(已提交),最终会被所有可用的状态机执行。
index = 7 的日志已经被大多数节点复制,状态为已提交。
安全
- 选举限制(Leader 完整性):每次选举出来的 Leader,必须包含所有已提交的日志
- 只有已经被大部分节点复制的日志,才会变成“已提交”
- 一个 Candidate 必须得到大部分节点投票,才能变成 Leader
- 投票时,节点不会把票投给没有自己的日志新的 Candidate
- Follower 或 Candidate 崩溃:无限重试
- 超时和可用性:broadcastTime(广播时间)<< electionTimeout(选举超时时间)<< MTBF(平均故障间隔时间)
学习资料
使用 Raft 的应用?
- 服务发现框架:consul、
etcd - 日志:
RocketMQ - 数据存储:
Tidb、k8s
扩展:ZooKeeper ZAB 协议
- 支持崩溃恢复的原子广播协议:
ZooKeeper Atomic Broadcast protocol - ZooKeeper 适合
读多写少的场景,客户端随机连到 ZK 集群的一个节点- 从当前节点读
- 写入到 leader,leader 广播事务,半数节点成功才会被提交
整体流程类似于 Raft,只是细节和实现的区别
扩展:ZooKeeper 是什么?
官方定义: A Distributed Coordination Service for Distributed Applications。本质:基于内存的 KV 系统,以 path 为 key。
代码、思维导图笔记链接
代码和思维导图在 GitHub 项目中,欢迎大家 star!
coding 笔记、点滴记录,以后的文章也会同步到公众号(Coding Insight)中,希望大家关注_
