Scrapy爬虫框架结构及工作原理详解
scrapy框架的框架结构如下:
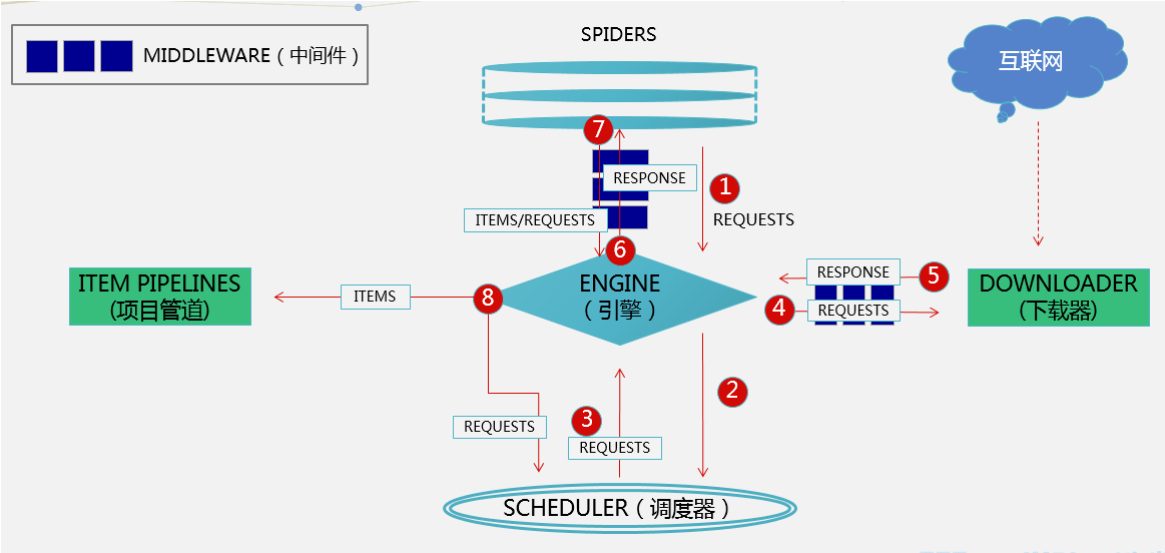
组件分析:
ENGINE:(核心):处理整个框架的数据流,各个组件在其控制下协同工作
SCHEDULER(调度器):负责接收引擎发送来的请求,并压入队列,在引擎再次请求时返回
SPIDER(蜘蛛):负责从网页中提取指定的信息,即item并产生对新页面的下载请求
DOWNLOADER(下载器):用于下载网页内容(即发送HTTP请求/接受HTTP请求)并将内容返回给ENGINE
ITEM PIPELINES(项目管道):主要对爬取到的数据进行处理(去重、过滤、清洗),最终保存数据
DOWNLOADER MIDDLEWARES(下载中间件):位于ENGINE和DOWNLOADER中间,处理请求和响应(该组件是反反爬虫的重点)
SPIDER MIDDLEWARES(爬虫中间件):位于SPIDER和ENGINE中间,处理蜘蛛的请求和响应
数据流对象分析:(主要有三)
(1)REQUEST:scrapy中的hettp请求对象
(2)RESPONSE:scrapy中的http响应对象
(3)ITEM:页面爬取到的数据
工作原理:
(1)、Spiders发送第一个URL给引擎
(2)、引擎从Spider中获取到第一个要爬取的URL后,在调度器(Scheduler)以Request调度
(3)、调度器把需要爬取的request返回给引擎
(4)、引擎将request通过下载中间件发给下载器(Downloader)去互联网下载数据
(5)、一旦数据下载完毕,下载器获取由互联网服务器发回来的Response,并将其通过下载中间件发送给引擎
(6)、引擎从下载器中接收到Response并通过Spider中间件发送给Spider处理
(7)、Spider处理Response并从中返回匹配到的Item及(跟进的)新的Request给引擎
(8)、引擎将(Spider返回的)爬取到的Item给Item Pipeline做数据处理或者入库保存,将(Spider返回的)Request给调度器入队列
(9)、重复第(3)步循环运行直至SCHCULAR中没有REQUEST为止
总结:这章我们学习了整个scrapy框架的结构及工作原理,小伙伴们清楚了吗?(刚全宿舍去看了复联3,突然发现灭霸并没有那么坏!雷神真tm叼!)
