(1)、简介
在糗事百科爬虫中我们的爬虫是继承scrapy.Spider类的,这也是基本的scrapy框架爬虫,在这个爬虫中我们自己在解析完整个页面后再获取下一页的url,然后重新发送了一个请求,而使用CrawlsSpider类可以帮助我们对url提出条件,只要满足这个条件,都进行爬取,CrawlSpider类继承自Spider,它比之前的Spider增加了新功能,即可以定义url的爬取规则,而不用手动的yield Request。

(2)、创建CrawlSpider爬虫
scrapy genspider -t crawl + 爬虫名 + 主域名
(3)、CrawlSpider中的主要模块介绍
1、LinkExtractors链接提取器(找到满足规则的url进行爬取)
class crapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href', ), canonicalize=True, unique=True, process_value=None)
主要参数介绍:
allow:允许的url,所有满足这个正则表达式的url都会被提取
deny:禁止的url,所有满足这个正则表达式的url都不会被提取
allow_domains:允许的域名,在域名中的url才会被提取
deny_domains:禁止的域名,在域名中的url不会被提取
restrict_xpaths:使用xpath提取
restrict_css:使用css提取
2、Rule规则类
class scrapy.contrib.spiders.Rule(link_extractor,callback=None,cb_kwargs=None,follow=None,process_links=None,process_request=None)
主要参数介绍:
link_extractor:一个LinkExtractor对象,用来定义爬取规则
callback:回调函数
follow:从response中提取的url如满足条件是否进行跟进
process_links:从link_extractor中获取到的链接首先会传递给该函数,主要用来过滤掉无用的链接
(4)、实验(微信小程序社区爬虫)
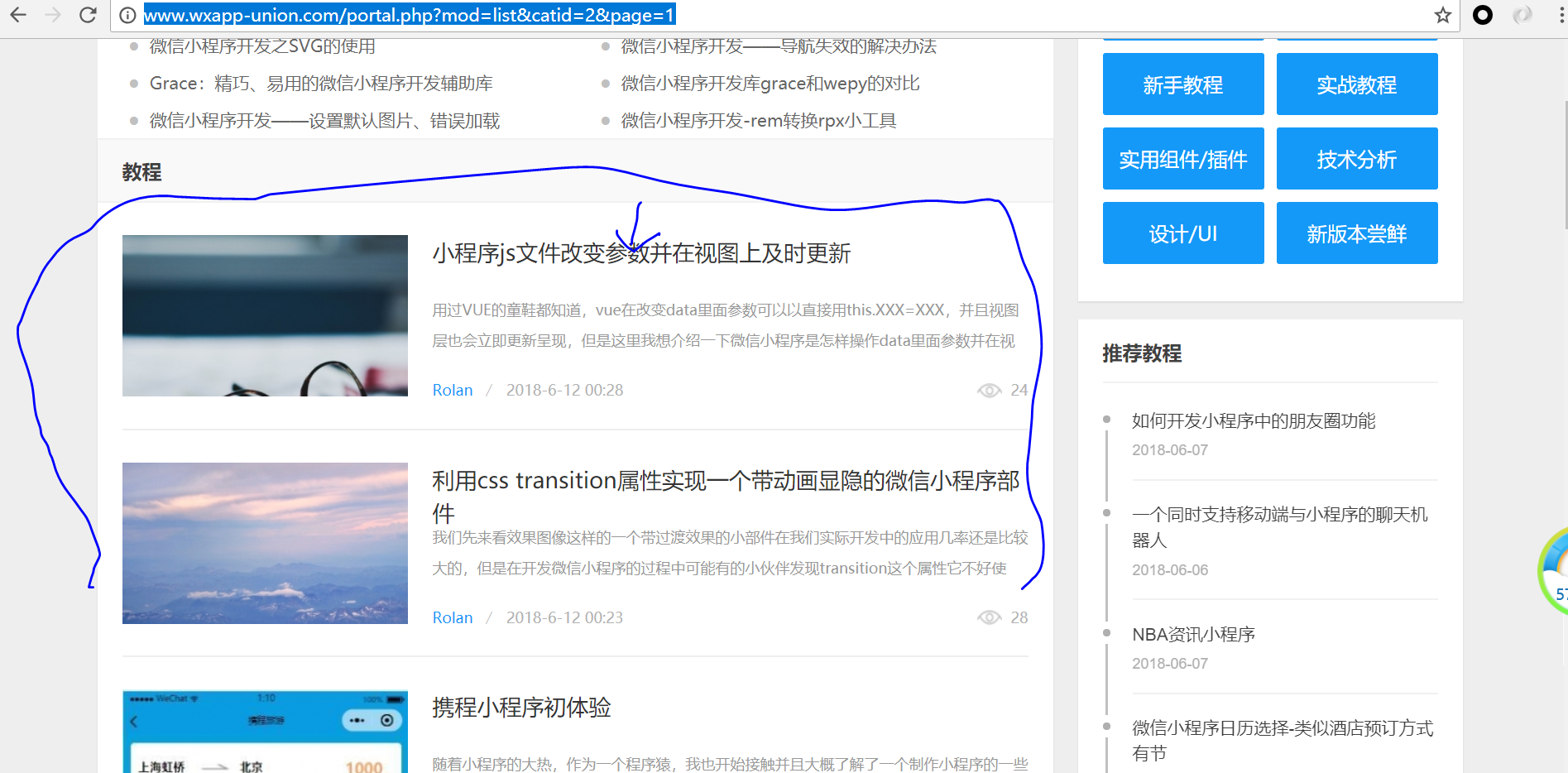
1、目标站点选取(http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1)
2、创建项目和爬虫
scrapy startproject weixin_app---cd weixin_app---scrapy genspider -t crawl spider wxapp-union.com
观察一下发现spider.py文件已改变了
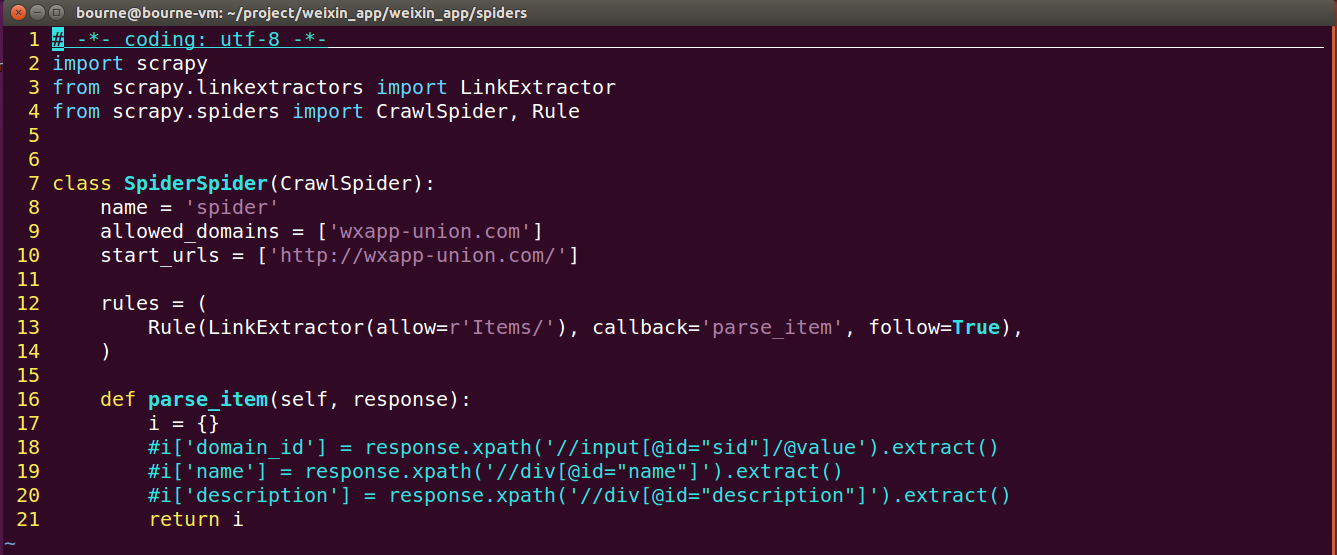
3、编写代码
改写settings.py
禁止遵循robots协议

设置请求头

设置爬取延迟

开启pipeline

改写items.py

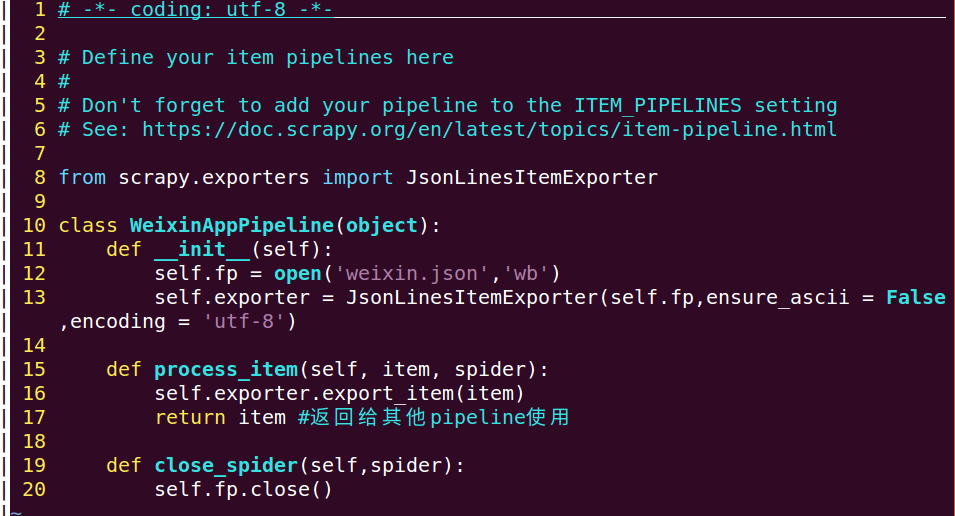
改写pipeline.py
改写spiders.py


(5)、运行效果展示(只贴出了第一条数据)
(6)、总结
1、CrawlSpider主要使用LinkExtractor 和 Rule
2、注意事项:allow设置方法:限定在我们想要的url上,不要与其他url产生相同的正则表达式,follow设置方法:在爬取页面的时候需要将满足条件的url进行跟进,设置为True,callback设置方法:在获取详情信息的页面需指定callback,而对于只要获取url,而不要具体数据的情况则不需要指定该参数。