(1)、前言
原理分析:我们编写代码模拟向网站发出登录请求,也就是提交包含登录信息的表单(用户名、密码等)。
实现方式:当我们想在请求数据时发送post请求,这时候需要借助Request的子类FormRequest来实现,如果想进一步在爬虫一开始时就发送post请求,那么我们需要重写start_request()方法,舍弃原先的start_url()(采用get请求)
(2)、模拟登录人人网(例子1)
1、创建项目
scrapy startproject renren---cd renren--创建爬虫scrapy genspider spider renren.com
2、改写settings.py
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for renren project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # https://doc.scrapy.org/en/latest/topics/settings.html 9 # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'renren' 13 14 SPIDER_MODULES = ['renren.spiders'] 15 NEWSPIDER_MODULE = 'renren.spiders' 16 17 18 # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 #USER_AGENT = 'renren (+http://www.yourdomain.com)' 20 21 # Obey robots.txt rules 22 ROBOTSTXT_OBEY = False 23 24 # Configure maximum concurrent requests performed by Scrapy (default: 16) 25 #CONCURRENT_REQUESTS = 32 26 27 # Configure a delay for requests for the same website (default: 0) 28 # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 29 # See also autothrottle settings and docs 30 DOWNLOAD_DELAY = 1 31 # The download delay setting will honor only one of: 32 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 33 #CONCURRENT_REQUESTS_PER_IP = 16 34 35 # Disable cookies (enabled by default) 36 #COOKIES_ENABLED = False 37 38 # Disable Telnet Console (enabled by default) 39 #TELNETCONSOLE_ENABLED = False 40 41 # Override the default request headers: 42 DEFAULT_REQUEST_HEADERS = { 43 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 44 'Accept-Language': 'en', 45 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36', 46 47 48 } 49 50 # Enable or disable spider middlewares 51 # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html 52 #SPIDER_MIDDLEWARES = { 53 # 'renren.middlewares.RenrenSpiderMiddleware': 543, 54 #} 55 56 # Enable or disable downloader middlewares 57 # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 58 #DOWNLOADER_MIDDLEWARES = { 59 # 'renren.middlewares.RenrenDownloaderMiddleware': 543, 60 #} 61 62 # Enable or disable extensions 63 # See https://doc.scrapy.org/en/latest/topics/extensions.html 64 #EXTENSIONS = { 65 # 'scrapy.extensions.telnet.TelnetConsole': None, 66 #} 67 68 # Configure item pipelines 69 # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 70 #ITEM_PIPELINES = { 71 # 'renren.pipelines.RenrenPipeline': 300, 72 #} 73 74 # Enable and configure the AutoThrottle extension (disabled by default) 75 # See https://doc.scrapy.org/en/latest/topics/autothrottle.html 76 #AUTOTHROTTLE_ENABLED = True 77 # The initial download delay 78 #AUTOTHROTTLE_START_DELAY = 5 79 # The maximum download delay to be set in case of high latencies 80 #AUTOTHROTTLE_MAX_DELAY = 60 81 # The average number of requests Scrapy should be sending in parallel to 82 # each remote server 83 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 84 # Enable showing throttling stats for every response received: 85 #AUTOTHROTTLE_DEBUG = False 86 87 # Enable and configure HTTP caching (disabled by default) 88 # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 89 #HTTPCACHE_ENABLED = True 90 #HTTPCACHE_EXPIRATION_SECS = 0 91 #HTTPCACHE_DIR = 'httpcache' 92 #HTTPCACHE_IGNORE_HTTP_CODES = [] 93 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
3、改写spider.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class SpiderSpider(scrapy.Spider): 6 name = 'spider' 7 allowed_domains = ['renren.com'] 8 start_urls = ['http://renren.com/'] 9 10 11 def start_requests(self): 12 url = 'http://www.renren.com/PLogin.do' 13 data = { 14 'email':'827832075@qq.com', 15 'password':'56571218lu', 16 } #构造表单数据 17 request = scrapy.FormRequest(url ,formdata=data, callback=self.parse_page) 18 yield request 19 20 def parse_page(self,response): 21 url2 = 'http://www.renren.com/880792860/profile' 22 request = scrapy.Request(url2 ,callback=self.parse_profile) 23 yield request 24 25 def parse_profile(self,response): 26 with open('baobeier.html','w',encoding='utf-8') as f: 写入文件 27 f.write(response.text) 28 f.close()
4、运行爬虫
1 #author: "xian" 2 #date: 2018/6/13 3 from scrapy import cmdline 4 cmdline.execute('scrapy crawl spider'.split())
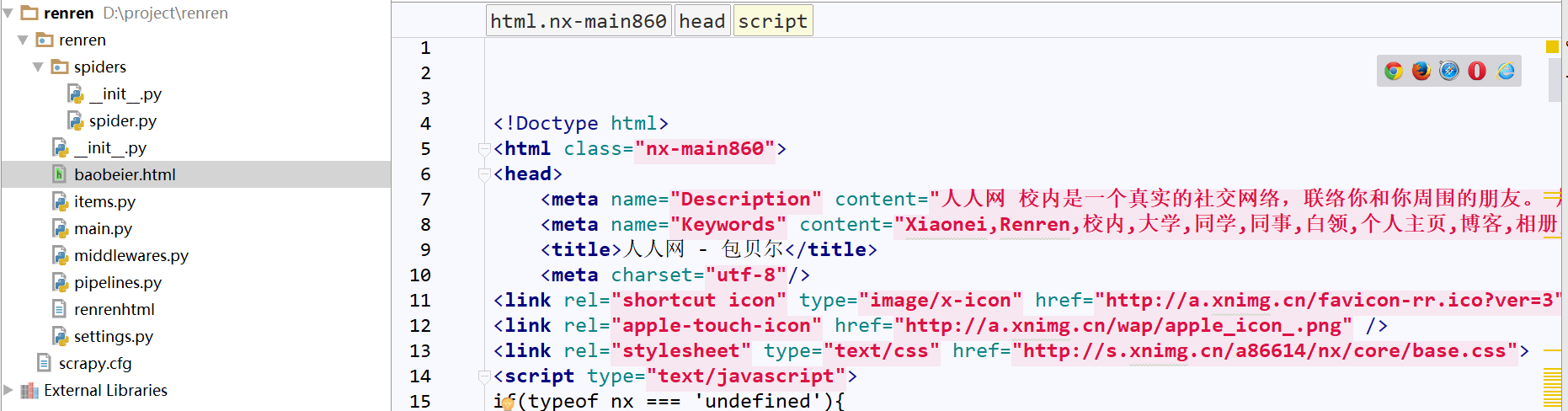
5、效果展示(我们成功登录并爬取了包贝儿的人人主页)
(3)、使用阿里云验证码服务自动识别验证码(服务地址:https://market.aliyun.com/products/57126001/cmapi014396.html#sku=yuncode=839600006)
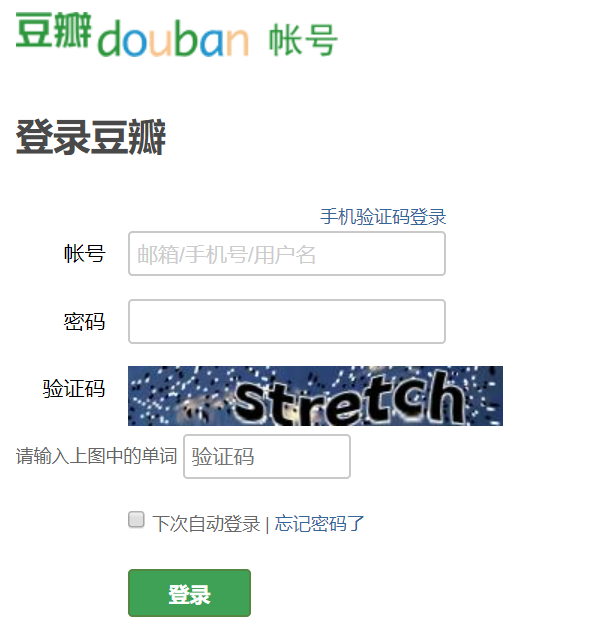
测试服务:我们同样使用豆瓣登录页面的验证码进行测试:
1 #author: "xian" 2 #date: 2018/6/13 3 from urllib import request 4 from base64 import b64encode 5 import requests 6 7 captcha_url = 'https://www.douban.com/misc/captcha?id=oL8chJoRiCTIikzwtEECZNGH:en&size=s' 8 9 request.urlretrieve(captcha_url ,'captcha.png') 10 11 recognize_url = 'http://jisuyzmsb.market.alicloudapi.com/captcha/recognize?type=e' 12 13 formdata = {} 14 with open('captcha.png','rb') as f: 15 data = f.read() 16 pic = b64encode(data) 17 formdata['pic'] = pic 18 19 appcode = '614a1376aa4340b7a159d551d4eb0179' 20 headers = { 21 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', 22 'Authorization':'APPCODE ' + appcode, 23 } 24 25 response = requests.post(recognize_url,data = formdata,headers =headers) 26 print(response.json()) #返回json格式
运行效果展示:(我们借助阿里云平台成功进行了验证码的自动识别)

(4)、使用阿里云服务进行验证码验证并模拟登录豆瓣网
1、创建项目scrapy startproject douban---cd douban---创建爬虫scrapy genspider spider doubao.com(树形目录如下:)
改写settings.py
不遵循robots协议

设置请求头
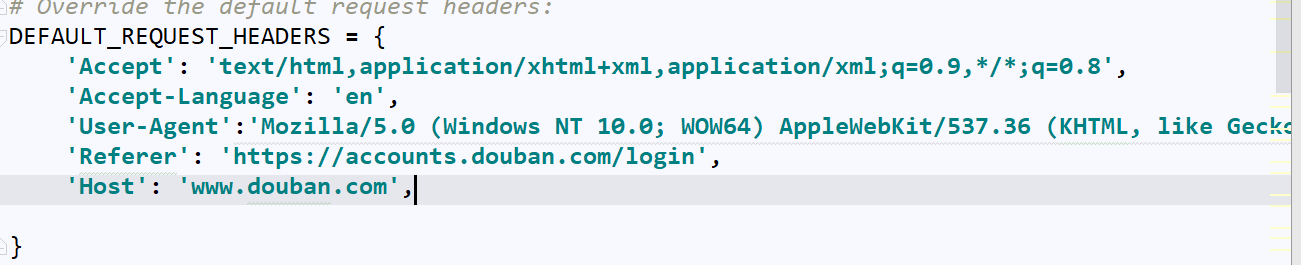
设置爬取时间间隔

改写spider.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from urllib import request 4 from PIL import Image #导入识别图形的库 5 from base64 import b64encode #导入b64编码库 6 import requests 7 8 9 class SpiderSpider(scrapy.Spider): 10 name = 'spider' 11 allowed_domains = ['douban.com'] 12 start_urls = ['https://accounts.douban.com/login'] #起始url 13 login_url = 'https://accounts.douban.com/login' #登录界面url 14 profile_url = 'https://www.douban.com/people/179834288/' #个人主要url 15 editsignature_url = 'https://www.douban.com/j/people/179834288/edit_signature' #编辑签名的接口url 16 17 def parse(self, response): 18 formdata = { 19 'source': 'None', 20 'redir':'https://www.douban.com', 21 'form_email': '827832075@qq.com', 22 'form_password': '56571218lu', 23 'remember': 'on', 24 'login': '登录', 25 26 } #传入部分表单数据 27 captcha_url = response.css('img#captcha_image::attr(src)').get() #获取验证码 28 if captcha_url: #判断是否存在验证码 29 captcha = self.regonize_captcha(captcha_url) #识别验证码 30 formdata['captcha-solution'] = captcha #获取captcha-solution表单字段 31 captcha_id = response.xpath('//input[@name = "captcha-id"]/@value').get() #获取captcha_id表单字段 32 formdata['captcha-id'] = captcha_id 33 yield scrapy.FormRequest(url = self.login_url,formdata=formdata,callback=self.parse_after_login) #提交表单数据 34 35 36 def parse_after_login(self,response): #解析登录页面函数 37 if response.url == 'https://www.douban.com': #判断是否登录成功 38 yield scrapy.Request(self.profile_url,callback=self.parse_profile) #如果登录成功向个人主页发送请求并回调解析函数 39 print('登录成功!') 40 else: 41 print('登录失败!') 42 43 def parse_profile(self,response): #解析个人主页函数 44 print(response.url) 45 if response.url == self.profile_url: #判断是否成功到达个人主页 46 ck = response.xpath('//input[@name = "ck"]/@value').get() #获取ck value的值 47 formdata = { 48 'ck': ck, 49 'signature':'积土成山,风雨兴焉!', 50 } #构造表单数据 51 yield scrapy.FormRequest(self.editsignature_url,formdata=formdata,callback=self.parse_None) 提交表单数据,最后callback 指定回调函数,这里如果不指定回调函数默认回调parse,最后会出现登录失败信息 52 else: 53 print('进入个人中心失败了!') 54 55 def parse_None(self,response): 56 pass 57 58 59 #部分为人工验证码识别登录方式 60 # def regonize_captcha(self,image_url): 61 # request.urlretrieve(image_url,'captcha.png') 62 # image = Image.open('captcha.png') 63 # image.show() 64 # captcha = input('请您输入验证码:') 65 # return captcha 66 67 def regonize_captcha(self, image_url): #这里使用上面的阿里云服务识别验证码,参考阿里云上提供的使用手册即可 68 captcha_url = image_url 69 70 request.urlretrieve(captcha_url, 'captcha.png') 71 72 recognize_url = 'http://jisuyzmsb.market.alicloudapi.com/captcha/recognize?type=e' 73 74 formdata = {} 75 with open('captcha.png', 'rb') as f: 76 data = f.read() 77 pic = b64encode(data) 78 formdata['pic'] = pic 79 80 appcode = '614a1376aa4340b7a159d551d4eb0179' 81 headers = { 82 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 83 'Authorization': 'APPCODE ' + appcode, 84 } 85 86 response = requests.post(recognize_url, data=formdata, headers=headers) 87 result = response.json() 88 code = result['result']['code'] 89 return code
最后运行爬虫项目:
新建一个main.py方便调试
1 #author: "xian" 2 #date: 2018/6/13 3 from scrapy import cmdline 4 cmdline.execute('scrapy crawl spider'.split())
运行结果:(部分)

我们可以看到我的主页的个性签名已经改变为我们设置的了!(程序成功运行了!)

(5)、总结
1、在scrapy中想要发送Post请求,推荐使用scrapy.FormRequest方法,并指定表单数据
2、在爬虫开始时发送Post请求,请重写start_requests()方法