为了实现远程kafka通信,我可谓是呕心沥血。期间各种bug各种调,太煎熬了 (T.T)
介绍:
我用一台虚拟机作为远程消息的发送方,用本地电脑主机作为消息的接收方
虚拟机:安装java,kafka,zookeeper
主机:eclipse,注意我没有说在主机上也要安装kafka的
1、虚拟机部署
1)下载kafka_2.11-2.2.0 我用的最新的(当前)
2)解压到 /usr/local/ ,注意切换都root,不然后面编辑不了文件
3)配置文件 kafka/config/server.properties 只用修改下面三个

稍微解释下:上面的ip都是一个,都是虚拟机ip,修改后可以在本机接收消息也可以在远程(本地电脑或者其他电脑接收)
不知道虚拟机ip? 在命令行下 敲 ifconfig就可以找到了
2、本地eclipse
1)新建maven工程
pom.xml 注意里面的kafka版本最好和远程对应(其他版本有可能发生错误,收不到消息)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>hadoop</groupId> <artifactId>eclipseandmaven</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>eclipseandmaven</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka-client</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> <!-- 本地测试注释集群运行打开 --> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> </dependencies> </project>
建立 MainTopology.java
import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.StormSubmitter; import org.apache.storm.kafka.spout.KafkaSpout; import org.apache.storm.kafka.spout.KafkaSpoutConfig; import org.apache.storm.topology.TopologyBuilder; public class MainTopology { public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); //ip设置为虚拟机ip,后面的topic要和虚拟机上的一样 KafkaSpoutConfig.Builder<String, String> kafkaBuilder = KafkaSpoutConfig.builder("192.168.83.133:9092","test561");// 设置kafka属于哪个组 kafkaBuilder.setGroupId("testgroup"); // 创建kafkaspoutConfig KafkaSpoutConfig<String, String> build = kafkaBuilder.build(); // 通过kafkaspoutConfig获得kafkaspout KafkaSpout<String, String> kafkaSpout = new KafkaSpout<String, String>(build); // 设置5个线程接收数据 builder.setSpout("kafkaSpout", kafkaSpout, 5); // 设置2个线程处理数据 builder.setBolt("printBolt", new PrintBolt(), 2).localOrShuffleGrouping("kafkaSpout"); Config config = new Config(); if (args.length > 0) { // 集群提交模式 config.setDebug(false); StormSubmitter.submitTopology(args[0], config, builder.createTopology()); } else { // 本地测试模式 config.setDebug(true); // 设置2个进程 config.setNumWorkers(2); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("kafkaSpout", config, builder.createTopology()); } } }
建立 PrintBolt.java
import org.apache.storm.topology.BasicOutputCollector; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseBasicBolt; import org.apache.storm.tuple.Tuple; public class PrintBolt extends BaseBasicBolt { /** * execute会被storm一直调用 * * @param tuple * @param basicOutputCollector */ public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { // 为了便于查看消息用err标红 System.err.println(tuple.getValue(4)); System.err.println(tuple.getValues()); } public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } }
3、运行
切换到kafka安装目录
1)启动zookeeper
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
2)启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
3)创建生产者
bin/kafka-console-producer.sh --broker-list 192.168.83.133:9092 --topic test561
4)创建消费者
bin/kafka-console-consumer.sh --bootstrap-server 192.168.83.133:9092 --topic test561 --from-beginning
5)启动本地eclipse项目
6)在3)中的窗口发送字符串
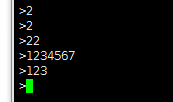
7)4)中可以收到消息,同时本地也可以收到消息


4、问题罗列
1)再次使用发现启动不了------杀进程
ps -ef | grep kafka kill -9 kafka的pid ps -ef | grep zookeeper kill -9 zookeeper的pid
2)收不到消息是不是防火墙的原因
进行远程telnet测试(如果不报错就可以用,不用改动什么了,否则要把虚拟机防火墙关闭或者开放端口 下面有连接 )
telnet 192.168.83.133 9092
3)自己安装的zookeeper和kafka自带的不能混用
我自己安装了一个然后还设置了自启动,然后每次运行kafka自带的zookeeper时总是启动不了消费者。。。。。。
之后我把它删了只用kafka自带的就可以了。
4)jdk版本不适合
java版本我原先用的openjdk1.7,后来重新下载了一个jdk1.8安装的,
然后下载时要登录,就找了一个(谢谢共享)
name:2696671285@qq.com
pwd:Oracle123
5)还有。。。到以后再总结吧
参考:
https://blog.csdn.net/luozhonghua2014/article/details/80369469?utm_source=blogxgwz5
https://blog.csdn.net/wxgxgp/article/details/85701844
防火墙: