1.需要会的基础命令
(1)cd 切换目标目录
(2)ls 列举出当前目录下所有的文件
(3)tar 解压文件 【 tar -zxvf jdk-8u131-linux-x64.tar.gz】v显示解压具体信息可有可无
(4)cp 复制文件【cp newFileName usedFileName】
(5)vi 进入编辑模式,当没有这个文件,将进行自动创建在进入编辑,【vi /etc/profile】
(6)pwd 显示当前目录的绝对路径
(7)sourse 更新修改后的文件【sourse /etc/profile】
(8) rm 删除文件 【 rm jdk-8u131-linux-x64.tar.gz】
2.上传,解压,到指定目录【我的jdk,hadoop地址为/home/Hadoop/software/】
(1)创建用户 解压文件【解压上传到software】--------删除创建用户可查看https://blog.csdn.net/li_101357/article/details/69367457
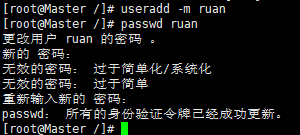
①创建用户(在root用户下) ruan用户 密码****** 【创建用户useradd -m username】【设置密码passwd ruan】【删除用户userdel -r username】
②Hadoop下创建文件夹software 【mkdir software】

③使用xshell6连接到Hadoop用户,再将文件和上传和解压到当前目录(software)下
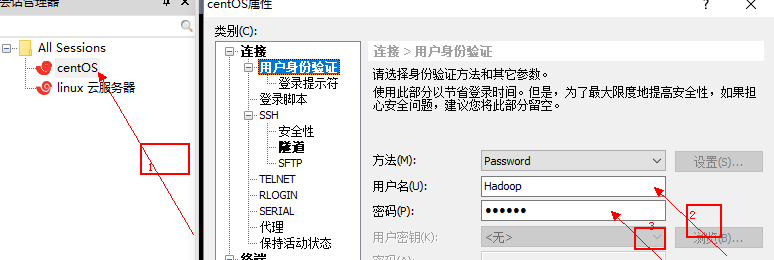
④上传压缩文件hadoop-2.6.5.tar.gz jdk-8u131-linux-x64.tar.gz【如一图】 文件到sofware【解压 tar -zxvf jdk-8u131-linux-x64.tar.gz】【如图二】 删除原压缩文件【如图三】

图一

图二

图三
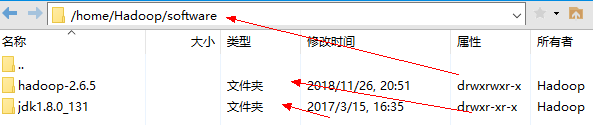
⑤目录如下

3..环境配置文件 jdk(java) hadoop (橘黄色字体为当前我的目录下的jdk,hadoop地址)自行修改
(1)配置文件夹
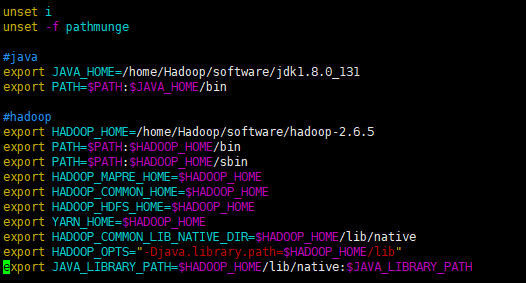
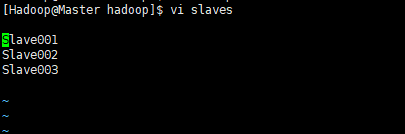
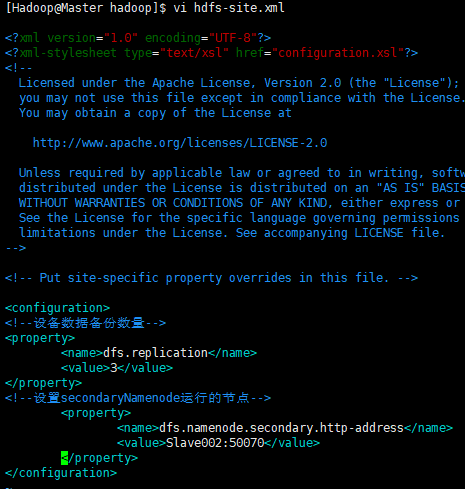
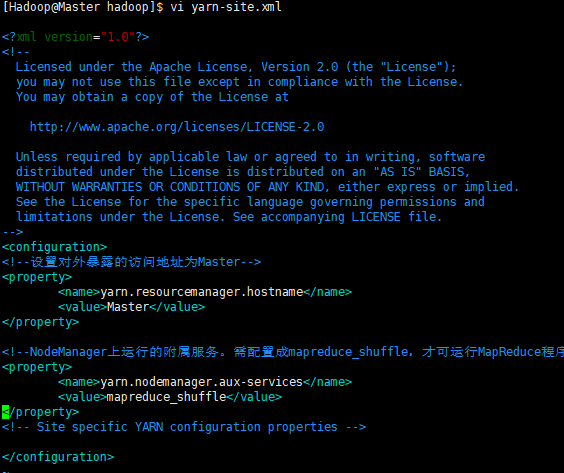
① 配置jdk(java)环境变量 #java export JAVA_HOME=/home/Hadoop/software/jdk1.8.0_131 export PATH=$PATH:$JAVA_HOME/bin ② 配置hadoop环境变量 #hadoop export HADOOP_HOME=/home/Hadoop/software/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRE_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH ③ 配置core-site.xml <!--指定HDFS存储入口--> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <!--指定hadoop临时目录--> <property> <name>hadoop.tmp.dir</name> <value>/home/Hadoop/software/hadoop-2.6.5/tmp</value> </property> ④ 配置hadoop-env.sh /home/Hadoop/software/jdk1.7.0_131 ⑤ 配置slaves Slave001 Slave002 Slave003 ⑥ 配置hdfs-site.xml <!--设备数据备份数量--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--设置secondaryNamenode运行的节点--> <property> <name>dfs.namenode.secondary.http-address</name> <value>Slave002:50070</value> </property> ⑦ 配置 mapred-site.xml.template <!--配置mapreduce框架用yarn启动--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> ⑧ 配置 yarn-site.xml <!--设置对外暴露的访问地址为Master--> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- Site specific YARN configuration properties -->
(2)到达hadoop根目录下修改配置文件

①配置jdk(java)环境 and hadoop 环境 在/etc/profile 文件最下方添加①②段代码

③配置core-site.xml 添加到 <configuration></configuration>标签中


④配置hadoop-env.sh


⑤配置slaves
⑥配置hdfs-site.xml
⑦配置 mapred-site.xml.template

⑧配置 yarn-site.xml
4. hdfs namenode -format格式化集群(切换到用户)
(1)若提示文件不存在,请检测jdk版本(图形化界面自带jdk可能版本不同请参照进行修改 https://blog.csdn.net/u011364306/article/details/48375653#commentBox),
5.检测是否成功 但有tmp 文件表示配置成功

①②③④⑤⑥⑦⑧