期中总结
第一周、linux常用命令回顾
man -k:
用户可以通过执行 man 命令调用手册页。示例:
你可以使用如下方式来获得某个命令的说明和使用方式的详细介绍:
$ man <command_name>
比如你想查看 man 命令本身的使用方式,你可以输入:
man man
要查看相应区段的内容,就在 man 后面加上相应区段的数字即可,如:
$ man 3 printf
cheat:
cheat是非常好用的“打小抄”搜索工具,能够方便的告诉你你想要的内容。
grep -nr
grep命令是很强大的,也是相当常用的一个命令,它结合正则表达式可以实现很复杂却很高效的匹配和查找.
第二周、linux常用工具
vim:
1.vim编辑器的三种模式
Ⅰ正常模式:(按Esc或Ctrl+[进入) 左下角显示文件名或为空
Ⅱ插入模式:(按i键进入) 左下角显示--INSERT--
Ⅲ可视模式:左下角显示—VISUAL
2、vim的一些基本操作
Ⅰ、游标移动:
在进入vim后,按下i键进入插入模式。在该模式下您可以输入文本信息,下面请输入如下三行信息:
12345678
abcdefghijk
shiyanlou.com
按Esc进入普通模式,在该模式下使用方向键或者h,j,k,l键可以移动游标。
|
按键 |
说明 |
|
h |
左 |
|
l |
右(小写L) |
|
j |
下 |
|
k |
上 |
|
w |
移动到下一个单词 |
|
b |
移动到上一个单词 |
请尝试在普通模式下使用方向键移动光标到shiyanlou这几个字母上面
Ⅱ.插入模式
在普通模式下使用下面的键将进入插入模式,并可以从相应的位置开始输入
|
命令 |
说明 |
|
i |
在当前光标处进行编辑 |
|
I |
在行首插入 |
|
A |
在行末插入 |
|
a |
在光标后插入编辑 |
|
o |
在当前行后插入一个新行 |
|
O |
在当前行前插入一个新行 |
|
cw |
替换从光标所在位置后到一个单词结尾的字符 |
请尝试不同的从普通模式进入插入模式的方法,在最后一行shiyanlou前面加上www.,注意每次要先回到普通模式才能切换成以不同的方式进入插入模式
vim的按键图
gcc:
使用GCC的四个步骤
预处理:gcc –E hello.c –o hello.i;gcc –E调用cpp
编 译:gcc –S hello.i –o hello.s;gcc –S调用ccl
汇 编:gcc –c hello.s –o hello.o;gcc -c 调用as
链 接:gcc hello.o –o hello ;gcc -o 调用ld
GCC支持的文件类型
gdb:
$gdb
这样可以和gdb进行交互了。
*启动gdb,并且分屏显示源代码:
$gdb -tui
这样,使用了'-tui'选项,启动可以直接将屏幕分成两个部分,上面显示源代码,比用list方便多了。这时候使用上下方向键可以查看源代码,想要命令行使用上下键就用[Ctrl]n和[Ctrl]p.
*启动程序之后,再用gdb调试:
$gdb
这里,是程序的可执行文件名,是要调试程序的PID.如果你的程序是一个服务程序,那么你可以指定这个服务程序运行时的进程ID。gdb会自动attach上去,并调试他。program应该在PATH环境变量中搜索得到。
*启动程序之后,再启动gdb调试:
$gdb
这里,程序是一个服务程序,那么你可以指定这个服务程序运行时的进程ID,是要调试程序的PID.这样gdb就附加到程序上了,但是现在还没法查看源代码,用file命令指明可执行文件就可以显示源代码了。
*重新运行调试的程序:
(gdb) run
要想运行准备调试的程序,可使用run命令,在它后面可以跟随发给该程序的任何参数,包括标准输入和标准输出说明符(<和> )和shell通配符(*、?、[、])在内。
Make和Makefile
这是实现自动化编译的好方法。
Makefile的一般写法:
一个Makefile文件主要含有一系列的规则,每条规则包含以下内容:
- 需要由make工具创建的目标体,通常是可执行文件和目标文件,也可以是要执行的动作,如‘clean’;
- 要创建的目标体所依赖的文件,通常是编译目标文件所需要的其他文件。
- 创建每个目标体时需要运行的命令,这一行必须以制表符TAB开头
第三周、信息的表示和处理
信息存储
计算机最小的可寻址的存储器单位——字节
数据大小
在不同字长的计算机中,相同的数据类型所占用的字节数并不相同,32位和64位的区别参见教材26页表格。
gcc -m32可以在64位机上生成32位的代码
表示字符串和表示代码
字符串
c语言中字符串被编码成为一个以null(值为0)字符结尾的字符数组。多使用ASCII字符码。
在使用ASCII字符码的任何系统上都能得到相同的结果,与字节顺序和字大小规则无关,所以文本数据比二进制数据具有更强的平台独立性。
代码
二进制代码在不同的操作系统上有不同的编码规则。所以二进制代码是不兼容的。
3.位级运算
位运算:位向量按位进行逻辑运算,结果仍是位向量(区别于逻辑运算)
※常见用法:掩码——用来选择性的屏蔽信号
掩码是一个位模式,表示从一个字中选出的位的集合。
用位向量给集合编码,通过指定掩码来有选择的屏蔽或者不屏蔽一些信号,比如
某一位位置上为1时,表明信号i是有效的;0表示该信号被屏蔽。
逻辑运算
逻辑运算符
与:&&
或:||
非:!
逻辑运算的计算方法:
所有非零参数都代表TRUE,0参数代表FALSE
逻辑运算的结果:
1-代表TRUE,或者,0-代表FALSE
1c语言中的移位运算
右移分为逻辑右移和算术右移。(其实左移也区分,但是算术左移和逻辑左移没有什么区别)
逻辑右移:
在左端补k个0,多用于无符号数移位运算
算术右移:
在左端补k个最高有效位的值,多用于有符号数移位运算。
整型数据类型
整型数据类型——表示有限范围的整数,每种类型都能用关键字来指定大小,还可以指定是非负数(unsigned)还是负数(默认)。这些不同大小的分配的字数会根据机器的字长和编译器有所不同。
整数运算
——实际上这是一种模运算。
无符号运算
无符号运算本质上就是模运算,mod 2的w次幂。
浮点数
浮点表示对形如V=x X (2^y)的有理数进行编码,适用于:
非常大的数字
非常接近于0的数字
作为实数运算的近似值
第四周、处理器体系结构
一、概述
1、现代微处理器可以称得上人类创造的最复杂的系统之一
2、一个处理器支持的指令和指令的字节级编码称为它的指令级体系结构
二、Y86指令集体系结构
简易图示
三、逻辑设计和硬件控制语言HCL
1、逻辑门
AND:&&
OR:||
NOT:!
2、组合电路和布尔表达式
*两个或多个逻辑门的输出不能连接在一起,否则可能会使线上的信号矛盾,导致一个不合法的电压或电路故障
*网必须无环
3、字级的组合电路和HCL整数表达式
*P245图
一些位级信号代表一个整数或一些控制模式。执行字级计算的组合电路根据输入字的各个位,用逻辑门来计算输出字的各个位。
4、集合关系
判断集合关系的通用格式:
Iexpr in {iexpr1,iexpr2,…,iexprk}
5、存储器和时钟
组合电路从本质上讲,不存储任何信息。只响应输入产生输出。
时序电路:有状态并且在这个状态上进行计算的系统。
时钟寄存器:存储单个位或者字。时钟信号控制寄存器加载输入值。
随机访问存储器:存储多个字,用地址选择该读写哪个字:
(1) 处理器的虚拟存储器系统
(2) 寄存器文件
Y86处理器会用时钟寄存器保存程序计数器(PC),条件代码(CC)和程序状态(Stat)。
寄存器文件有两个读端口和一个写端口。
四、Y86的顺序实现
1、 将处理组织成阶段
下面是关于各个阶段以及各阶段内执行操作的简略描述:
· 取指:取指阶段从存储器读取指令字节,地址为程序计数器(PC)的值。
· 译码:译码阶段从寄存器文件读入最多两个操作数,得到val A/val B.
· 执行:执行阶段,算术/逻辑单元要么执行指令明确的操作(根据ifun的值),计算存储器引用的有效地址,要么增加或减少栈指针。得到的值称为valE
· 访存:访存阶段可将数据写入存储器或从存储器读出数据
· 写回:最多可写两个结果到存储器。
· 更新PC:将PC设置成下一指令的地址。
·
第五周、处理器体系结构
随机访问存储器分为两类:静态和动态
1、静态RAM
静态RAM 的基本存储电路为触发器,每个触发器存放一位二进制信息,由若干个触发器组成一个存储单元,再由若干存储单元组成存储器矩阵,加上地址译码器和读/写控制电路就组成静态RAM。但由于静态RAM 是通过有源电路来保持存储器中的数据,因此,要消耗较多功率,价格也较高。
2、动态RAM
每一个比特的数据都只需一个电容跟一个晶体管来处理,相比之下在SRAM上一个比特通常需要六个晶体管。正因这缘故,DRAM拥有非常高的密度,单位体积的容量较高因此成本较低。但相反的,DRAM也有访问速度较慢,耗电量较大的缺点。
局部性
1、局部性原理: CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
2、三种不同类型的局部性:时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。程序循环、堆栈等是产生时间局部性的原因。空间局部性(Spatial Locality):在最近的将来将用到的信息很可能与现在正在使用的信息在空间地址上是临近的。顺序局部性(Order Locality):在典型程序中,除转移类指令外,大部分指令是顺序进行的。顺序执行和非顺序执行的比例大致是5:1。此外,对大型数组访问也是顺序的。指令的顺序执行、数组的连续存放等是产生顺序局部性的原因
6.3 存储器层次结构
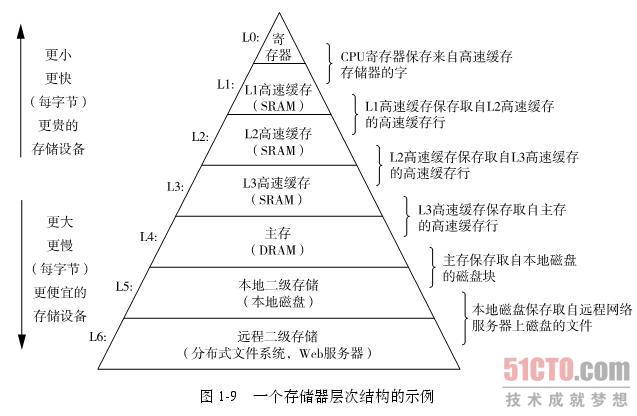
1、缓存命中
若需要访问k+1层里的数据块d,如果d已经缓存在第k层,则称缓存命中。这样从第k层取块d要比k+1层更块。
2、缓存不命中
若d不在第k层,则是缓存不命中,此时将k+1层存储中取出块d,放入k层。可能需要替换掉k层中已有的块。替换策略是:随机,最近最少使用等。
需要有个东西对缓存进行管理,比如怎么进行块的划分,各层次间怎么传送块,判断是否命中,不命中该如何处理,写回数据的时候该如何处理。
都是需要考虑的问题,可用硬件管理如cache,也可用软件管理如虚拟内存。
3、缓存的管理
i)相关假定
假定存储器的地址有m位,便有M=2m 不同地址。
一个缓存被分成S=2s个的高速缓存组(cache set),
每个组包含 E 个高速缓存行。
每个缓存行由一个B=2b字节的数据块,一个有效位,t=m-(b+s)个标记位组成。
一个高速缓冲区的大小C = S * E * B。
ii)如何访问缓存
当要访问存储器中的一个字节时,给出的访问地址的m位中,前t位表示标记位,中间s位为组索引,最后b位为块偏移。
iii)缓存不命中时
当缓存不命中时,则若需要将存储器中的块放入缓存对应的组中。
若组中的行都有数据,则需要进行替换,替换策略是:LFU或这LRU(不想细说了)
iv)三种缓存方式的划分
分为直接映射高速缓存,组相联高速缓存,全相联高速缓存
若指定了S,E,B的值,则缓存的划分方式就已经确定了。
缓存块与存储块之间也就建立了一种映射关系。
参考资料:1、《深入理解计算机系统》课本第一章到第七章
2、本人之前的博客
收获:这个学期学习的深入理解计算机系统这门课和之前我们上的课有着极大的不同,这门课主要的学习方式是课下自学然乎课上进行考试。这样一来有助于调动我们课下学习的积极性,二来也可以检测我们的学习状况。也让我们真正对计算机系统有了了解,包括存储器结构,操作系统,数据的存储,虚拟机的使用等等。
而这门课真正的意义在于让我们养成了一种下课学习的习惯,之前我们的学习模式大多是上课听,下课不复习,期末熬夜看,这样不仅没有学到知识,而且还伤害身体。而现在,我了解了平时学习的重要性,不只是这门课,其余的课程我也进行了课后的复习,每节课知识量不大,不需要花费特别多时间,但是效果却很好。希望在以后的学习中能够延续这种方法。争取在大学期间真正学到知识。
不足:由于之前学习方法的不正确,导致基础比较薄弱,所以在老师布置任务以后,觉得任务量太大,因为总是需要补充之前的知识。所以有的时候会产生厌烦的情绪,导致学习效率有些低下。由于现在的学习,让我的基础有了提高,再加上自己适应了这种教学模式,所以以后应该不会再出现这种问题。还有就是对知识点没有深入地了解,知识掌握同学和老师的讲解,没有深入到内核中,了解这个知识点的背景,和深刻的内涵。以后要继续加强对知识点的深入理解,可以利用百度,博客园提问等方式,弄清楚深层的问题,这样也算是真正的理解。