http://www.kunli.info/2009/07/02/dynamic-model-solution-1/
动态模型的应用在移动计算中可谓日渐繁荣,不管是从传统领域转移过来的识别,智能控制等领域,还是新兴的情景信息利用,都需要对动态模型应用的掌握。正好下一个项目可能会用到通过动态模型做机器识别的算法,就在这里整理一下以前的课程和看的paper获得的知识。
这个上篇不会具体介绍算法,而是先大致介绍一下线性和非线性模型,然后从大方向上介绍一下解线性模型的一些常用方法。等下一次有一段连续空闲时间的时候,我准备将这几种常用方法的详细介绍和比较写成下篇。非线性模型解法的数学推导过于复杂,我也不用,就不准备说了。
既然要介绍,就得先说说什么是动态模型。动态模型, 通常被用于针对系统的一个时间段的状态来进行表示和建模,它可以是连续的,比如以马尔可夫为解决方案代表的,也可以是离散的,比如以卡曼滤波器为解决方案代表的。当然在移动计算的应用领域,我们通常都是关注的离散状态。
线性动态模型
下图就是一个普通的动态模型示例,其中的X表示观察态,就是说在这些时间段内系统呈现出来的状态,也就是我们所说的这个系统发生的event。y就 是没有被观察到的隐藏状态,需要你自己去推断或者系统预测的。系统的特性主要体现在两个方面,一个是状态转移概率P(Y(t+1)|Y(t)), 一个是状态观察概率P(X(t)|Y(t))。
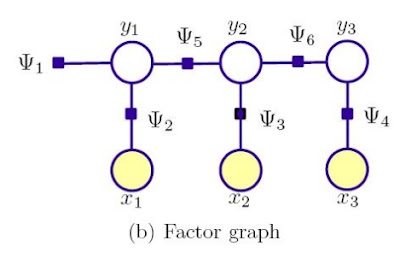
建立这个动态模型的主要目的呢,就是为了预测下一个可能发生的事件状态。要预测事件,首先我们可以基于所有的观察量X,对隐藏状态Y维护一个后验概率分布。例如,基于在t时间时所有的观察量X1到Xt,后验分布能通过如下公式来进行计算:
然后未来的事件X(t+1) …… X(t+k),在X1到Xt已经发生的前提下,都能通过上面这个后验概率计算
这样计算的好处是什么呢?所有X1到Xt这些已经观察到的事件所包含的所有信息,都能被Y(t+1)这个相对较小的隐藏态所捕获,因此,在预测未来事件的时候,我们不需要用到所有的观察事件X1到Xt,只需要有它们的状态表达Y(t+1)即可。
对于线性模型来讲,这种后验更新准则比较简单,一旦模型的参数被正确估计,这种模型就能很稳定地用于预测中。解线性模型的方法很多,马尔可夫一系列 变种算法,很多情况下意想不到万能的朴素贝叶斯,Conditional Random Fields算法,以及最大熵模型等。本文最后一节会有详细的分类介绍。
非线性动态模型
总的来说,线性模型的处理是相对简单的。举个例子,一个典型的通信系统,如果是线性的,就太简单了,假设系统噪声是正态分布,系统要做的就是把一个 正态分布的变量信号映射到另一个不同的,但是很容易确定的正态分布变量信号上。因为既然大家都是正态的,那么绝大部分计算就是关于相关正态分布均值和协方 差的确定而已,最初的卡曼滤波器很大程度上就是基于这种思想。
然而,现实中有很多模型的动态参数是不能被简单线性归纳的,在这个时候,非线性就必须被考虑进动态系统中。下面公式所表示的系统就是一个典型的非线 性离散系统,其中,x(k)是输入,x(k+1)是输出,F是非线性加权函数,f是非线性函数。既然x(k+1)是由x(k)非线性决定的了,那么 y(k+1)自然也就是以非线性形式存在的了。至于u和d都是噪声表示,可以不用理会。
和线性动态模型一样,我们为了预测未来事件,必须对过去的观察信息进行总结,形成中间态。要达到这样的目的,常用方法是通过非线性概率建模。目前存在的算法都有一定的局限性,包括
- 隐马尔可夫模型家族(各种变种)。这玩意线性能用,非线性也有变种算法,但容易受到局部最小的困然,因为在某些情况下要用EM(expectation-maximization)来求局部似然极值。而且通常都需要观察量的事先定义。
- 卡曼滤波和粒子滤波。这两兄弟太参数化了。随便找一找particle filter的paper就知道,推导让人超级头大。必须事先指定很多信息。
- 动态贝叶斯网络。刚说的马尔可夫就是最简单的动态bayes网络。这东西也需要大量的事先设定,计算也麻烦。通俗点说,无论是马尔可夫还是贝叶斯,事先都得通过训练来知道各个状态之间相关的概率。representational rather than computational这篇论文详细阐述了关于动态贝叶斯的一些问题。
线性模型解法分类
上面提到过在解线性动态模型的时候,四种代表方法。前两者属于generative model,后两者属于discriminative model。这两分类有啥区别呢?
对于generative model来讲,关注的是如何找到最佳分布模型来生成观察特征,也就是说,给你一个观察特征变量x,一个目标特征变量(label)y,generative model会去寻找最大化他们之间的联合概率密度分布P(x,y)。generative model是针对所有变量的全概率模型。
而discriminative model呢,则只关注目标变量条件于观察变量的概率模型,寻找观察变量和特征变量之间的联系。而它的结论也只和条件概率密度有关。通俗点说,它就是想找在有观察特征x的情况下,P(y|x)的最大值。抛开动态模型这个主题不谈,discriminative这个家族还是很强大的,除了刚才提到的两个算法系列,还包括了SVM(支持向量机),boosting,神经网络等。
综合来看,discriminative模型只需要对目标变量基于观察变量的条件概率进行采样,而generative模型则需要多得多的参数来建模,也需要更多关于特征值独立的假设。想想,你得枚举所有的观察变量,对于一个大系统而言,这是多么可怕的任务量。
上面说的四种算法模型,分别都是generative和discriminative model的代表。如果想仔细介绍的话,这篇文章不知道多长了,所以我现在这里放一张它们之间的关系转换图,下次有时间,以比较新的CRF为引子,详细介绍它们的区别和联系。
××××××××××××××××××××××××××××××
系列链接: