1.单机(非分布式)模式
这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统,一般仅用于本地MR程序的调试。
默认情况下,Hadoop即处于该模式,用于开发和调式。
1. 不对配置文件进行修改。
2. 使用本地文件系统,而不是分布式文件系统。
3. Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
4. 用于对MapReduce程序的逻辑进行调试,确保程序的正确。
2.伪分布式运行模式
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点: (NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode)
请注意分布式运行中的这几个结点的区别:
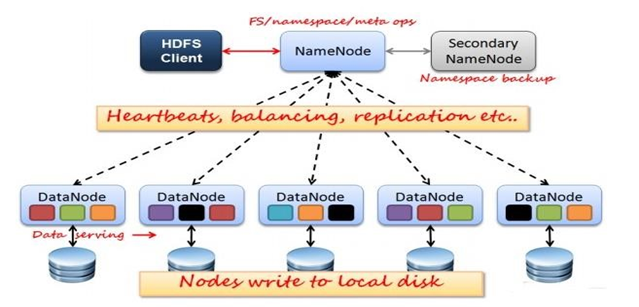
- 从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
- 从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。一个机器上,既当namenode,又当datanode,或者说 既 是jobtracker,又是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为"伪分布式"。开启多个进程模拟完全分布式,但是并没有真正提高程序执行的效率
3.完全分布式模式
真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
基础架构:
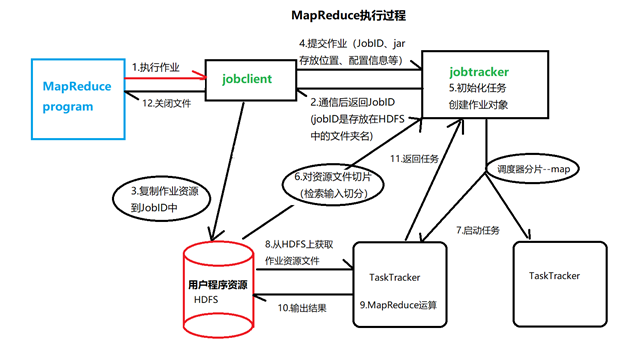
MapReduce执行过程:
参阅: https://www.cnblogs.com/wooluwalker/p/9130363.html