我觉得数据结构比其他东西有趣多了,所以我现在沉迷数据结构...
正题:
主席树
又名可持久化线段树,(其实应该反过来,最后说说这个问题[doge])
建议先掌握线段树
所谓可持久化,顾名思义,就是"持久",也就是运行时间长,
非也,是支持关于历史版本的操作,
举个栗子:
现在给定数列(a),以及若干次单元素修改,
每次修改会产生一个版本,可以理解为每次修改会产生一个新的数列,
每次修改还基于另一个版本,即一次修改可能在另一次修改之上
(其实也可能在原序列之上,其实就是对版本"0"的修改),
然后给出若干区间([l,r])以及一个(保证合法的)非负整数(k),要求你输出在第k次修改后的版本的某种序列信息,可以是单点元素值,可以是区间和,可以试最大最小值等等
区间长度和操作数如其模板题,这里模板题名字是"可持久化数组,但它实际上真的是可持久化线段树的真身"
(n,m leqslant 1000000)
遇到这种又毒瘤又难的问题,我们需要微笑着面对它先思考暴力进而分析正解,
在相当一部分的题目中,我们是可以根据暴力的思路推出正解的
基本实现思路及原理
那么我们先基于最基本的单点查询进行思考
看到这道题,先想想最暴力的方法:
开个(1000000*1000000)的数组暴力存储
显然只能拿非常可爱的暴力分...
其次我们可以考虑稍微优化一下:
开动态数组(vector) (a[n]),每次操作时就在对应位置添加值,然后就可以直接查询
有点意思,这应该就是比较优的策略了,
然而这并没有办法操作基于修改的修改,
如果要修改就只能搞并查集之类的骚操作
但这样就是麻烦,就是啰嗦...
那么对于其他需要维护区间信息的操作及查询呢?
对于上面的区间操作,不难看出要搞线段树,
因为要保证时间复杂度更优,我们只能去选择支持各种区间操作的强大数据结构,比如线段树
考虑这样的暴力:
对于每个操作建一棵新树,以维护所有区间信息
别看了空间炸裂,至少(O[(1e6)^2*4])
但是这样做无疑是正确做法,毕竟这样可以正确维护区间信息...
我们能不能向上面的单点查询一样,进行一些优化呢?
我们来考虑一些未曾考虑到的特殊性质:
- 每次修改只会修改一个元素,
也就是说,每次修改我们有大部分的数列不用更改
即对于区间信息,我们可以在修改的基础上,对于其他未曾修改的元素进行利用,
我们考虑以下思路:
开始建造一棵线段树,作为最初始序列的对应线段树,
然后对于每次修改,我们对于需要修改的元素所在的区间进行修改,造较少的新节点,作为修改元素对应区间的新修改的版本,
因为每次修改都基于某个版本,对于那些没修改的区间,我们只需要把改过的新节点的左右儿子关系啥的处理一下,将其与不含被修改元素的区间建立联系
也就是说,我们把新节点与不需更改的老节点建立联系,作为修改后的区间
这样一来,我们可以把之前不用修改的元素拉过来进行再利用,从而大大降低时间复杂度
理论-函数实现
这里主要维护单点值,学会了单点值维护区间值也就没什么了
把板子题放在这:真正的主席树模板题
有了思路,我们该如何实现呢?
首先要暂时遗忘以往的堆式存储线段树,就是这样的存储:
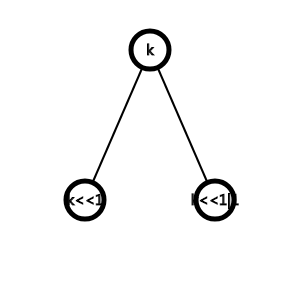
p.s.这里字不大清楚,他们分别是(k<<1),(k<<1|1)
因为在主席树中,所有节点的编号是混乱的,因为我们可能需要把之前的节点拉过来做新节点的儿子,所以并不能很好地确立
- 先看下需要的变量:
int rt[N<<5];
struct node{
int ls,rs,val;
}nd[N<<5];
int cnt;
int a[N];
(cnt)是用来开点的,作用类似于栈的(top)啥的,每次建立一个新节点就(++cnt)
对于结构体(nd)里的元素,(ls,rs)是左右儿子,(val)是节点权值,就是区间单点元素值
(a)数组就是原序列
结合代码看下新建点方式:
- 先是建树函数(build)
inline int build(ci l,ci r){
int k=++cnt;
if(l==r){nd[k].val=a[l];return k;}
int mid=l+r>>1;
nd[k].ls=build(l,mid);
nd[k].rs=build(mid+1,r);
return k;
}
这里与普通建树不一样的地方在于每次(build)函数会返回一个值,这个值是新建节点的编号,用于处理父子关系,
就是把当前节点的编号返回上去,让其父亲将其建立为儿子
对于建树,对于只维护单点权值的题目,非叶节点维护(val)没有意义
那么我们要怎么处理修改呢?
考虑下面这样一棵树:
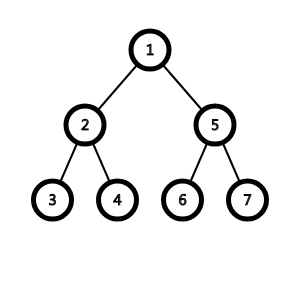
用以上(build)函数建出来就是这个鬼样子,
假如我们要修改序列元素(a[3]),在图中对应节点(6),
我们发现包含节点(6)对应元素的节点(线段树区间)就是它的所有父节点,
所以我们只用对其每一个父节点建立新节点,然后再将原有元素利用起来,
就像这样:
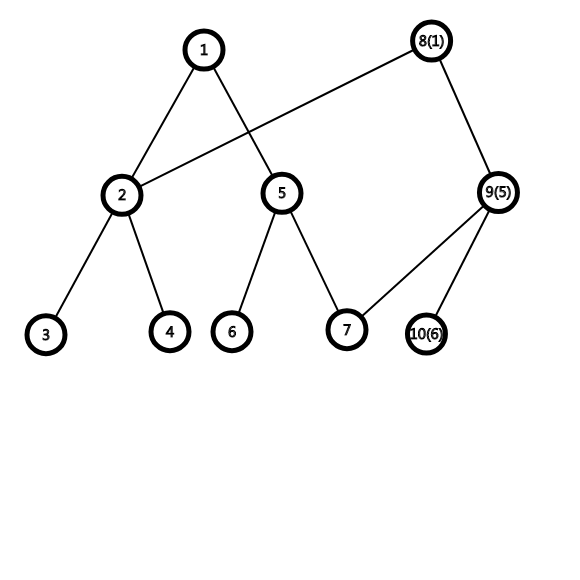
括号内表示原节点,
这样我们就用3个节点的超小空间完成了原来要重建一棵树的巨麻烦操作
来看代码:
- 修改函数(insert)
inline int insert(ci k,ci l,ci r,ci x,ci v){
int nk=++cnt;
nd[nk]=nd[k];
if(l==r){nd[nk].val=v;return nk;}
int mid=l+r>>1;
if(x<=mid) nd[nk].ls=insert(nd[nk].ls,l,mid,x,v);
else nd[nk].rs=insert(nd[nk].rs,mid+1,r,x,v);
return nk;
}
跟(build)函数差不多,就是多了一个复制节点操作,
这里新建节点的原理就是复制原版本的节点,然后赋上新值,建立新的儿子,
- 查询函数(query)
返回特定版本特定值,
inline int query(ci k,ci l,ci r,ci x){
if(l==r) return nd[k].val;
int mid=l+r>>1;
if(x<=mid) return query(nd[k].ls,l,mid,x);
else return query(nd[k].rs,mid+1,r,x);
}
这样基本函数部分基本实现完成了,
完整代码
#include<iostream>
#include<cstdio>
#define ci const int & //can you follow my speed?
using namespace std;
const int N=1000005;
int n,m;
int rt[N<<5];
struct node{
int ls,rs,val;
}nd[N<<5];
int cnt;
int a[N];
inline int build(ci l,ci r){
int k=++cnt;
if(l==r){nd[k].val=a[l];return k;}
int mid=l+r>>1;
nd[k].ls=build(l,mid);
nd[k].rs=build(mid+1,r);
return k;
}
inline int insert(ci k,ci l,ci r,ci x,ci v){
int nk=++cnt;
nd[nk]=nd[k];
if(l==r){nd[nk].val=v;return nk;}
int mid=l+r>>1;
if(x<=mid) nd[nk].ls=insert(nd[nk].ls,l,mid,x,v);
else nd[nk].rs=insert(nd[nk].rs,mid+1,r,x,v);
return nk;
}
inline int query(ci k,ci l,ci r,ci x){
if(l==r) return nd[k].val;
int mid=l+r>>1;
if(x<=mid) return query(nd[k].ls,l,mid,x);
else return query(nd[k].rs,mid+1,r,x);
}
int main(){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
rt[0]=build(1,n);
for(int i=1;i<=m;i++){
int ver,opr,loc;
scanf("%d%d%d",&ver,&opr,&loc);
if(opr==1){
int v;
scanf("%d",&v);
rt[i]=insert(rt[ver],1,n,loc,v);
} else {
rt[i]=rt[ver];
printf("%d
",query(rt[i],1,n,loc));
}
}return 0;
}
题目特殊性
对于其模板题这种垃圾无比操作较简单(只有单点查询)的题目,以后应该不会遇到这么简单的
然而对于这种只需要单点查询的题目,我们还是可以说它运用了序列操作,
因为一旦当前修改建立在其他修改之上,这个序列就可能有多个值已经被修改,而不是仅仅用vector就能够解决的
这也是为什么并查集可以做这道题,只要把一串修改所产生的集合并就可以了
最后
这是最基本的主席树,
我讲的好烂啊还是等以后回来update吧...
关于这个数据结构的发明者,他叫黄嘉泰,缩写hjt,自己意会