一 知乎数据清洗整理和数据研究
1 import matplotlib.style as psl
plt.style.available
psl.use()
2 plt.merge()
这里方法的功能超出我的想象。如果存在两张表,实际上不用对两张表清理的很彻底,就可以用merge方法,将两个表融合在一起,牛牛牛,非常有傲气。而且,有how参数,默认inner,就会保留我们想分析处理的字段。
3 label 参数,应用可能挺广泛的。在scatter,axvline中都有。
如果设置了label参数,plt.legend()就会显示。
4 plt.text(x,y,data.index ),有时候会展现出惊奇的效果。比如点的坐标,点的名称,尤其是名称,当时我看到的时候,以为是一个不知道的方法,最后才知道 是用plt.text实现的。
5 对数据进行去空值处理,我做的时候 是 不区分数据类型,全部填充"缺失数据",不是不可以,但更好的方法是 按照数据类型处理,pandas中,区分为object,和 int32,float32,等等,对这些数据应该区分处理。可以写个函数实现。
6 data.groupby().sum() / count()
二 视频网站数据清洗整理和结论研究
1 groupby的使用
在groupby后面,可以接筛选的列,然后接方法。以下,这两种方式是支持的
data.groupby('导演')[['好评数','评分人数']].sum()
data.groupby('导演').sum()[['好评数','评分人数']]
2 既然用到 numpy,pandas,就尽量使用 np,pd的方法。
series.str.replace() 等等,是可以实现 想要的操作的,而不要想着要用python的方法,然后在转换,效率就低了呀。
data['数据获取日期'].str.replace('月','-')
3 pd.merge() 这里又用到了,再一次强调,这个方法有妙用。
这里是 先生成data1,相关字段绝对不重复的一张表。data2 先将某个相关字段groupby,再加 求和 / 个数的表,将data1,data2,通过那个相关字段结合在一起。
q2data1 = data_c2[['导演','上映年份','整理后剧名']].drop_duplicates() q2data2 = data_c2.groupby('整理后剧名').sum()[['评分人数','好评数']] q2data3 = pd.merge(q2data1,q2data2,left_on='整理后剧名',right_index=True)
4 清理数据之清理重复数据
data.drop_duplicates()
三 北京落户人的数据分析
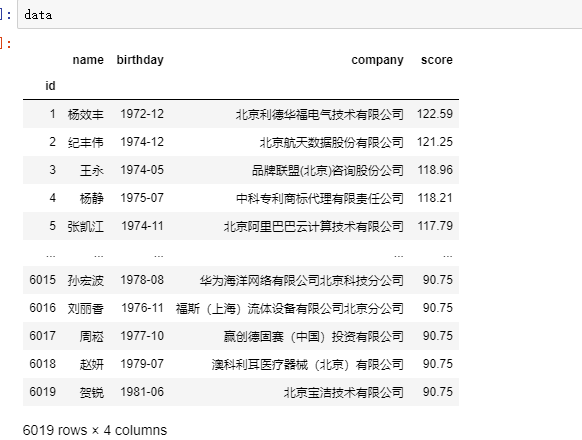
数据如下,尽管只有4列信息。但可以分析的方面很多。比如选择 company维度,哪家公司落户的人最多,落户最多的前二十家公司是那些? --> 排序
选择 birthday维度,落户的都有那些年龄段,不同年龄段落户的人 有多少? ---> 饼图 / 条形图
选择score维度,哪些分数段的落户最多? ---> 饼图 / 条形图
company 离散的类型,用到的方法是 --> groupby(' company ')
birthday,score 是连续的类型,用到的方法是 --> groupby( pd.cut( data[ 'score' ], np.arange(10,100,5 ) ) ).count()
当然,pd.cut( data[ 'score' ], np.arange(10,100,5 ) ) .value_counts() 也一样。
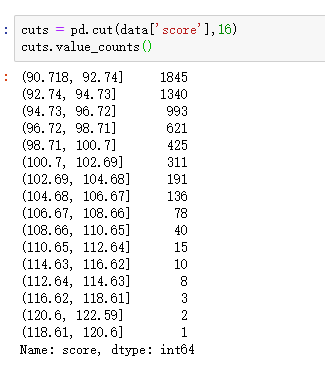
上面的思想要了解!
补充下 方法中的几个参数
1)pd.read_csv(index_col )
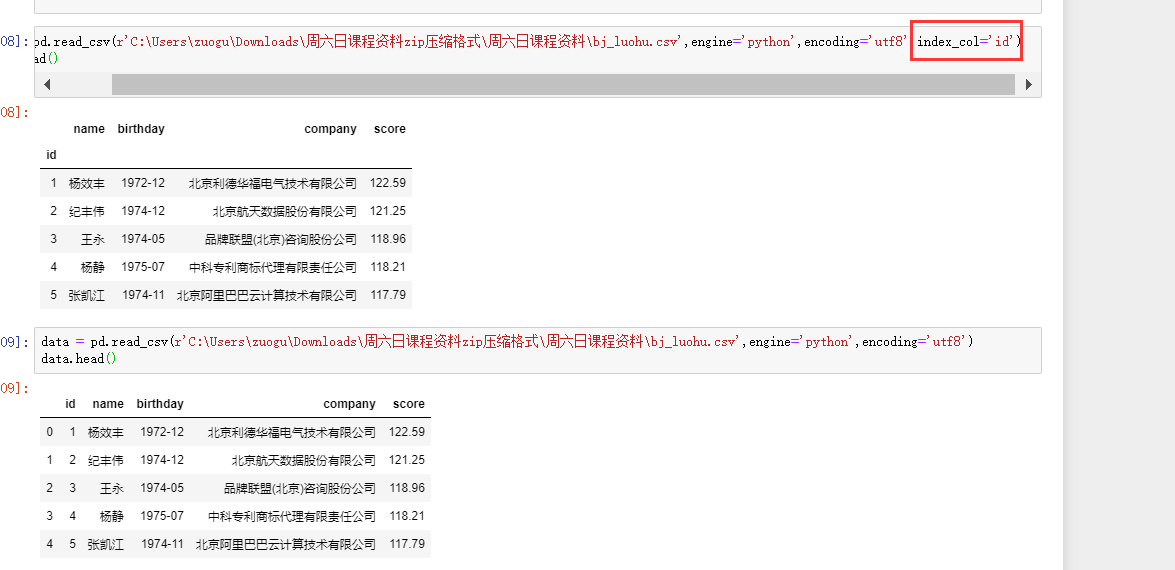
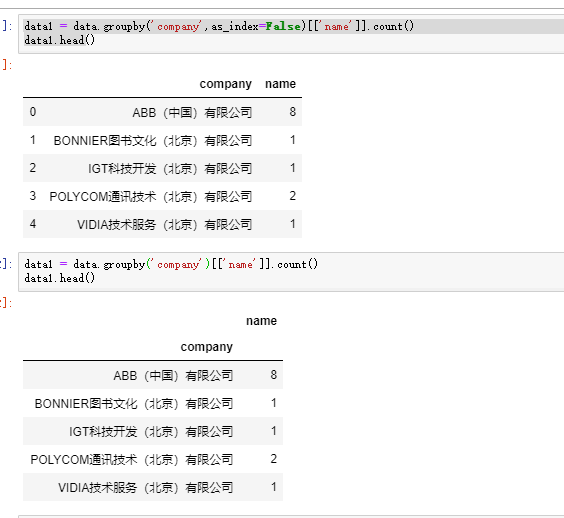
2)data.groupby(as_index=)
取false,就好看些了
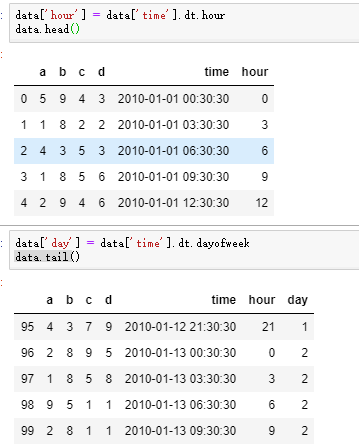
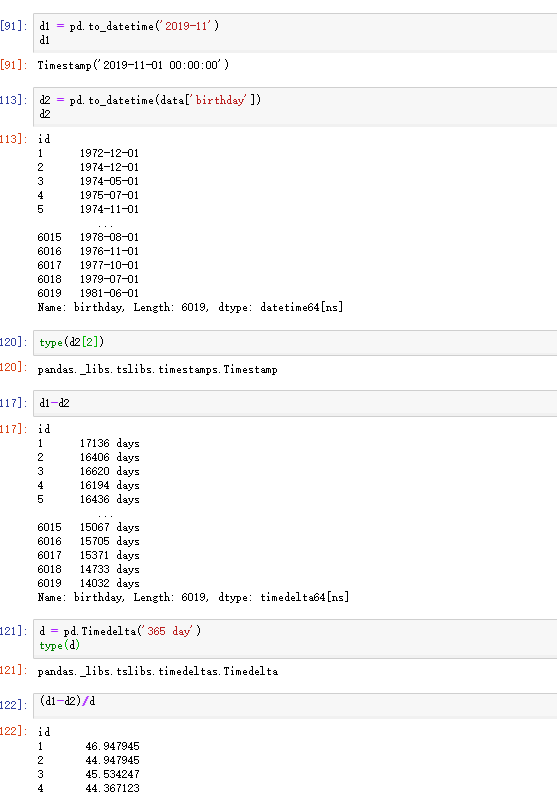
3)时间索引
总结下就是 一个 timestamp 可以和由timestamp组合的 时间序列 做加减运算。
运算完后,就是Timedelta类型,timedelta类型可以进行除法运算。
注意timedelta是如何构建的。
四
series根据value值获取对应的index。
d2[d2.values=='xx'].index 这不就是bool值1 一些方法以及一些参数
pd.read_csv(index_col='',usecols='') 对于 '4e+8' 这种类型,尽管是字符串模样,float方法是可以转变为float类型的,int方法是不可以的。转化为float后,df先 astype('f8') 如果想
转成int。然后
astype('i8')。直接 astype('i8') 似乎是不行的。
2 分析过程 1)最开始阶段,最重要的几个方法 data.describe() 因为只对数字类型进行运算,所以可以迅速的看出哪些是数字类型,哪些是字符串类型。字符类型自动忽略np.nan data.value_counts(dropna=False) 这在数据清洗的开始阶段非常重要。方法本身就会对值进行分类统计,这对于离散的值非常重要。drop_na参数, 这是因为数据本身可能有问题,同样可以让我们迅速的看出 当前的数据有没有问题。
data.count() 会把每一列的个数列出来,对nan值不计算。这一段尤为重要,这是看哪一列数组有nan的最简单方法。 count方法的妙用。 2)对数据清洗,先是看下有没有空值,异常值, 然后在去看有没有重复值。重复值最好放在最后处理。 空值就是 isnull() notnull() 利用布尔值索引,可以迅速的查出。(count方法) 重复值就是 unique() / unique().size 查看不重复值的个数。 当然 drop_duplicates 也是可以的。 3) 在对值进行处理是,经常会需要自己写函数,这就用到了apply方法。 在对有问题的数据进行定位时,最常用的手段就是布尔值索引,所以,自己写 的函数,条件满足是返回True,不满足是返回False,是很常见的。
分析的另外一点: 一个表有多列,或许有多组数组,可能有相关系。 data.corr(method='pearson') 在分析的两个变量都符合正态分布的情况下,最为精确 data.corr(method='spearman') 不要求分析的变量符合正态分布,仅要求变量至少是有序,离群值(outliers)时尽量选择Spearman统计
销量最大的10个产品和销售额最多的10个产品 就会用到 index.intersection方法 Form the intersection of two Index objects.
eg:data.index.intersection(np.arange(1,30,3))
这个方法就是取 筛选出来的两个df的index的交集
股票分析 1 一个简单的原则是看拐点,拐点的概念。昨天小于十日均线,今天大于十日均线,就卖,反之,就买。通过自定义函数,返回True,Fasle
进一步判断(布尔型索引),细节不再描述。 2 用到的方法是df.rolling(n).+ 聚合函数,这个rolling方法牛逼了。自动计算相邻的n个数,这个牢记。!!
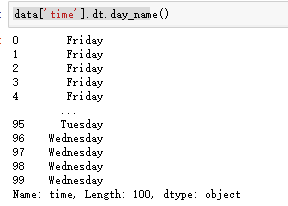
# 在电商领域,时间序列非常常见,是表中的非常重要的一部分。这里介绍两个方法 # 1 dt.方法 datetime类的一个很厉害的方法 # dt.day # dt.dayofweek # df.day_name ... # 2 月成交额 # 这就用到了resample的方法 Convenience method for frequency conversion and resampling of time series # data.resample('m').sum()['xx']