一 数值类型
原因:数值类型可能跨度过大,跨几个数量级,不符合模型的前提条件。拟合出来的模型不够强壮。
1 二值化
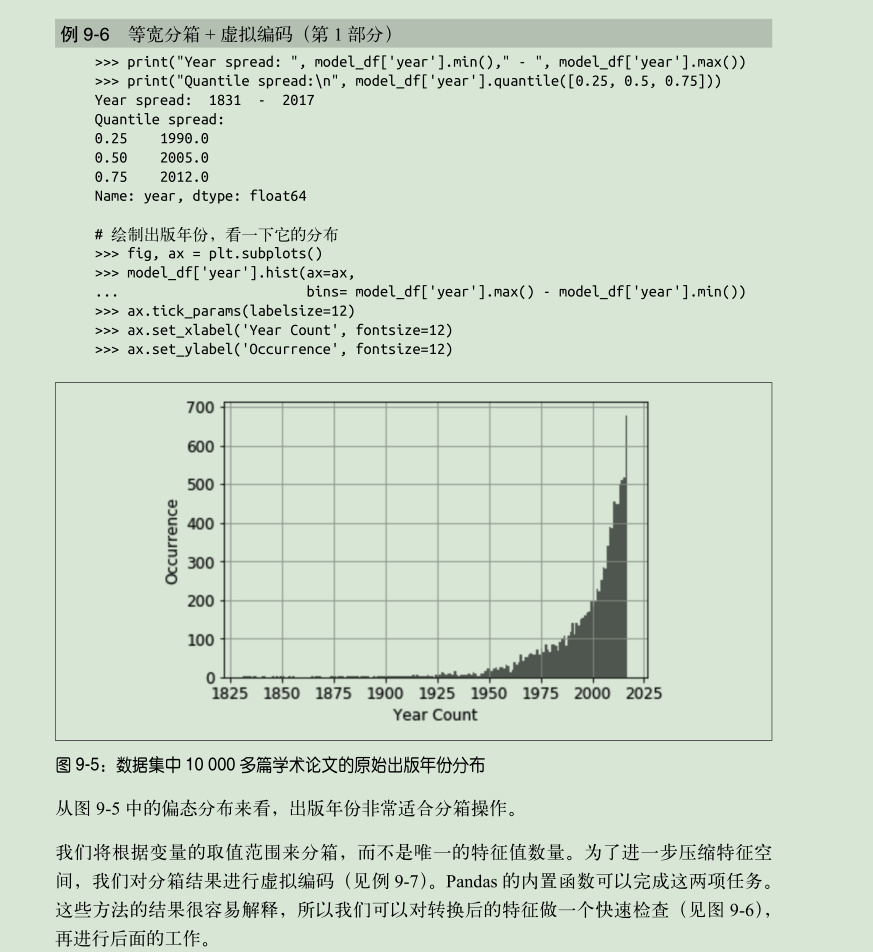
2 处理长尾分布数量,有两种思路,一种是对数处理,一种是分箱处理。处理的原因还是因为横跨了若干个数量级,对很多模型都是问题。
3 归一化,处理设计欧式距离的算法,比如KNN,K-means,线性回归等
4交互特征
好像挺牛逼的。代价不菲,需要精心设计。
在统计机器学习中,所有特征最终都会转化为数值型特征。
二 文本数据
from sklearn.feature_extraction.text import CountVectorizer
词袋模型 -- N元词袋
TF-IDF 本质是一种特征缩放技术。凸出了罕见词,并有效的忽略的常见词。
+ 逻辑回归 + 正则化 + GridSearchCV
三 分类数据
one-hot encoding
方法一 from sklearn.preprocessing import OneHotEncoder oh = OneHotEncoder() oh.fit(data) oh.transform(data).toarray() 方法二 pd.get_dummies(data)
虚拟编码
效果编码
大型分类数据


四 数据降维 --PCA
应用场景,特征之间 线性相关

五 非线性特征化与K均值


else
解决了我之前的一个疑惑