-
1、名词解释
分区:将一张大表在物理上分成多个分区,逻辑上仍然是同一个表名。
分表:将一张大表拆分成多张小表,不同表有不同的表名。
两种数据组织形式的原理图如下:

图 1分表与分区的原理图
-
2、实验目的
本实验的目的,在于对比分区与分表技术,分析其在"大图层"(大图层指要素数量超过200万条的图层)上的适用性。
-
3、实验数据
实验数据为贵州省87县地类图斑数据,要素总数为6695554。根据不同的数据组织+索引形式,形成了3个不同的实验主体:
- 分表存储+空间索引
- 按县分区+全局空间索引
- 按县分区+本地空间索引
-
4、实验过程
-
4.1 实验方法
-
在1:500、1:2000、1:10000、1:25000、1:50000、1:100000比例尺下,随机从贵州省省域内选择3个样本范围,作为空间查询时的查询范围。将6*3个样本范围分别与3个实验主体进行空间查询运算,记录每次查询的耗时。
为了使查询实验覆盖所有的使用场景,将在基于磁盘、基于内存的两种查询场景中重复上述实验。
-
4.2 实验算法
实验算法用来描述实现上述空间查询的计算方法。
-
4.2.1 分表算法
多表的算法有两种,分别命名为part_query、nopart_query,其伪代码如下:
-
4.2.1.1 nopart_query
根据xzq_xj (县级行政区底图),判断BR(Boundary Rectangle,范围矩形)与哪些县级行政区相交
loop
根据xzqdm查询县级图层名layername;
根据layername,判断BR与哪些要素相交,并返回结果;
end loop;
-
4.2.1.2 nopart_query2
根据xzq_xj (县级行政区底图),判断BR与哪些县级行政区相交
loop
根据xzqdm查询县级图层名layername;
得到与layername进行空间查询的SQL语句;
用UNION ALL进行SQL语句拼接;
end loop;
执行拼接后的SQL语句;
-
4.2.2 分区算法
分区的算法有3种,分别命名为part_query、part_query2、part_query3,其伪代码如下:
-
4.2.2.1 Part_query
根据xzq_xj (县级行政区底图),判断BR与哪些县级行政区相交
得到相交行政区列表 xzq_lists
将xzq_lists作为查询条件之一,SQL语句样式如下:
"select shape from part_table t where xzqdm in (xzq_lists) sdo_filter(t.shape,BR))";
-
4.2.2.2 Part_query2
将得到行政区列表 xzq_lists的过程内嵌到SQL语句里,其样式如下:
"select shape from part_table t where xzqdm in (select xzqdm from xzq_xj t where sdo_filter(t.shape,BR)) sdo_filter(t.shape,BR))";
-
4.2.2.3 Part_query3
仅使用BR作为查询条件,SQL语句样式如下:
select shape from part_table t where sdo_filter(t.shape,BR));
-
5、实验结果
-
5.1 基于磁盘的查询
-
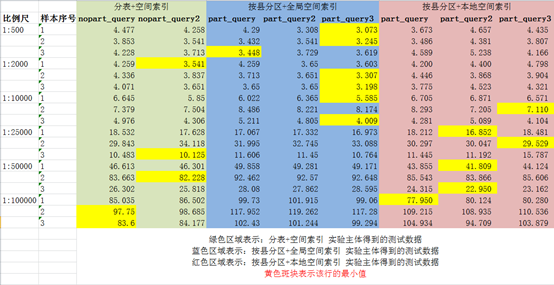
根据黄色斑块坐落的位置,可知:
- 在比例尺大于1:10000(包括)时,分区表+全局空间索引效率最高(命中7次),且part_query3算法最优(命中6次);
-
在比例尺小于1:10000时,分区表+本地空间索引效率最高(命中5次),且part_query2算法最优(命中3次)
-
5.2 基于内存的查询
-
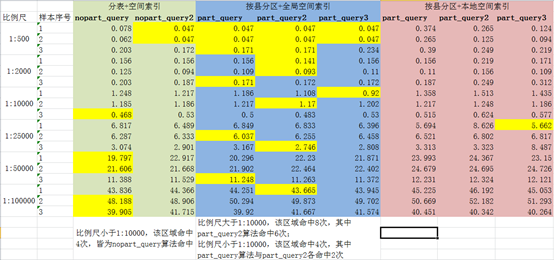
- 在比例尺大于1:10000(包括)时,分区表+全局空间索引效率最高(命中8次),且part_query2算法最优(命中6次);
-
在比例尺小于1:10000时,分表+空间索引与分区表+全局空间索引效率一致(命中4次),这其中分表+空间索引所使用的nopart_query算法最优(命中4次)。
-
6、实验结论
-
-
-
- 观察5实验结果中的两张图,横向比较,可知在该实验数据和实验条件下,不同数据组织方式和不同算法之间,其差异均不大。考虑到实验所在网络与服务器环境均非独占使用,单个查询性能可能会产生抖动性,因此上述分项结论仅作为参考,尚不能作为正式结论;
- 该实验所用的实验数据为87县市的地类图斑数据,而全国有近3000个县市,因此样本数据较之整体数据,仍显偏小。这从另一方面说明上述分项结论仅作为参考,尚不能作为正式结论;
- 上述实验所采集的时间数据,是在特定服务器与存储环境下得到的。在不同的设备情况下,其值会有不同。
- 若仅以此次实验结果为准,可得出如下结论:土地调查业务,大多数的应用场景,是在大比例尺,即1:10000-1:200比例尺下的查询浏览。因此在规划数据组织方式时,应更多考虑大多数应用场景的查询效率。基于此种考虑,建议数据物理组织采用:按县分区+全局空间索引。
-
(未完待续)