Spark的join操作可能触发shuffle操作。shuffle操作要经过磁盘IO,网络传输,对性能影响比较大。本文聊一聊Spark的join在哪些情况下可以避免shuffle过程。
1 DataFrame/Dataset的join如何避免shuffle
针对Spark DataFrame/DataSet的join,可以通过broadcast join和bucket join来避免shuffle操作。
1.1 Broadcast Join
Broadcast join很好理解,小表被分发到所有executors,所以不需要做shuffle就可以完成join. Spark SQL控制自动broadcast join的参数是:spark.sql.autoBroadcastJoinThreshold , 默认为10MB. 就是说当join中的一张表的size小于10MB时,spark会自动将其封装为broadcast发送到所有结点,然后进行broadcast join. 当然也可以手动将join中的某张表转化成broadcast :
sparkSession.sparkContext.broadcast(df)
1.2 Bucket Join
Bucket join其实就是将要join的两张表按照join columns(或join columns的子集)根据相同的partitioner预先做好分区,并将这些分区信息存储到catalog中(比如HiveExternalCatalog);然后在读取这两张表并做join时,spark根据bucket信息将两张表的相同partition进行join即可,从而避免了shuffle的过程。注意,这里是避免了shuffle过程,并没有完全避免网络传输,由于两张表的相同partition不一定在同一台机器上,所以这里仍需要对其中一张表的partition进行网络传输。
2 RDD的join什么情况下可以避免shuffle
笔者这里想讨论的是PairRDDFunctions类的join方法。在RDD对象中有一个隐式转换可以将rdd转换成PairRDDFunctions对象,这样就可以直接在rdd对象上调用join方法:

2.1 PairRDDFunctions.join和PairRDDFunctions.cogroup
先来看看PairRDDFunctions的join方法:

PairRDDFunctions有多个重载的join方法,上面这个只带一个RDD对象的参数,我们接着看它调用的另一个重载的join方法:
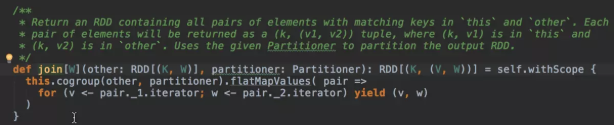
可以看到,RDD的join实现是由cogroup方法完成的,cogroup完后得到的是类型为RDD[(K, (Iterable[V], Iterable[W]))]的rdd对象,其中K为key的类型,V为第一张join表的value类型,W为第二张join表的value类型;然后,调用flatMapValues将其转换成RDD[(K, V, W)]的rdd对象。
下面来看看PairRDDFunctions.cogroup方法的实现:
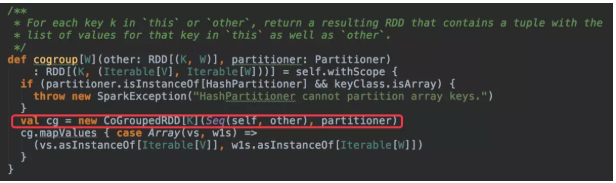
cogroup中生成了CoGroupedRDD对象,所以关键是这个RDD的getDependencies方法返回的dependencies中是否存在shuffle dependency.
2.2 CoGroupedRDD
看看这个RDD的getDependencies方法:

其中的rdds就是进行cogroup的rdd序列,也就是PairRDDFunctions.cogroup方法中传入的Seq(self, other) .
重点来了,对于所有参与cogroup的rdd,如果它的partitioner和结果CoGroupedRDD的partitioner相同,则该rdd会成为CoGroupedRDD的一个oneToOne窄依赖,否则就是一个shuffle依赖,即宽依赖。
我们知道,只有宽依赖才会触发shuffle,所以RDD的join可以避免shuffle的条件是:参与join的所有rdd的partitioner都和结果rdd的partitioner相同。
那么,结果rdd的partitioner是怎么确定的呢?上文讲到PairRDDFunctions.join方法有多个重载,其中就有可以指定partitioner的重载,如果没有指定,则使用默认的partitioner,看看默认的partitioner是怎么确定的:

简单地说就是:
1. 如果父rdds中有可用的合格的partitioner,则直接使用其中分区数最大的那个partitioner;
2. 如果没有,则根据默认分区数生成HashPartitioner.
至于怎样的partitioner是合格的,请读者阅读上面的Partitioner.defaultPartitioner方法和Partitioner.isEligiblePartitioner方法。
RDD的compute方法是真正计算得到数据的方法,我们来看看CoGroupedRDD的compute方法是怎么实现的:

可以看到,CoGroupedRDD的数据是根据不同的依赖从父rdd中获取的:
1. 对于窄依赖,直接调用父rdd的iterator方法获取对应partition的数据
2. 对于宽依赖,从shuffleManager获取shuffleReader对象进行读取,这里就是shuffle read了
还有一个重点是读取多个父rdds的数据后,怎么将这些数据根据key进行cogroup?
这里用到了ExternalAppendOnlyMap来构建key和grouped values的映射。先来看看createExternalMap的实现:

相关类型定义如下:

可以看到,ExternalAppendOnlyMap的构造函数的参数是是三个方法参数:
1. createCombiner : 对每个key创建用于合并values的combiner数据结构,在这里就是一个CoGroup的数据,数组大小就是dependencies的数量
2. mergeValue : 将每个value合并到对应key的combiner数据结构中,在这里就是将一个CoGroupValue对象添加到其所在rdd对应的CoGroup中
3. mergeCombiners : 合并相同key的两个combiner数据结构,在这里就是合并两个CoGroupCombiner对象
CoGroupedRDD.compute会调用ExternalAppendOnlyMap.insertAll方法将从父rdds得到的数据一个一个地插入到ExternalAppendOnlyMap对象中进行合并。
最后,以这个ExternalAppendOnlyMap对象作为参数构造InterruptibleIterator,这个iterator会被调用者用于访问CoGroupedRDD的单个partition的所有数据。
3 总结
本文简单地介绍了DataFrame/DataSet如何避免join中的shuffle过程,并根据源码详述了RDD的join操作的具体实现细节,分析了RDD的join在什么情况下可以避免shuffle过程