一、引言
对于一个学习问题,可以假设很多不同的模型,我们要做的是根据某一标准选出最好的模型。例如,在多项式回归中,对于我们的假设模型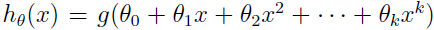 ,我们最要紧的是决定 k 到底取多少合适,能不能有一种方法可以自动选择出可以在偏差和方差(关于偏差和方差的理论,参考:
,我们最要紧的是决定 k 到底取多少合适,能不能有一种方法可以自动选择出可以在偏差和方差(关于偏差和方差的理论,参考:
学习理论
)之间做出均衡的模型?
为了具体讨论,本文中假设有一个有限的模型集 ,我们就是要从这个模型集中选出一个最好的模型。
,我们就是要从这个模型集中选出一个最好的模型。
二、 交叉验证
给定训练集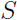 , 采用经验风险最小化的方法训练模型,于是很容易想到的就是,把模型集中训练误差最小的模型选出来,就有了下面的算法:
, 采用经验风险最小化的方法训练模型,于是很容易想到的就是,把模型集中训练误差最小的模型选出来,就有了下面的算法:
1. 用训练集训练出每一个假设模型 ,从而可以得到某个假设
,从而可以得到某个假设
2. 选出训练误差最小的模型
遗憾的是,这种方法行不通。就以最开始提到选择出多项式线性回归中,如何选择合适的阶数为例,显然阶数越高的模型,训练误差越小,但是这种模型的方差高,维度高,根据
学习理论
中的知识,这种模型是不行的.
下面介绍一种较好的方法,即hold-out交叉验证,又叫简单交叉验证:
1. 随见把分成 (例如整个数据的70%)和
(例如整个数据的70%)和 (剩下的数据),这里被称为hold-out交叉验证集
(剩下的数据),这里被称为hold-out交叉验证集
2. 只用去训练每一个模型,得出相应的某个假设
3. 计算每个模型在上的误差 (表示假设
(表示假设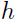 针对集合中样本的经验误差),选出这个误差最小的模型
针对集合中样本的经验误差),选出这个误差最小的模型
通过测试没有用来训练的集合中样本的误差,可以得出一个对假设的泛化误差较好的估计,然后选出估计的泛化误差最小的模型。通常1/4-1/3的数据用来作为,典型值是30%.
在第3步中,当我们选择出之后,再用整个训练集对重新训练一次会是一个不错的选择。
但是用hold-out交叉验证会浪费掉大约30%的数据信息,因为这一部分仅仅用来作为测试了,即使像我们上面说到的,最后一步再用整个训练集对选出的模型重新训练,但是这个模型也同样只是对0.7m个训练样本来说是一个好模型,而不是对m个训练样本而言(m是整个训练集中样本个数)。当然,数据量很大的时候,这种方法完全可以,因为信息足够多,但是当训练样本数本来就很小(例如m = 20)的时候,我们就需要做出改进了。下面就介绍一种方法来解决这种问题:k折交叉验证(k-fold cross validation):
1. 随机把分成 k 个不相交的子集,每个子集有 m/k 个样本,把这些子集记作:
2. 对于每一个模型,
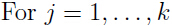
用 训练模型(即用除了
训练模型(即用除了 外的所有训练集数据),得出假设
外的所有训练集数据),得出假设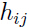 .
.
用测试,得到
通过对所有j, 计算的平均值,即得到了的泛化误差的估计.
3 .选择出泛化误差估计值最小的模型,然后用整个训练集重新训练,得到最终结果。
通常 k 设为10.尽管每个子集的数据量是整个数据集的1/k, 远远小于整体数据量,但是这个方法计算效率还是要比hold-out交叉验证低,因为第二步中每一个模型都要都要训练 k 次.
有时会将 k 极端地设置为m(即k与整个训练集中的样本数目相等),这种方法有着特别的名称:
三、特征选择
假设有一个监督学习问题,训练样本的特征数量n很大(例如n » m),但是只有一小部分特征与我们的学习任务相关。因此直接使用所有的特征将会很容易出现过拟合的问题。
于是,需要使用特征选择算法减少特征的数量。对于n 个特征,我们可以有 2n 种选择。通常用启发式的搜索过程来找出较好的特征(较相关的特征),下面的搜索过程叫做前向搜索:
1. 初始化
2. 循环{
(a)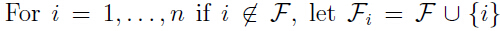 ,用交叉验证评估
,用交叉验证评估 (即,只用特征来训练学习算法,然后估计学习出模型的泛化误差)
(即,只用特征来训练学习算法,然后估计学习出模型的泛化误差)
(b)把(a)中最好的特征子集作为选择出的特征
}
3. 把上述整个搜索过程中泛化误差最小的特征子集作为我们选择出的特征。
上面第二步的外层循环终止条件可以设为当
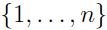 包含了所有特征时,或所选出的特征数量超过我们预设值的时候(比如我们只想选出10个特征)。
包含了所有特征时,或所选出的特征数量超过我们预设值的时候(比如我们只想选出10个特征)。
上面所述的算法其实是封装式特征选择算法(wrapper model feature selection)的一个特例,因为这个算法是封装在我们对模型学习算法里面的,即需要重复使用学习算法(最小化误差)去估计每一个特征子集的好坏。除了前向搜索,还有反向搜索,即开始令 ,然后每次删除一个特征,比较删除前后连个特征子集的好坏,直到为止.
,然后每次删除一个特征,比较删除前后连个特征子集的好坏,直到为止.
封装式学习算法通常效果都不错,但是由于每一次都要调用学习算法去估计特征子集的好坏,使得计算效率低。在一个完整的前向搜索过程中,当以时为终止条件时,大约需要调用学习算法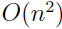 次.
次.
过滤式特征选择(Filter feature selection)算法同样是一种启发式算法,但是计算代价要小很多。主要思想是计算一个简单的分数 去衡量对于类别集
去衡量对于类别集 ,特征
,特征 所含信息量的大小。然后选择出 k 个最大的特征.
所含信息量的大小。然后选择出 k 个最大的特征.
所以关键是如何定义,在实践中(特别是特征值是离散的时候),常常用和之间的互信息(mutual information) 来表示:
来表示:
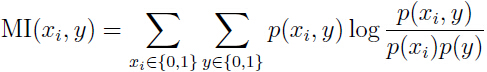
上面式子中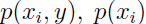 和
和 可以根据对应事件在训练集中的分布估计出来,例如
可以根据对应事件在训练集中的分布估计出来,例如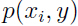 就表示在训练集中特征属于类别的概率,
就表示在训练集中特征属于类别的概率,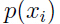 表示特征出现的概率。
表示特征出现的概率。
注意到可以写成 divergence的形式:
divergence的形式:

这个表达式是用来衡量和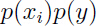 之间的不同程度的,如果和是互相独立的随机变量,那么
之间的不同程度的,如果和是互相独立的随机变量,那么 ,由上面的式子很容易知道KL-divergence的值为0.
,由上面的式子很容易知道KL-divergence的值为0.
这和的意义很一致,如果和是互相独立的随机变量,那么特征很明显没有任何关于的信息,因此应该是一个很小的值,相反,如果特征包含有很多与相关的信息,的值就很大。
计算出来评分之后,用交叉验证来确定到底选取几个特征合适。
四、贝叶斯统计和正则化
这一部分继续讨论如何遏制过拟合。
在机器学习笔记的最开始,我们提到了一种你和参数的方法就是最大似然函数(maximum likelihood (ML)):
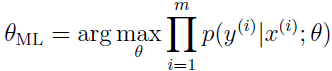
我们把 称为
称为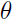 的先验概率,给定训练集
的先验概率,给定训练集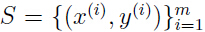 ,当我们要对一个新的
,当我们要对一个新的 进行预测时,就可以计算参数的后验概率:
进行预测时,就可以计算参数的后验概率:
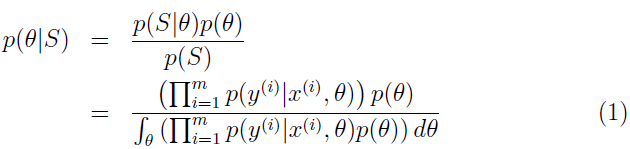
等式中 根据在学习算法中实际使用的模型而定。例如,如果使用贝叶斯逻辑回归,那么如果假设为
根据在学习算法中实际使用的模型而定。例如,如果使用贝叶斯逻辑回归,那么如果假设为 ,则
,则 .
.
对于一个新样本,用参数的后验分布计算标签集的后验分布:
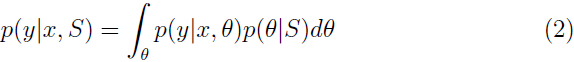
根据这个概率值求出在给定情况下的期望值就是预测的输出值:
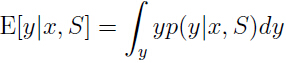
但是在实际操作中,计算这些后验概率分布会很棘手,因为由上面式子可以看出需要对(通常是高维)进行积分。
因此在实践过程中,我们近似地计算的后验概率分布,而不是直接如同上面讨论的一样去计算。一种常用的近似方法是用一个单点估计代替的后验概率分布(如等式2).
对的最大后验(MAP,maximum a posteriori)估计:
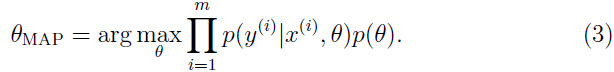
上面等式除了最后的,其余部分和ML(最大似然)估计一样。
在实际应用中,对于先验概率通常假设 .
.
在实践中,贝叶斯最大后验(MAP)估计比起最大似然(ML)估计更加容易避免过拟合。