视频课程
储备知识
1.用户态与内核态的区分:在高的执行级别下,代码可以执行特权指令,访问任意的物理内存,这时候cpu的执行级别对应的就是内核态,对所有的指令包括特权指令都可以执行。相应的在用户态(低执行级别)代码能够掌控的范围受到限制,只能在对应级别允许的特定范围内活动。
2.Intel x86 CPU有四种不同的执行级别0-3,Linux只使用了其中的0 3级分别表示内核态和用户态。
3.在用户态时,只能访问0x00000000—0xbfffffff的地址空间,0xc0000000以上的地址空间只能在内核态下访问。这里的地址空间是逻辑地址而不是物理地址,逻辑地址是进程的地址空间里面的。
4.中断处理是从用户态进入内核态的主要方式,系统调用只是特殊的中断。
5.中断发生后的第一件事就是保护现场,中断处理结束前的最后一件事是恢复现场。保护现场:就是进入中断程序,保存需要用到的寄存器的数据。恢复现场:就是退出中断程序,恢复保存寄存器的数据。
系统调用
1.系统调用的意义:操作系统为用户态进程与硬件设备进行交互提供了一组接口——系统调用。
(1)把用户从底层的硬件编程中解放出来。(2)极大的提高了系统的安全性(3)使用户程序具有可移植性。
2.操作系统提供的API和系统调用的关系.
应用编程接口(application program interface, API) 和系统调用是不同的。API只是一个函数定义,系统调用通过软中断向内核发出一个明确的请求。Libc库定义的一些API引用了封装例程,唯一目的是发布系统调用,一般每个系统调用对应一个封装例程,库再用这些封装例程定义出给用户的API。
3.系统调用的三层皮:xyz(API)、system_call(中断向量)、sys_xyz(中断服务程序)。
4.寄存器传递参数限制:每个参数的长度不能超过寄存器的长度,即32位,在系统调用号(eax)之外,参数的个数不能超过6个(ebx,ecx,edx,esi,edi,ebp),如果超过6个就把某一个寄存器作为指针,指向内存,就可以访问所有的地址空间,就可以通过内存来传递。
实验楼实验
使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用
这次我实验所用的系统调用是8号creat函数。
1.打开虚拟机
2.执行命令vi creat.c创建creat.c文件,在vi下输入代码如下:
#include<stdio.h>
#include<fcntl.h>
int main()
{
int ret =0;
char* filename = "createfile1";
mode_t mode = 0755;
ret = creat(filename,mode);
printf("file %d create success
",ret);
return 0;
}
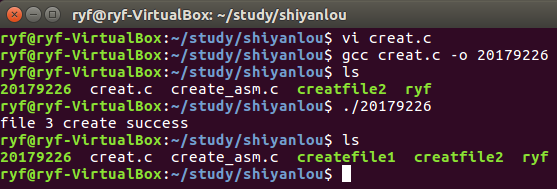
3.执行命令gcc creat.c -o 20179226编译文件,会生成一个20179226的可执行文件,输入./20179226来执行,如图:
4.代码执行成功,接下来更改代码,执行命令vi creat_asm.c将其写成嵌入汇编的代码,如下:
#include<stdio.h>
#include<fcntl.h>
int main()
{
int ret =0;
char* filename = "createfile2";
mode_t mode = 0755;
asm volatile(
"movl $8,%%eax
"
"int $0x80
"
"movl %%eax,%0
"
:"=m"(ret)
:"b"(filename),"c"(mode)
);
printf("file %d create success
",ret);
return 0;
}
5.最后编译并执行最后运行结果如下:

阅读教材第7、8章
教材主要讲述了中断和tasklet、软中断以及工作队列的相关知识。
1.中断
中断使得硬件得以发出通知给处理器。中断本质是一种特殊的电信号,由硬件设备发向处理器。异常与中断不同,它在产生时必须考虑与处理器时钟同步,异常也常常称为同步中断。
2.中断处理程序
在响应一个特定中断的时候,内核会执行一个函数,该函数叫做中断处理程序或中断服务例程。中断可能随时发生,因此中断处理程序也就随时可能执行。中断处理程序几乎都需要通过操作硬件对中断的到达进行确认。在Linux中,中断处理程序就是普普通通的C函数。
3.注册中断处理程序
中断处理程序是管理硬件的驱动程序的组成部分,共享的处理程序与非共享的处理程序在注册和运行方式上比较相似,但差异主要有以下三处:
1)request_irq()的参数flags必须设置IRQF_SHARED标志。
2)对于每个注册的中断处理程序来说,dev参数必须唯一。
3)中断处理程序必须能够区分它的设备是否真的产生了中断。
4.上半部与下半部的对比
鉴于两个目的之间存在此消彼长的矛盾关系,所以我们一般把中断处理切为两个部分或两半。中断处理程序是上半部,下半部的任务就是执行与中断处理密切相关但中断处理程序本身不执行的工作。上半部分简单快速,执行的时候禁止一些或者全部中断,下半部分稍后执行,而且执行期间可以响应所有的中断。
5.内核提供了三种不同形式的下半部实现机制:软中断、tasklets和工作队列。
6.软中断
1)软中断的实现:软中断处理程序→执行软中断(一个注册的软中断必须在被标记后才会执行。这被称作出发软中断)。
2)使用软中断:分配索引→注册你的处理程序→触发你的软中断
7.tasklet
1)tasklet是通过软中断实现的,tasklet由两类软中断代表:HI_SOFTIRQ和TASKLET_SOFTIRQ
2)使用tasklet:声明你自己的tasklet→编写你自己的tasklet处理程序→调度你自己的tasklet→ksoftirqd
8.工作队列
1)工作队列可以把工作推后,交由一个内核线程去执行,工作队列允许重新调度甚至睡眠。
2)使用工作队列:创建推后的工作→工作队列处理函数→对工作进行调度→刷新操作→创建新的工作队列
9.下半部机制的选择
从设计的角度考虑,软中断执行序列化的保障最少;如果代码多线索化考虑得并不充分,选择tasklet意义更大;把任务推后到进程上下文中完成,易于工作就选择工作队列。简单来说就是如果推后执行的任务需要睡眠就选择工作队列,如果推后的任务不需要睡眠,就选择软中断或tasklet,软中断和tasklet中更倾向选择tasklet。
遇到的问题
在c语言中使用库函数API的时候没有看到当前目录下多了一个createfile1的目录,不知道是编码原因还是什么原因,上网查了半天也不知道,最后检查发现少打了一行代码。。。修改后发现果然产生了creatfile1的目录,结果图如下: