在用python进行数据分析的时候,需要提前安装如下几个库:
Numpy:是python进行科学计算的科学包
1.快速、高效的多维数组对象ndarray
2.基于元素的数组计算或数组间数学操作函数
3.用于读写硬盘中基于数组的数据集的工具
4.线性代数操作、傅里叶变换以及随机数生成
5.成熟的C语言的API,允许Python拓展和本地的C或C++代码访问Numpy的数据结构和计算设施
pandas:提供了能够快速便捷地处理结构化数据的大量数据结构和函数
1.带有标签轴,支持自动化或显式数据对其功能的数据结构---这可以防止未对齐数据和不同数据源的不同索引数据引起的常见错误
2.集成事件序列函数功能
3.能够同时处理时间序列数据和非时间序列数据的统一数据结构
4.可以保存元数据的算术操作和简化
5.灵活处理缺失数据
6.流行数据库(例如基于SQL的数据库)中的合并等关系型操作
matplotlib: 看名字和matlab有点像,matplotlib是最新流行的用于制图及其他二维数据可视化的python库。
ipython:科学计算标准工具集的组成部分,它将其他的东西都联系到了一起。可以算是一个集成开发环境,也算是一个Python shell. 它主要用与交互式数据处理和利用matplotlib对数据进行可视化处理。
Scipy: 专门解决科学计算中的各种标准问题域的包的集合。
scipy.integrate 数值积分例程和微积分方程求解器。
scipy.linalg 线性代数例程和基于numpy.linalg的矩阵分解。
scipy.optimize 函数优化器(最小化器)和求根算法。
scipy.signal 信号处理工具。
scipy.sparse 稀疏矩阵与稀疏线性系统求解器。
scipy.special SPECFUN的包装器,SPECFUN是Fortran语言下实现通用数据函数包,例如gamma函数。
scipy.stats 标准的连续喝离散概率分布(密度函数、采样器、联系分布函数)、各类统计测试、各类描述性统计。
scikit-learn:python编程者首选的机器学习工具包
1.分类:SVM、最邻近、随机森林、逻辑回归等
2.回归:Lasso、岭回归等
3.聚类:k-means、谱聚类等
4.降维:PCA、特征选择、矩阵分解等
5.模型选择:网格搜索、交叉验证、指标矩阵
6.预处理:特征提取、正态化
statsmodels:与scikit-learn相比,statsmodels包含经典的(高频词汇)统计学、经济学算法
1.回归模型:线性回归、通用线性模型、鲁棒线性模型、线性混合效应模型等
2.方差分析
3.时间序列分析:AR、ARMA、ARIMA、VAR等模型
4.非参数方法:核密度估计、核回归
5.统计模型结果可视化
上述所有的包,都可以使用 pip install xxx来安装。
pip install numpy
pip install pandas
pip install matplotlib
pip install scipy
pip install scikit-learn
pip install statsmodels
pip install ipython
pip install jupyter
我们首先来了解ipython:
我们通过命令行来启动ipython
(Data_Analysis) E:Data_Analysis>ipython
Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 7.7.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]:
可以在这里输入任何的python语句,然后按回车就可以执行了。arange 相当于 python的 range。
In [1]: import numpy as np
In [2]: np.arange(10)
Out[2]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
下面的这个例子使用了np.random.randn函数。numpy中有一些产生随机数的函数。其中就包括randn和rand
In [3]: data={i:np.random.randn() for i in range(10)}
In [4]: data
Out[4]:
{0: -3.0789049441796696,
1: -0.4064956600014976,
2: -0.7119730735739772,
3: 1.9145643424507373,
4: -1.092280183494932,
5: 0.20963854522241657,
6: 0.03815550578098006,
7: -0.8527893032174164,
8: 1.643940029122834,
9: -0.31620208006562284}
TAB自动化功能:
在shell中输入表达式时,只要按下tab键,当前命令空间中任何与已输入的的字符串相匹配的变量就会被找出来。
在命令行中输入‘d’,并按 Tab键,不只找出了 ‘data’。
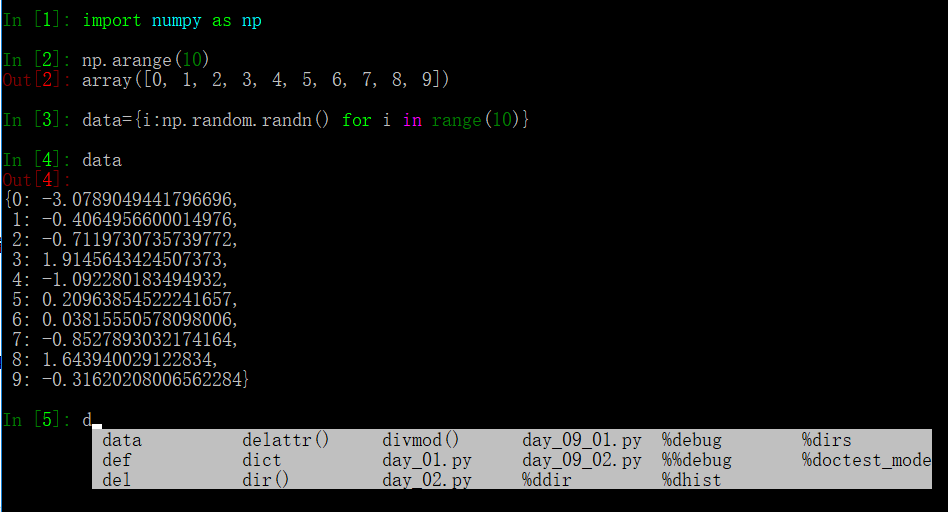
还可以在任何对象后面输入一个点号然后按下tab来查找出所有的属性。

同样的也可以应用于模块中。

内省
在变量的前面或者后面加上一个?就可以将有关该对象的一些通用信息显示出来:

这个方法对于函数也是同样适用的。?显示出这段docstring, ??显示出该函数的源代码。
显示docstring

显示出该函数的源代码

%run命令
在ipython中,所有文件都可以通过%run命令当做python程序来运行,用法 %run xxx.py,类似于 python xxx.py。有如下脚本day_09_01.py
import numpy as np
data = np.arange(10)
print(data)

通过%run命令就可以直接执行。如果在执行过程中发现有错误,ipython默认会输出整个调用栈跟踪traceback
软件开发工具:
在ipython中集成了pdb工具,可以很方便的对代码进行调试。在ipython中使用%run -d 脚本进入调试器
调试器的命令有如下:
h(elp):显示命令行列表
c(ontinue):恢复程序的执行
q(quit):退出调试器
b(reak) number:在当前文件的number行设置断点
s(tep):单步进入函数调用
n(next):执行当前行,并进入到下一行
u(p)/d(own):在函数调用栈中向上或向下移动
a(rgs):显示当前函数的参数
debug statement:在新的递归调试器中调用statement
l(ist) statement:显示当前行,以及当前栈级别上的上下文参考代码
w(here):打印当前位置的完整栈跟踪。
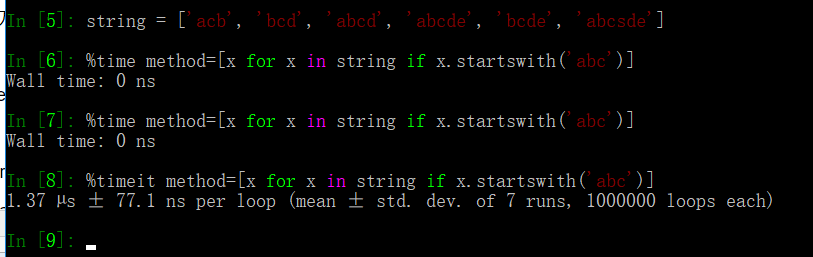
测试代码的执行时间:
在python中如果要计算代码的执行时间一般都是用如下的方法:
import time
start=time()
******function******
end=time()
during=end-start
在ipython中专门提供了2个魔术函数自动完成该过程。%time一次执行一个语句,然后报告执行的总体时间,ipython还提供了%timeit 命令来多次执行并返回一个精确的平均执行时间。
ipython HTML Notebook:
Notebook是ipthon一个很棒的功能,它把命令行交互从终端搬到了网页上,对于演示来说非常方便。首先需要安装jupyter。pip install jupyter。
在命令行模式下执行 ipython notebook
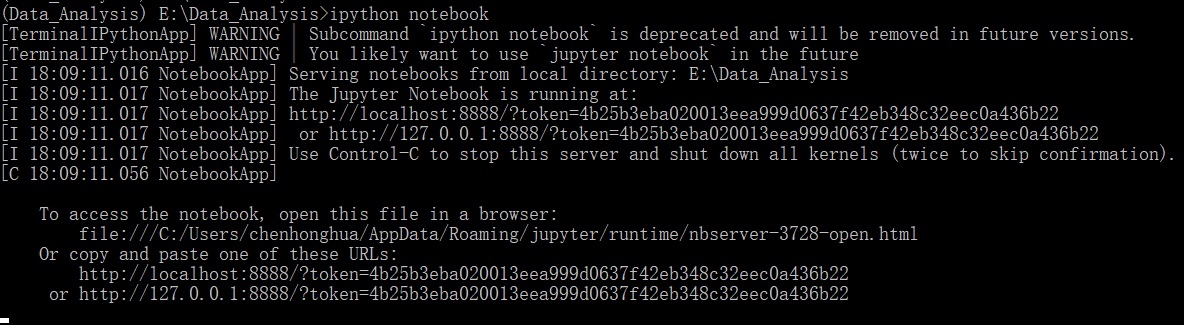
或者 ipython notebook --allow-root

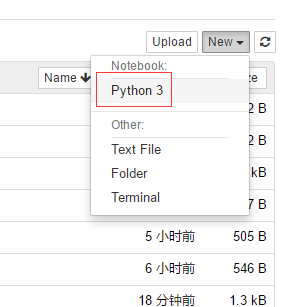
浏览器会自动弹出界面如下,会将当前工作目录下的文件都显示出来

在new下点击Python3就可以进入在线交互平台
在此可以输入交互命令,每个交互命令都是一个cell,可以在前后分别插入cell也就是命令。点击“运行”后即可运行
