本文来自公众号“AI大道理”。
三音子模型词错误率为:36.03%,对比单音素模型词错误率为50.58%。
可见三音素模型识别率已经有了提高。
能否继续优化模型?又要从哪些方面入手进行优化呢?
特征变换带来一定的改善。
语音识别中,为了增强音频特征的鲁棒性,需要提取区分能力较强的特征向量,常用的方法是PCA和LDA算法。
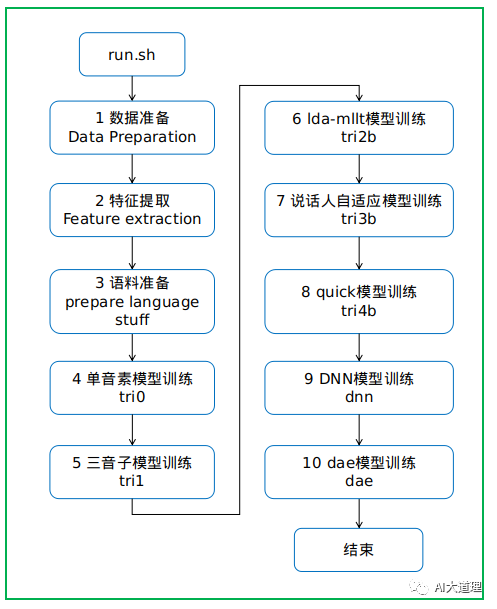
以kaldi的thchs30为例。

![]() 总过程
总过程
![]()
![]() 特征变换
特征变换
特征变换是指将一帧声学特征经过某种运算转化为另外一帧特征的过程。
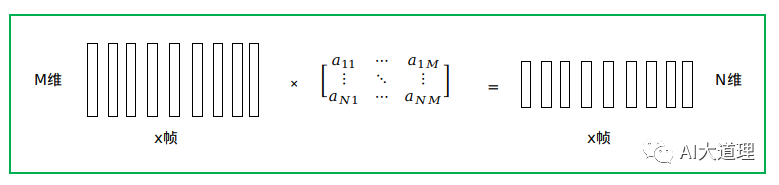
![]()
特征变换又分为有监督特征变换和无监督特征变换。
无监督特征变换不依赖标注信息,包括差分、拼帧、归一化等。

![]()
有监督特征变换依赖标注信息,估计一组变换系数来增强输入特征的表征能力,来优化声学模型。
灵魂的拷问:如何估计这组变换系数呢?
答:线性判别分析(LDA)、最大似然线性变换(MLLT)。
![]() 主成分分析(PCA)
主成分分析(PCA)
在讲LDA前,先来了解一下PCA。
LDA和PCA就像是一对孪生兄弟,总是被放在一起比较。
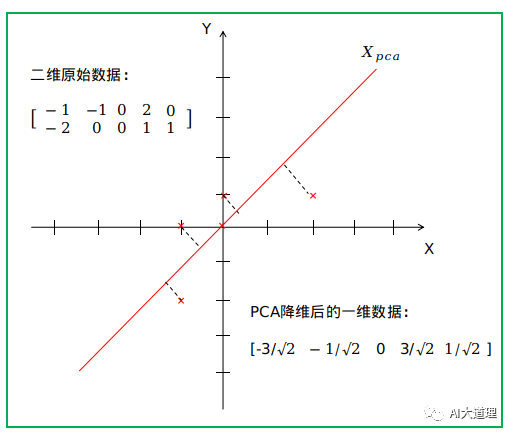
PCA是一种无监督的数据降维方法。
PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
灵魂的拷问:为什么要进行降维?
答:机器学习中处理成千上万甚至几十万维的情况也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此我们必须对数据进行降维。
![]()
PCA的本质:是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
PCA降维的目标:将数据投影到方差最大的几个相互正交的方向上。
PCA算法寻找,保留数据中最有效的,最重要的成分,舍去一些冗余的,包含信息量减少的成分。
![]() 线性判别分析(LDA)
线性判别分析(LDA)
LDA指的是线性判别分析,是一种监督学习的降维技术,它的数据集的每个样本是有类别输出的。
使用PCA模型的时候,是不利用类别标签的,而LDA在进行数据降维的时候是利用数据的类别标签提供的信息的。
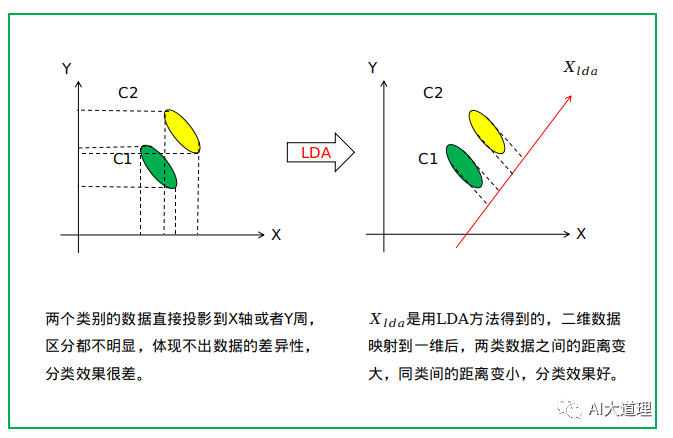
与PCA保持数据信息不同,LDA是为了使得降维后的数据点尽可能地容易被区分。
LDA的核心思想:投影后类内方差最小,类间的方差最大。
简单来说就是同类的数据集聚集的紧一点,不同类的离得远一点。
从几何的角度来看,PCA和LDA都是讲数据投影到新的相互正交的坐标轴上。
只不过在投影的过程中他们使用的约束是不同的,也可以说目标是不同的。
![]()
LDA降维的目标:将带有标签的数据降维,投影到低维空间同时满足三个条件:
-
尽可能多地保留数据样本的信息(即选择最大的特征是对应的特征向量所代表的的方向)。
-
寻找使样本尽可能好分的最佳投影方向。
-
投影后使得同类样本尽可能近,不同类样本尽可能远。
LDA算法是通过一个变化矩阵来达到降维的目的,LDA与PCA不同之处在于,LDA使得样本内的分布凝聚,使得样本间的分布疏远,这样的特征更加有代表性。
![]() 最大似然线性变换(MLLT)
最大似然线性变换(MLLT)
经过LDA变换后的协方差矩阵不能对角化,因此需要经过MLLT进行变换。
最大似然线性变换有很多种,这一步是半绑定协方差(STC),在kaldi中称为MLLT,用于全局特征变换。
MFCC→CMVN→Splice→LDA→MLLT→final.mat,然后训练GMM。
LDA根据降维特征向量建立HMM状态。
MLLT根据LDA降维后的特征空间获得每一个说话人的唯一变换。
MLLT实际上是说话人的归一化。
![]() 6 lda-mllt模型
6 lda-mllt模型
![]() 6.1 train_lda_mllt.sh
6.1 train_lda_mllt.sh
功能:
使用mfcc+cmvn+splice+LDA特征,获得final.mat(LDA和MLLT变换合在一起)
主要是特征做LDA/MLLT变换,转换以后的特征重新训练GMM模型。
通常在LDA之前对原始MFCC特征进行帧拼接(例如将九个连续的帧拼接在一起)。
splice-feats实现了帧的拼接:
feats="ark:splice-feats scp:data/train.scp ark:- |
transform-feats $dir/0.mat ark:- ark:-|"
LDA+MLLT指的是我们在计算MFCC后变换特征的方式:我们在多个帧之间拼接,使用线性判别分析降低维数(默认情况下降到40),然后通过多次迭代估计称为MLLT或STC的对角化变换。
过程之道:

![]()
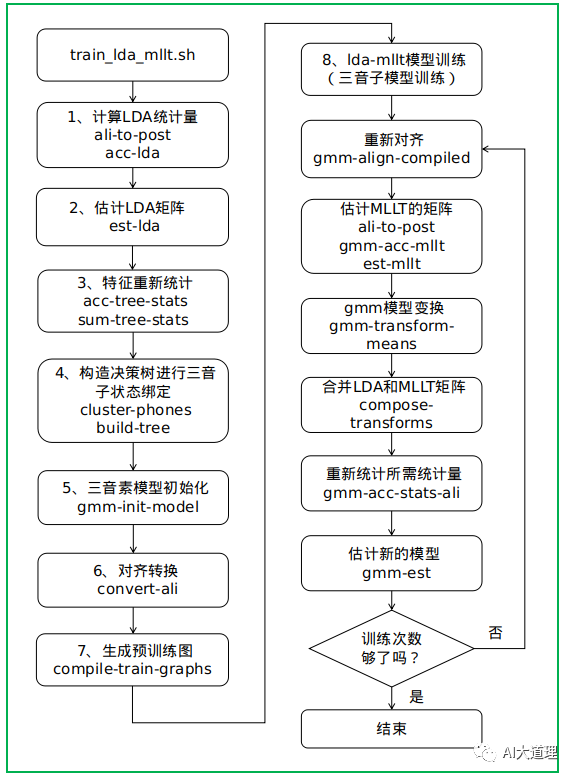
![]()
该程序的执行流程为:
-
估计出LDA变换矩阵M,特征经过LDA转换。
-
用转换后的特征重新训练GMM。
-
计算MLLT的统计量。
-
更新MLLT矩阵T。
-
更新模型的均值μjm←Tμjm
-
更新转换矩阵M←TM
训练过程:
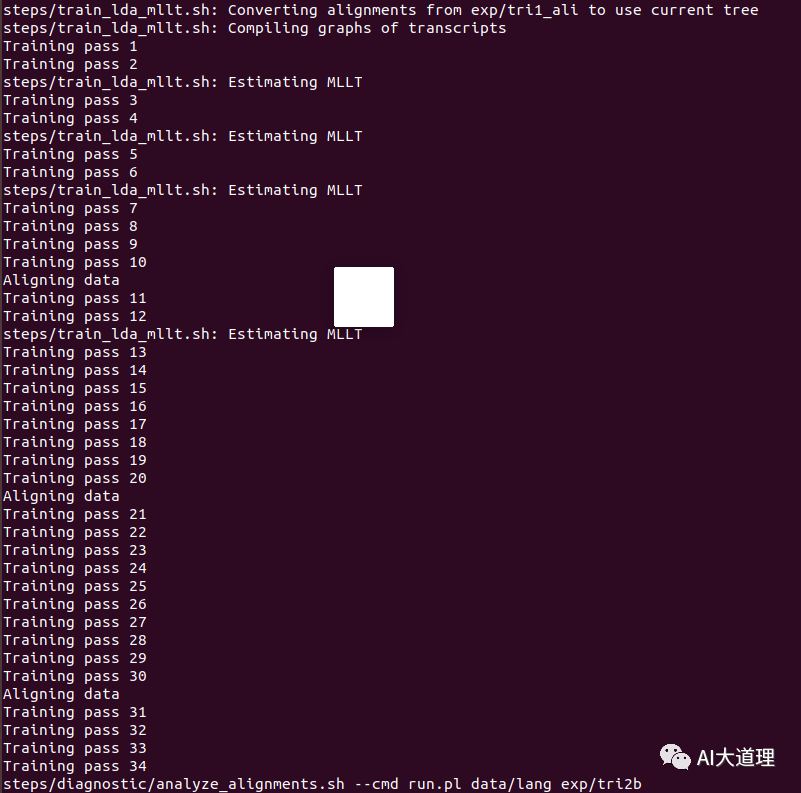
![]()
训练迭代次数num_iters=35。
训练完毕。
训练好的lda-mllt模型:
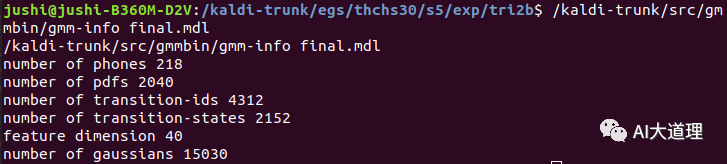
![]()
训练好的三音子模型:
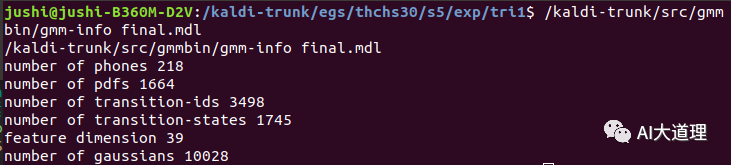
![]()
可见,特征维度变成40,而传统MFCC是39维的。
![]() 6.2 thchs-30_decode.sh
6.2 thchs-30_decode.sh
功能:
lda-mllt模型解码识别。
在解码时,由于mllt是全局变换,因此只需要使用训练过程中估计的矩阵进行特征变换即可。

![]()
lda-mllt模型部分解码识别(词级别):

![]()
真正结果(标签词):

![]()
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%。
可见词错误率继续下降,模型越来越好。

![]()
lda-mllt模型部分解码识别(音素级别):
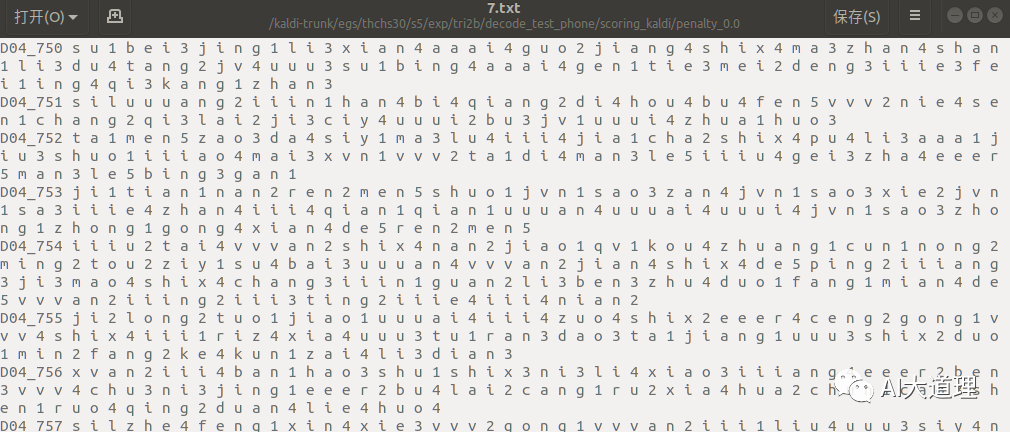
![]()
真正结果(标签音素):

![]()
单音素模型音素错误率为32.43%,三音素模型音素错误率为20.44%,lda-mllt模型音素错误率为17.06%。

![]()
![]() 6.3 align_si.sh
6.3 align_si.sh
功能:
对齐,为接下来的模型优化做准备。

![]()
对齐结果:
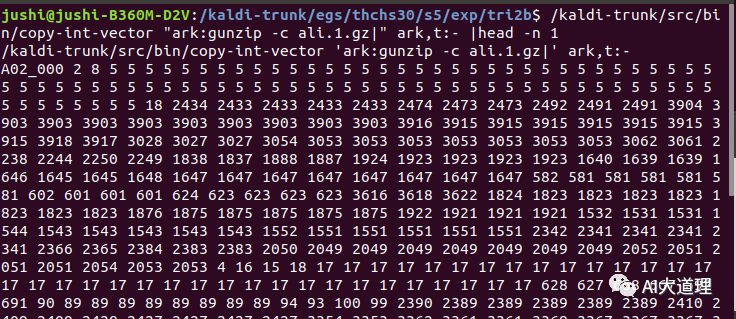
![]()
![]() 总结
总结
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%。
可见lda-mllt模型识别率继续有了一定的提高。
能否继续优化模型?又要从哪些方面入手进行优化呢?
说话人自适应技术将继续改善现有模型。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————