本文来自公众号“AI大道理”。
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%。
可见lda-mllt模型识别率继续有了一定的提高。
能否继续优化模型?又要从哪些方面入手进行优化呢?
说话人自适应技术将继续改善现有模型。
以kaldi的thchs30为例。

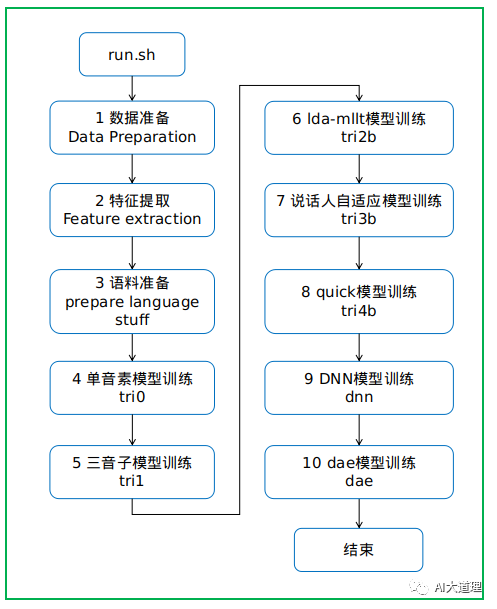
![]() 总过程
总过程
![]()
![]() 7 说话人自适应模型
7 说话人自适应模型
特征最大似然线性回归(fMLLT)用于说话人特定的特征变换。
STC输出一个矩阵,fMLLT输出的是按说话人索引的若干矩阵。
sat即speaker adaptive training,说话人自适应。
自适应的作用:补偿实际数据与已经训练的三音素模型中声学条件不匹配的问题,包括说话人特性(说话方式、口音等)及环境特性(如录音设备、房间混响等)。
可以简单的认为用每个说话人对应的fMLLR变换归一化后的特征尽量去除了说话人个性的部分,只尽量保留了最一般的与语音内容有关的特征,所以上层的声学模型可以用更少的参数更容易的进行建模。
所谓说话人自适应技术是利用特定说话人数据对说话人无关的码本进行改造,其目的是得到说话人自适应的码本来提升识别性能。
在某个说话人的训练数据足够多的时候,针对当前说话人数据采用传统的训练方法可以得到×说话人相关(Speaker Dependent, SD)的码本,由于SD码本很好的反应了当前说话人的特征,因此效果往往更好。
但实际中往往缺少足够的数据,因此采用说话人自适应,这样我们只需要很少量的数据就可以得到比较大的性能提升。
实质:是利用自适应数据调整SI码本以符合当前说话人特性。
在GMM-HMM模型中,自适应方法有特征空间变换和模型空间变换。
Kaldi中主要采用的是特征空间变换方法:LDA、MLLT和fMLLR,其本质都是在训练过程中估计变换矩阵,然后构造变换后的特征,再迭代训练新的声学模型参数。
MLLR 特征空间最大似然变换,针对特定的说话人,其码本可以用SI码本经过线性变换后的SA码本表示,即SA(SPeaker Adapted)码本中的任意均值矢量可以表示为:
SA = Ax + b
其中x表示N维SI码本的均值矢量,A为NN的线性变换矩阵,b表示偏移量,不同的均值矢量可以有不同的变换矩阵A。
fMLLR:求解A
-
估算变换矩阵A,从而更新SA码本。
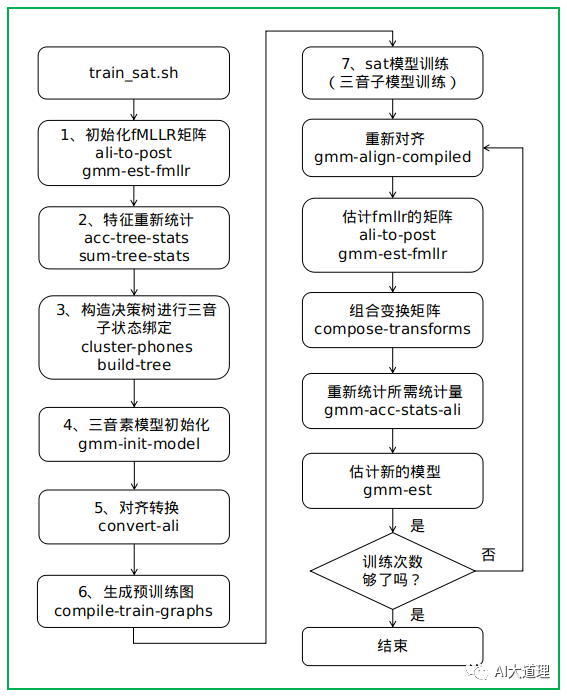
![]() 7.1 train_sat.sh
7.1 train_sat.sh
功能:
使用mfcc+cmvn+splice+LDA+fmllr特征,获得trans.JOB
主要是特征做fmllr变换,转换以后的特征重新训练GMM模型。
说话人自适应训练(SAT)也是如此,即针对fMLLR适应的功能进行训练。
可以在LDA + MLLT或增量和增量-增量功能之上完成此操作。
如果对齐目录中未提供任何转换,则它将在构建树之前估计转换本身(无论如何,在训练过程中,它将多次估计转换)。
过程之道:
![]()
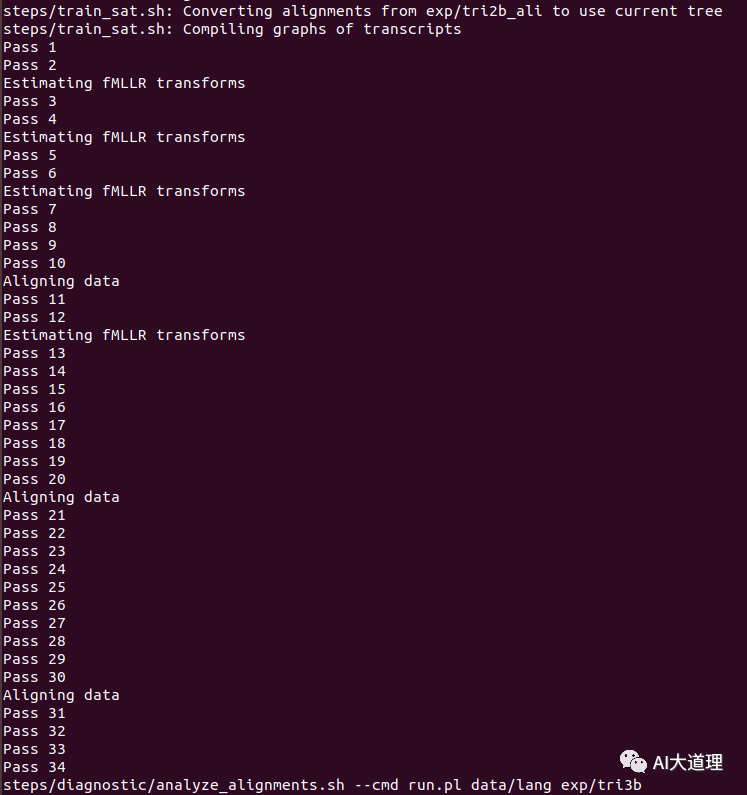
训练过程:
![]()
训练迭代次数num_iters=35。
训练完毕。
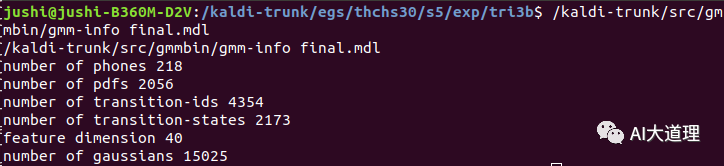
训练好的sat模型:
![]()
![]() 7.2 thchs-30_decode.sh
7.2 thchs-30_decode.sh
功能:
sat模型解码识别。
fMLLR矩阵需要在解码时估计。
先使用未变换的特征解码,根据解码的对齐结果估计fMLLR系数,然后进行特征变换,再进行最终的解码。

![]()
![]()
说话人自适应模型部分解码识别(词级别):

![]()
真正结果(标签词):

![]()
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,,说话人自适应模型词错误率为28.41%。
可见sat模型识别率继续提高。

![]()
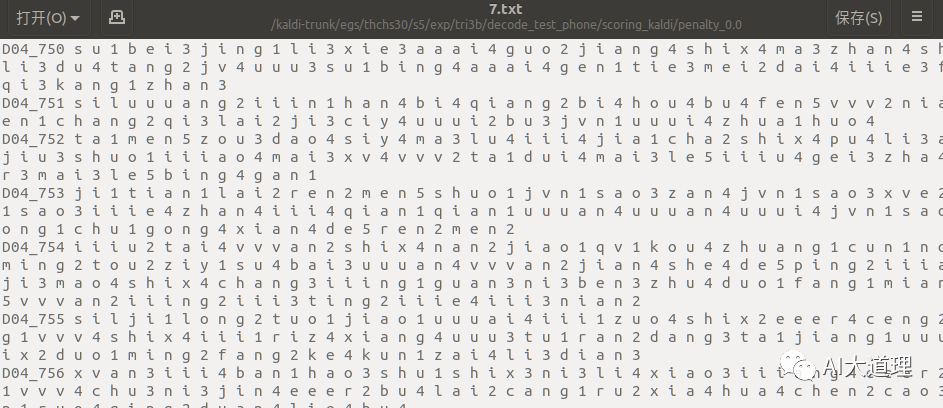
说话人自适应模型部分解码识别(音素级别):
![]()
真正结果(标签音素):

![]()
单音素模型音素错误率为32.43%,三音素模型音素错误率为20.44%,lda-mllt模型音素错误率为17.06%,说话人自适应模型音素错误率为14.98%。

![]()
![]() 7.3 align_fmllr.sh
7.3 align_fmllr.sh
功能:
对齐,为接下来的模型优化做准备。

![]()
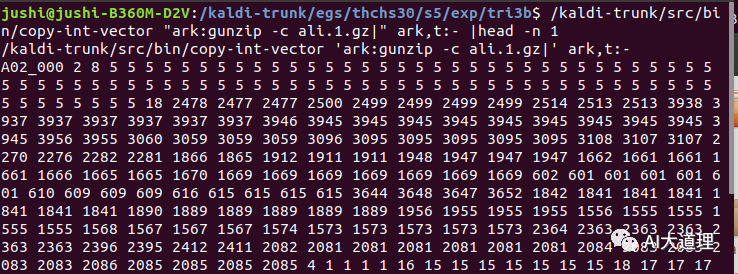
对齐结果:
![]()
![]() 总结
总结
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%。
可见说话人自适应模型识别率继续有了一定的提高。
能否继续优化模型?又要从哪些方面入手进行优化呢?
quick模型将继续改善现有模型。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
————————————————————