本文来自公众号“AI大道理”
YOLO v2 是 YOLO v1的进阶版,它没有彻底否定 YOLO v1,而是在 YOLO v1 的基础上,融合了很多其它论文优秀的思想做了大幅的提升。
YOLO v1 比较低的召回率和比较高的定位误差。
所以,让 YOLO v1变得更好指的是保持准确率的情况下:
-
提升召回率
-
降低定位误差

![]() YOLO v2的思想
YOLO v2的思想
1) Batch Normalization
Batch Norm 是一种很有效的正则化手段,所有的卷积层后面引入正则化。
作用:
对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。BN正是基于这个假设的实践,对每一层输入的数据进行加工。
在YOLOv2中,就是就是对网络的每一个卷积层的输入都做归一化,这样网络就不需要每层都去学数据的分布,收敛会更快。
神经网络每层输入的分布总是发生变化,加入BN,通过标准化上层输出,均衡输入数据分布,加快训练速度,提高了网络的收敛性。
输入标准化对应样本正则化,BN在一定程度上可以替代 Dropout解决过拟合问题。
-
mAP 提升了 2%
-
可以去掉了 Dropout 仍然不出现过拟合
2)高分辨率图像分类器(High Resolution Classifier)
用224*224的输入在ImageNet数据集训练分类网络,将所有训练数据循环跑160次。
将输入调整到448*448,再在ImageNet数据集上训练,将所有训练数据循环跑10次(10个epoch)。
然后利用预训练得到的模型在detection数据集上fine tuning。
这样训练得到的模型,在检测时用448*448的图像作为输入可以顺利检测。
通过对 YOLOv1 的模型进行 finetune,用 448*448 的图片尺寸训练了 10 epoches,主要目的是想让卷积核适应高分辨率。
这个步骤相当于做了减法,减轻了网络的学习任务,让它忽略图片尺寸的变化,专心应对目标检测任务。
这种尝试,让 mAP 涨了近 4 个点。
3)Anchor Box
首先将YOLOv1网络的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有更高的分辨率特征。
然后缩减网络,用416*416大小的输入代替原来的448*448,使得网络输出的特征图有奇数大小的宽和高,进而使得每个特征图在划分单元格(Cell)的时候只有一个中心单元格(Center Cell)。
YOLOv2通过引入Anchor Boxes,预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。
每个Cell可预测出9个Anchor Box,共13*13*9=1521个。
比YOLOv1预测的98个bounding box 要多很多,因此在定位精度方面有较好的改善。
YOLOv2使用了anchor boxes之后,每个位置的各个anchor box都单独预测一套分类概率值。
相比于精度的少许损失,召回率提升明显。
4)尺寸聚类
在引入 Anchor BOX 到 YOLO 的过程,遇到了 2 个问题。
第一个问题就是 Anchor BOX 的尺寸是手选的。
相比于人为指定 anchor box 的尺寸比例,YOLO 作者想到了一个自动化的手段,那就是选择 k-means 聚类手段。
在数据训练集中运行 k-means 算法,可以得到 k 个尺寸比例。
选择了 k=5,选择 5 的原因是在模型复杂度和召回率之间过一个平衡。
因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标
经实验,效果很不错,聚类出来的 anchor box 尺寸如下图所示:
![]()
5)定位预测
YOLOv2借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。
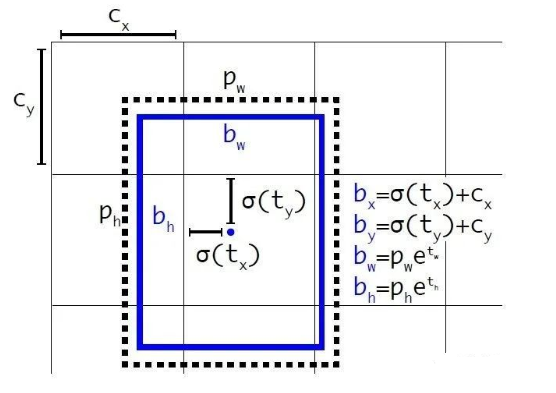
边界框的实际中心位置(x,y),需要根据预测的坐标偏移值(tx,ty),先验框的尺度(wa,ha)以及中心坐标(xa,ya)(特征图每个位置的中心点)来计算:

![]()
上面的公式是无约束的,预测的边界框很容易向任何方向偏移,如当tx=1时边界框将向右偏移先验框的一个宽度大小,而当tx=-1时边界框将向左偏移先验框的一个宽度大小,因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。
YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1),把边界框中心点约束在当前cell中。
根据边界框预测的4个offsetstx,ty,tw,th,可以按如下公式计算出边界框实际位置和大小:
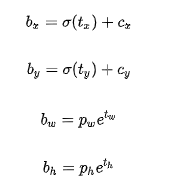
![]()
(cx,xy)为cell的左上角坐标,在计算时每个cell的尺度为1,所以当前cell的左上角坐标为((1,1)。
由于sigmoid函数的处理,边界框的中心位置会约束在当前cell内部,防止偏移过多。
而pw和ph是先验框的宽度与长度,它们的值也是相对于特征图大小的,在特征图中每个cell的长和宽均为1。
这里记特征图的大小为(W,H),可以将边界框相对于整张图片的位置和大小计算出来(4个值均在0和1之间)
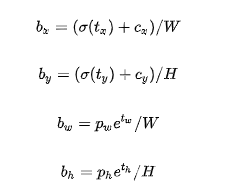
![]()
将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了,这就是YOLOv2边界框的整个解码过程。
约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值提升了约5%。
![]()
在引入 Anchor BOX 时还遭遇了第 2 个问题:模型的稳定性。
模型的不稳定性来源于坐标(x,y) 的预测。
6)细粒度特征
YOLOv2 刚开始使用 13x13 的 featuremap 做预测,对于大目标来说足够应付检测了,但是小目标却不行。
像其它的目标检测算法都会利用到空间信息,会利用特征图金字塔去覆盖不同层级的尺寸信息,比如 Faster R-CNN 和 SSD 都生成了多种尺寸featuremap。
但 YOLO 作者另辟蹊径,用了一个 passthrough 手段,简单来说就是从 26x26 的featuremap 中提取信息生成新的 featuremap ,然后和最后 13x13 的 featuremap 拼接起来。
passthrough 有点类似 ResNet 的 shortcut 的思路,都是从较前面的层次获取信息,这样网络就可以应付空间上不同层次的信息。
具体做法如下:
将 26 x 26 x 512 尺寸的 featuremap 进行跨行垮列抽样,然后生成 13 x 13 x 2048 的 featuremap,参数总量没有变,但是尺寸发生了改变,所以 YOLO 源码中称这样的操作为 reorg,相当于一个宽高换深度的重组。
基于这项尝试,YOLOv2 的模型提升了 1% 的效率。
7)多尺度训练
采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。
YOLO 作者不想让 YOLOv2 的模型只局限于 416x416 这单一尺寸的图片,所以训练过程当中,每经过 10 epoches 的训练,输入图像尺寸会发生变化。
因为 YOLOv2 的经过了 5 次下采样,缩小了 32 倍,所以,输入图像的尺寸都能被 32 整除 {320x320,352,…,608}。
多尺度训练使得 YOLOv2 可以在速度和精度上做一个很好的平衡。
低分辨率下,YOLOv2 的速度极快,228x228 的输入图片下,帧率可以到达 90 FPS,但精度和 Fast R-CNN 一致。
采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。
高分辨率下,YOLOv2 仍然可以达到实时要求。
![]() YOLO v2的网络结构
YOLO v2的网络结构
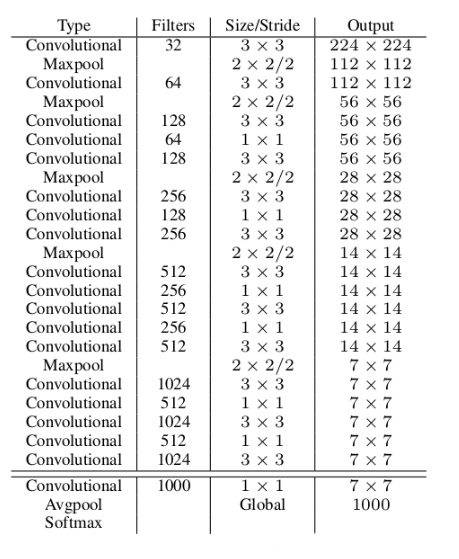
新的模型 Darknet-19。
YOLOv2 换了一个新的分类器。
Darknet-19 是基于 GoogLeNet 的架构,它比 VGG-16 快,原因在于它的前向推断只要 8.52 BFLOPs。
设计 Darknet-19 参考了很多同行经验。
基于 GoogLeNet 架构,借鉴 VGG 大量运用 3x3 filter,并且在每个 pool 层之后,将卷积核的个数翻倍。
借鉴 NIN 运用 global aveage pool,在 3x3 filter 之间插入 1x1 卷积层,
引入 Batch Normal 层。
Darknet-19 的结构如下:
![]()
![]() yolo v2 的损失函数
yolo v2 的损失函数
YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与ground truth的IOU最大的边界框预测它,而剩余的4个边界框不与该ground truth匹配。
YOLOv2同样需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。
与ground truth匹配的先验框计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的边界框只计算置信度误差(此时target为0)。
YOLOv2和YOLOv1的损失函数一样,为均方差函数。

![]()
我们来一点点解释,首先W,H分别指的是特征图(13*13)的宽与高,而A指的是先验框数目(这里是5)。
-
第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。
-
第二项是计算先验框与预测宽的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。
-
第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
![]() yolo v2 的训练
yolo v2 的训练
YOLOv2的训练主要包括三个阶段。
第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为224*224,共训练160个epochs。
第二阶段将网络的输入调整为448*448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个3*3*2014卷积层,同时增加了一个passthrough层,最后使用1*1卷积层输出预测结果,输出的channels数为:num_anchors*(5+num_classes),和训练采用的数据集有关系。
由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。
这里以VOC数据集为例,最终的预测矩阵为T(shape为(batch_size,13,13,125)),可以先将其reshape为(batch_size,13,13,5,25),其中T[:,:,:,:,0:4]为边界框的位置和大小(tx,ty,tw,th),T[:,:,:,:,4]为边界框的置信度,而T[:,:,:,:,5:]为类别预测值。
![]() 总结
总结
YOLOv2 是一个平衡了速度和准确度的模型,它通过一系列 tricks 让自己更快、更好、更强。

![]()
其中一个 tricks 让人眼前一亮,它用 k-means 去聚类数据集中的 label 尺寸从而得到 anchor box 尺寸。
这其实是一个很强的先验知识。
尽管提高了很多的性能,但YOLO v2并没有解决小目标检测不准的问题。
如何才能更加准确检测小目标呢?
YOLO v3给出了答案。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————