本文来自公众号“AI大道理”

![]() 为什么会有ResNet?
为什么会有ResNet?
神经网络叠的越深,则学习出的效果就一定会越好吗?
答案无疑是否定的,人们发现当模型层数增加到某种程度,模型的效果将会不升反降。
也就是说,深度模型发生了退化情况。
那么,为什么会出现这种情况?
按理说,当我们堆叠一个模型时,理所当然的会认为效果会越堆越好。
因为,假设一个比较浅的网络已经可以达到不错的效果,那么即使之后堆上去的网络什么也不做,模型的效果也不会变差。
然而事实上,这却是问题所在。
“什么都不做”恰好是当前神经网络最难做到的东西之一。
由于非线性激活函数Relu的存在,每次输入到输出的过程都几乎是不可逆的(信息损失)。
我们很难从输出反推回完整的输入。
也许赋予神经网络无限可能性的“非线性”让神经网络模型走得太远,却也让它忘记了为什么出发。
这也使得特征随着层层前向传播得到完整保留的可能性都微乎其微。
这种神经网络丢失的“不忘初心”/“什么都不做”的品质叫做恒等映射。
Residual Learning的初衷其实是让模型的内部结构至少有恒等映射的能力,以保证在堆叠网络的过程中,网络至少不会因为继续堆叠而产生退化!
![]() 残差学习 Residual Learning
残差学习 Residual Learning
如果深层网络后面的层都是是恒等映射,那么模型就可以转化为一个浅层网络。
那现在的问题就是如何得到恒等映射了。
事实上,已有的神经网络很难拟合潜在的恒等映射函数H(x) = x。
但如果把网络设计为H(x) = F(x) + x,即直接把恒等映射作为网络的一部分。
就可以把问题转化为学习一个残差函数F(x) = H(x) - x.
只要F(x)=0,就构成了一个恒等映射H(x) = x。
而且,拟合残差至少比拟合恒等映射容易得多。
于是,就有了Residual block结构
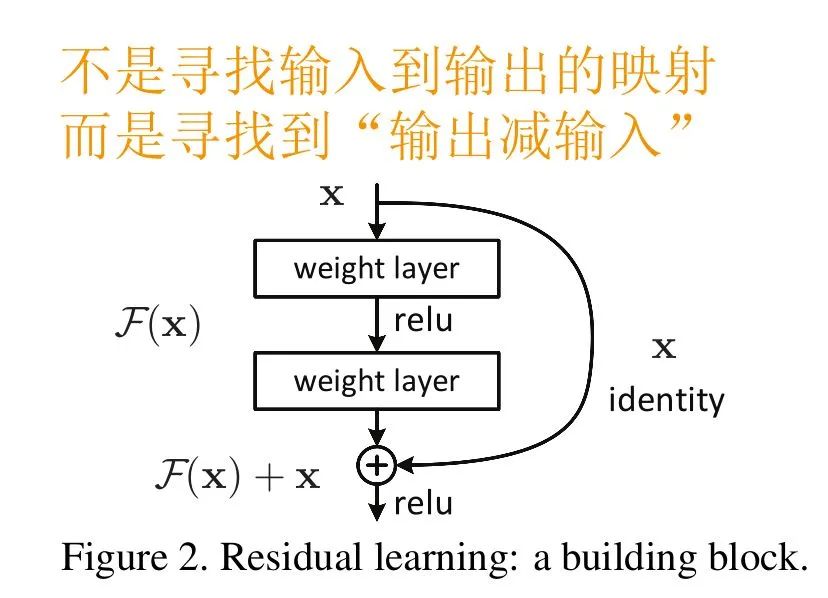
![]()
图中右侧的曲线叫做跳接(shortcut connection),通过跳接在激活函数前,将上一层或几层之前的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出。
用数学语言描述,假设Residual Block的输入为x,则输出y等于:
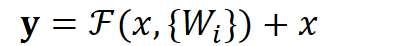
![]()
其中
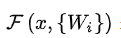
![]()
是我们学习的目标,即输出输入的残差 y-x 。
以上图为例,残差部分是中间有一个Relu激活的双层权重,即:
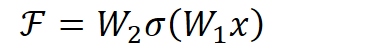
![]()
其中 a指代Relu,而 w1、w2指代两层权重。
这里一个Block中必须至少含有两个层,否则就会出现很滑稽的情况:
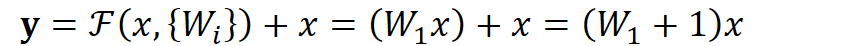
![]()
显然这样加了和没加差不多。
![]() 残差网络作用
残差网络作用
即使BN过后梯度的模稳定在了正常范围内,但梯度的相关性实际上是随着层数增加持续衰减的,而ResNet可以有效减少这种相关性的衰减。
对于“梯度弥散”观点来说,在输出引入一个输入x的恒等映射,则梯度也会对应地引入一个常数1,这样的网络的确不容易出现梯度值异常,残差网络起到了稳定梯度的作用。
跳连接相加可以实现不同分辨率特征的组合,因为浅层容易有高分辨率但是低级语义的特征,而深层的特征有高级语义,但分辨率就很低了。
引入跳接实际上让模型自身有了更加“灵活”的结构,即在训练过程本身,模型可以选择在每一个部分是“更多进行卷积与非线性变换”还是“更多倾向于什么都不做”,抑或是将两者结合。模型在训练便可以自适应本身的结构。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————