正则表达式
正则表达式是一种字符串,由普通字符和元字符组成
正则表达式的定义:
一种匹配字符串的规则
可以定制一个规则
1. 来确认一个字符串是够符合规则
2. 从大段的字符串中找到符合规则的内容
元字符:描述其他字符的特殊字符
字符类:正则表达式中可以使用字符类,一个字符类定义一组字符,其中的任一字符出现在输入字符串中即匹配成功,每次匹配只能匹配字符类中的一个字符
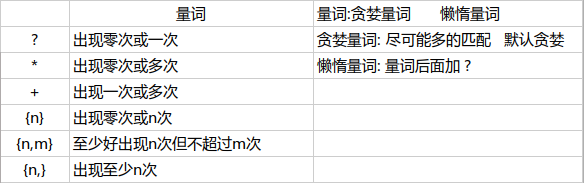
量词: 贪婪量词和懒惰量词
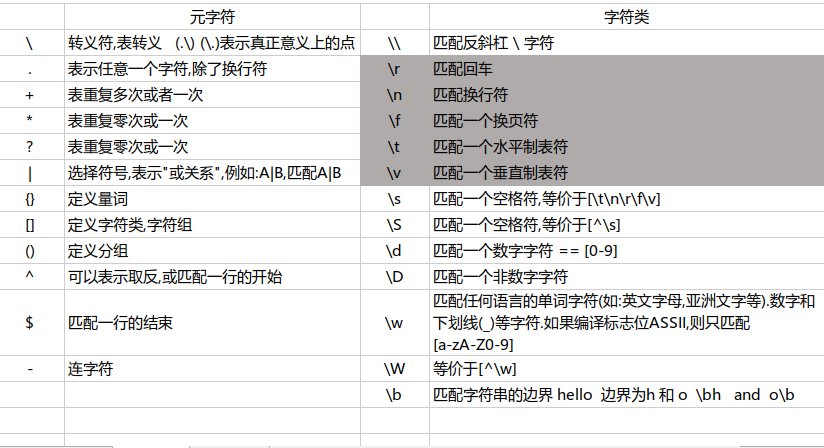
字符类取反,有时需要在正则表达式中不想看到某个字符
p = r'[^0123456789]'
字符类取反
数字的取反
p = r'D'
命名分组
在python程序中访问分组是,除了可以通过组编号进行访问,还可以通过组名进行访问前提是要在正则表达式中为组命名,组命名语法是在分组的左小括号后面添加?p<分组名>实现
反向引用分组
除了在程序代码中访问正则表达式匹配之后的分组内容,还可以在正则表达式内部引用之前的分组
<a>xxxxx</a>开始和结束,中间是内容
正常情况下是这样写的
但是这里要用上反向引用
# p = r'<([w]+)>.*</([w]+)>'
p = r'<([w]+)>.*</([/1]+)>'
m = re.search(p,'<a>abc</a>')
print(m)
非捕获分组
前面介绍的分组称为捕获分组,就是匹配子表达式结果被暂时保存到内存中,
以备表达式或其他程序引用,这称之为'捕获',捕获结果可以通过组编号或组名进行引用
但是有时候并不想引用子表达是的匹配结果,不想捕获匹配结果,只是将小括号作为一个整体进行匹配,
此时可以使用非捕获分组,非捕获分组在组开头使用 ?: 实现
re模块
python提供的正则表达式模块
search() 和 match()函数
search() 在输入字符串中查找,返回第一个匹配内容.如果找到一个match对象,如果没有找到就返回None
match() 在输入字符串开始查找匹配内容,如果找到一个match对象,如果没有找到返回None
两个函数都返回match对象, match对象是re提供的一种对象,叫匹配对象
findall() finditer() 函数
这两个函数非常相似
字符串分割:
split函数
分割出来的个数
re.split(pattern , string , maxsplit=0, flags=0)
正则表达式 编译的标志
p = r'd+'
text = 'AB12CD34EF'
clist = re.split(p,text)
print(clist)
字符串替换
字符串替换使用sub()函数,该函数替换匹配的子字符串,返回值是替换之后的字符串
re.sub(pattern, repl, string, count=0, flags=0)
p = r'd+'
text = 'AB12CD34EF'
repace_text = re.sub(p,'',text)
print(replace_text)
编译正则表达式:
complie() 函数可以编译正则表达式
re.comlile(pattern[,flag=0])
compile() 函数返回一个编译的正则表达式对象regex
search()
match()
findall()
finditer()
sub()
split()