1、ascii占1个字节,只支持英文;
2、bg2312占2个字节,只支持6700+汉字
3、gbk 是gb2312的升级版,支持21000+汉字
4、shift-jis日本字符
5、ks_c_5601-1987韩国编码
6、kis-620泰国编码 -------------即每个国家都有自己的字符,对应关系也涵盖了自己国家的字符但与其他国家无对应关系---------->unicode:涵盖了全球所有文字和二进制对应关系
unicode:支持全球所有语言,包含了跟全球所有国家编码的映射关系,但使用unicode表示一个字符太浪费空间,所有出现了UTF,UTF就是为了节省存储和网络传输时空间问题。
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符
UTF是为unicode编码设计的一种存在和传输时节省空间的编码方案。注:存储再硬盘时时何种编码,读取的时候就要使用何种编码读取。
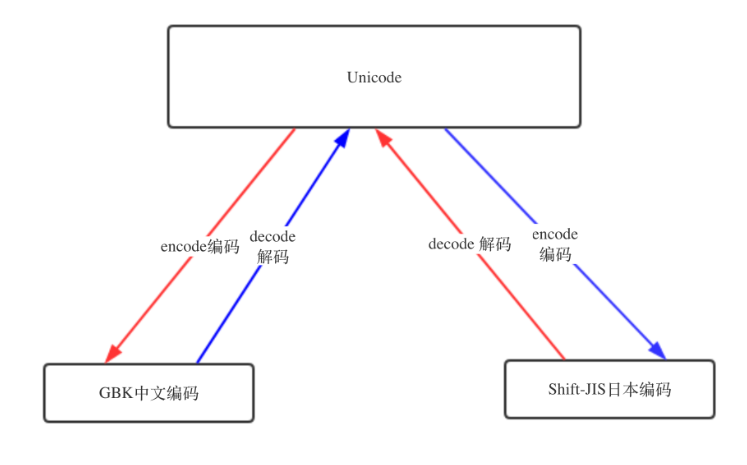
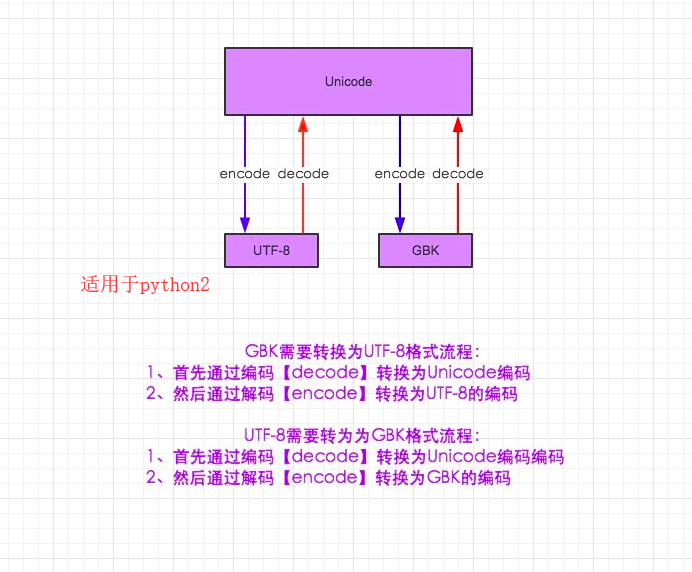
编码转换:可先转换为unicode编码然后再由unicode转化为其他编码
python3里python解释器会把utf-8转换为unicode(unicode是内存默认编码)。python2默认编码是ASCII,要写中文需要声明文件头的coding为utf-8 or gbk,python2解释器再以文件头的编码去解释代码加载到内存后并不会主动转为unicode。
decode解码
encode编码
UTF-8 -->decode 解码-->Unicode
Unicode-->encode编码-->GBK/UTF-8
python出现各种编码问题常见编码设置出错位置
Python解释器的默认编码
Python源文件文件编码
Terminal使用的编码
操作系统的语言设置
-----------参考网上资料主要是自己学习记录