机器学习笔记
一、机器学习的相关概念
模式识别是根据已有知识的表达,针对待识别模式,通过计算机用数学技术方法来判别所属的类别或是预测对应的回归值。环境与客体统称为“模式”。
根据任务,模式识别可以分为「分类」和「回归」两种形式。
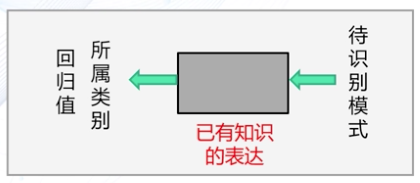
输入待识别模式,经过模式识别模型进行计算处理,输出其所属类别或回归值就是模式识别的过程,模式识别模型类似于数学上的(f(x))表达式。一个模式识别模型包含「特征提取」与「分类器」。
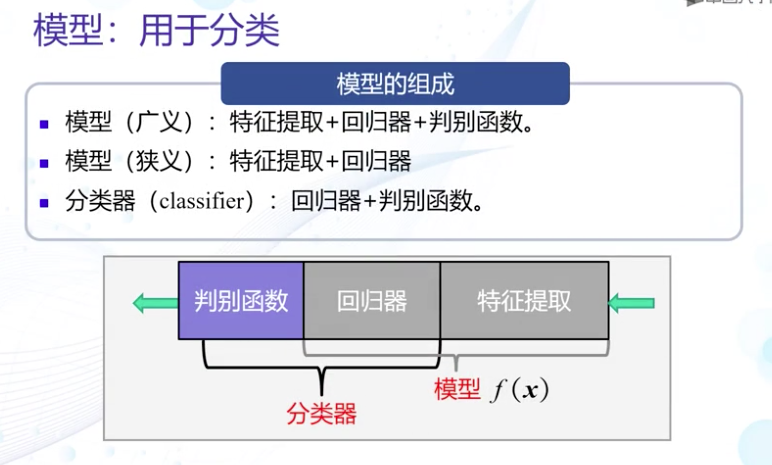
机器学习是人工智能的一个分支,是通过给定模式识别的初始模型,学习已有的特征知识以不断调整模型参数,最后获得更为准确的模式识别模型的过程,即利用机器学习的途径解决人工智能的问题。
样本是用于机器学习的现有知识的集合。根据真值的给定与否分为「标注的样本」和「未标注的样本」。机器学习的方法根据样本真值的给定与否分为「监督式学习」、「无监督式学习」和「半监督式学习」。近年也出现了新的机器学习方法,根据先后累计的多次决策动作判断决策的好坏,称为「强化学习」。
样本根据用途的不同还可以分为「训练样本」和「测试样本」。由于样本的有限性造成样本集合并不能完整表达所有模式,样本自身携带的噪声也会对模型的判断造成影响,这要求模型具有较好的泛化能力。泛化能力是指一个模型不仅对训练样本内的模式有判别能力,对于训练样本外的模式也要具有决策能力。训练获得的模型泛化能力低下则称为过拟合,可以选择复杂度适合的模型或通过加入正则项的方式提高模型的泛化能力。
二、特征的相关概念
特征的定义
特征是用于区分不同类别模式的可测量的量,具有「辨别能力」和「鲁棒性」两个特性。
特征向量是由多个特征构成的列向量,表示一个模式。

特征空间是特征在空间上的表达方式,坐标轴表示某一个特征,空间中的每个点表示一个模式,空间原点到点的向量表示该模式的特征向量。
特征的相关运算
- 点积
- (x cdot y = x^{T}y = y^{T}x = sum^{p}_{j=1}{x_{j}y_{j}})
- 点积的结果是一个标量表达
- 点积是一个线性变换
- 几何意义:(x cdot y = |x||y|cos heta)
- 点积为0则表示两个向量共线,称为正交
- 向量夹角
- (cos heta = frac{x cdot y}{|x||y|})
- 投影
- (x_{y} = |x|cos heta)
- (x_{y})称为x到y上的投影,是x在y方向上的长度(标量)
- 投影向量
- (x_{y} = |x|cos hetafrac{y}{|y|})
- (x_{y})称为x在y上的分解,是x在y方向上的向量
特征的相关性
由于每个特征向量表达一个模式,因此特征的相关性是度量模式之间是否相似的基础。
- 两个特征向量之间的夹角表示在方向上的差异性
- x到y上的投影表示x分解到y上的程度,能分解的越多说明两者越相似
- 残差向量
- (r_{x} = x-x_{y} = x-|x|cos hetafrac{y}{|y|})
- 残差向量表示x分解到y上的投影向量与原向量x的误差
- 欧氏距离
- (d(x,y) = (x-y)^{T}(x-y) = sum^{p}_{j=1}{(x_{j}-y_{j})^{2}})
- 表示两个特征向量的相似程度
三、机器学习的评估方法与性能指标
之前有提到样本根据用途的不同还可以分为「训练样本」和「测试样本」,测试样本通常用于评估模型的泛化能力。
在样本切割方法的基础上有「留出法」、「K折交叉验证法」和「留一法」三种常用的评估方法。留出法将数据随机划分为一定比例分别用于训练与测试,例如按7:3划分训练集与测试集,大样本训练集用于训练模型,小样本测试集用于评估模型性能,取量化指标的平均值作为评估结果;K折交叉验证将数据集分割成k份,并进行k次训练,每次训练从k份样本中选择k-1份组成训练集,剩下1份作为测试集评估模型性能,取k次训练测试的评估结果的平均值作为最终评估结果;留一法则是K折交叉验证的一种特殊情况,在留一法中K等于样本的大小N。
性能指标
- 测试误差
- 二类分类:真阳性(TP),假阳性(FP),真阴性(TN),假阴性(FN)
- 多类分类:每类各自为正,非自身为负
- 准确度:判断值与真值完全一致的占比
- (Accuracy=frac{TP+TN}{Sum})
- 精度:阳性样本的准确度
- (Precision = frac{TP}{TP+FP})
- 召回率(真阳率):所有阳性样本中被预测为阳性的比例
- (Recall = TPR = frac{TP}{TP+FN})
- 特异性
- (Specificity = frac{TN}{TN+FP})
- 假阳率
- (FPR = 1-Specificity = frac{FP}{TN+FP})
- F-Score:结合精度与召回率的指标
- (F = frac{(a^{2}+1) imes Precision imes Recall}{a^{2} imes Precision imes Recall})
- 取(a=1),有(F_{1} = frac{2 imes Precision imes Recall}{Precision imes Recall})
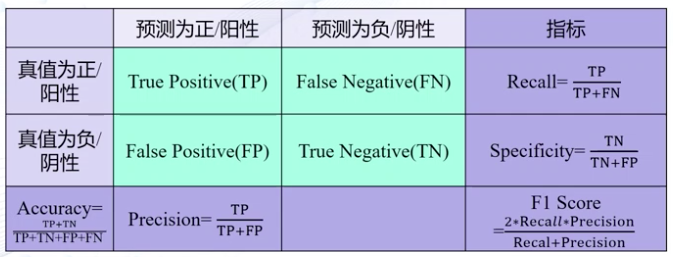
混淆矩阵

曲线度量
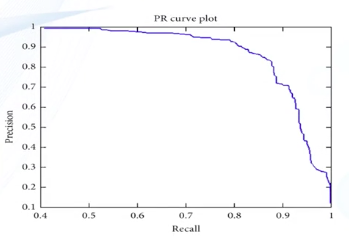
- PR曲线
- 横轴:召回率(Recall)数值
- 纵轴:精度(Precision)数值
- 理想性能:右上角(1,1)处
- 召回率与精度越大性能越好,即越往右上角凸越好
- ROC曲线
- 横轴:假阳率(FPR)数值
- 纵轴:真阳率(TPR)数值
- 理想性能:左上角(0,1)处
- FPR越小TPR越大性能越好,即越往左上角凸越好
- 对角线:随机预测模型的ROC曲线
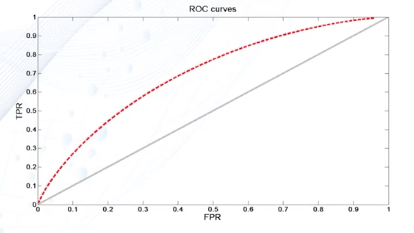
- AUC曲线下方面积
- 面积越大性能越好
- (AUC = 1)表示这是完美的模型
- (AUC > 0.5)表示这是较好的模型
- (AUC = 0.5)表示该模型与随机预测模型是等效的
- (AUC < 0.5)表示比随机预测模型还差