#4.8.py
import jieba
excludes = {"先生","没有","太太","一个","自己","小姐","我们","可是","她们","他们","知道","事情","时候"}
txt = open("傲慢与偏见.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
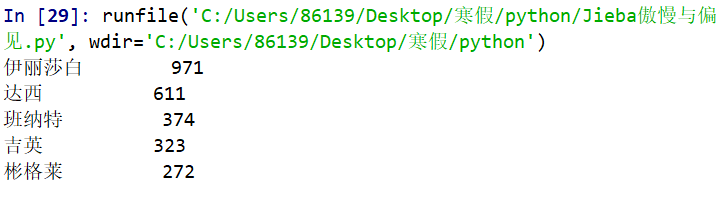
for i in range(5):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
#4.8.py
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
txt = open("傲慢与偏见.txt", "r", encoding='utf-8').read()
excludes = {"先生","没有","太太","一个","自己","小姐","我们","可是","她们","他们","知道","事情","时候"}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(5):
word, count = items[i]
wc = WordCloud(font_path = r'.simhei.ttf',background_color = 'white',width = 500,height = 350,max_font_size=50,min_font_size=10)
wc.generate(txt)
wc.to_file("wordcloud.png")
plt.figure('wordcloud.png')
plt.imshow(wc)
plt.axis('off')
plt.show()
