什么是多进程:同一时刻开启多个进程并发(并行)的执行
9.2.1 开启进程的两种方式:
# 开启进程的第一种方式
from multiprocessing import Process
import time
def task(name):
print(f'{name},来了老弟')
time.sleep(3)
print(f'{name},走了老弟')
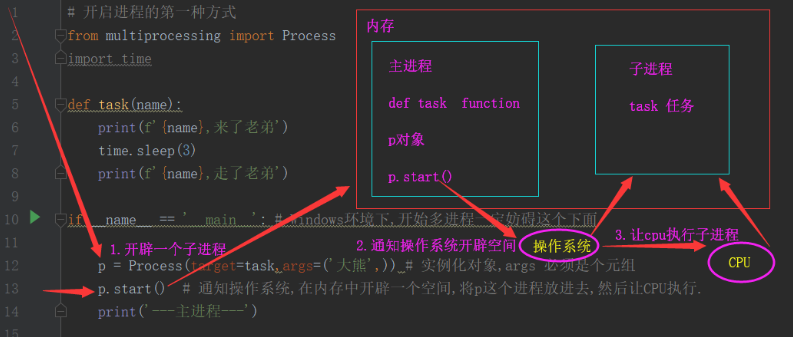
if __name__ == '__main__': # Windows环境下,开始多进程一定妨碍这个下面
p = Process(target=task,args=('大熊',)) # 实例化对象,args 必须是个元组
p.start() # 通知操作系统,在内存中开辟一个空间,将p这个进程放进去,然后让CPU执行.
print('---主进程---')
# 开启进程的第二种方式
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(f'{self.name},来了老弟')
# time.sleep(3)
print(f'{self.name},走了老弟')
if __name__ == '__main__':
p = MyProcess('Agoni')
p.start()
print('开始')
9.2.2 获取进程以及父进程的pid
进程在内存中开启多个,操作系统如何区分这些进程? -- 每个进程都有一个唯一标识.
如何查看进程的pid ?
-
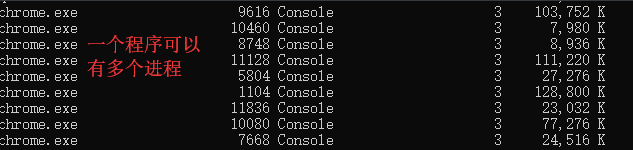
在终端查看进程的pid
命令: tasklist
-
在终端查看指定的进程pid
命令:
tasklist|findstr 进程名字

-
通过代码查看pid
import os print(f'子进程:{os.getpid()}') print(f'父进程:{os.getppid()}') # 每次执行一次,pid都会变
9.2.3 验证进程之间的数据隔离
from multiprocessing import Process
import time
num = 100
def func():
global num
num = 7
print(f'子程序:{num}') # num = 7
if __name__ == '__main__':
p = Process(target=func)
p.start()
time.sleep(1)
print(f'主进程:{num}') # num = 100
# 主进程中的num并没有随着子进程中num的改变而改变
# 验证子进程与父进程之间的空间隔离,要验证初始变量是否是一个id
from multiprocessing import Process
import time
num = 100
def func():
global num
num = 7
print(f'子程序:{id(num)}') 子程序:1463454928
if __name__ == '__main__':
print(f'主进程:{id(num)}') 主进程:1463454928
p = Process(target=func)
p.start()
time.sleep(1)
# 主进程与子进程中num的空间地址相同
9.2.4 join方法
join方法: 等待,主进程等待子进程结束之后,再执行
# 如此写验证了join并不是串行
from multiprocessing import Process
import time
def func(sec):
time.sleep(sec)
print(f'{sec}:子进程')
if __name__ == '__main__':
p1 = Process(target=func,args=(1,))
p2 = Process(target=func,args=(2,))
p3 = Process(target=func,args=(3,))
start_time = time.time()
p1.start()
p2.start()
p3.start()
# start只是通知一下操作系统,三个start几乎同一时刻发给操作系统
# p1, p2, p3 三个子进程运行的先后顺序不定
p1.join() # 执行时间为1秒
p2.join() # p1执行1秒,p2已经执行了1秒,
p3.join() # 在p1,p2的基础上,p3已经执行了2秒
# p1,p2,p3 几乎同时进行,最终时长为 3+秒
print(f'主进程{time.time()-start_time}') 主进程:3.162081241607666
# 用for循环优化上面代码
from multiprocessing import Process
import time
def func(sec):
time.sleep(sec)
print(f'{sec}:子进程')
p_l = []
if __name__ == '__main__':
start_time = time.time()
for i in range(1,4):
p = Process(target=func,args=(i,))
p.start()
p_l.append(p)
for i in p_l:
i.join()
print(f'主进程:{time.time() - start_time}')
# 串行
from multiprocessing import Process
import time
def func(sec):
time.sleep(sec)
print(f'{sec}:子进程')
if __name__ == '__main__':
p1 = Process(target=func,args=(1,))
p2 = Process(target=func,args=(2,))
p3 = Process(target=func,args=(3,))
start_time = time.time()
p1.start()
p1.join() # 执行完p1,继续往下执行主进程,等待1秒
p2.start()
p2.join() # 执行完p2,继续往下执行主进程,等待2秒
p3.start()
p3.join() # 执行完p3,继续往下执行主进程,等待3秒
print(f'主进程:{time.time()-start_time}') 主进程:6.392470598220825
9.2.5 进程对象的其他属性
from multiprocessing import Process
import time
def func(name):
print(f'来自火星的{name}')
time.sleep(3)
print(f'{name}走了')
if __name__ == '__main__':
p = Process(target=func,args=('Agoni',),name='方法1') # name给对象设置name属性
p.start()
# print(p.pid) # 获取进程的pid
# print(p.name)
p.terminate() # 终止子进程(立刻终止,子程序不会执行)
# terminate 与 start一样的工作原理: 都是通知操作系统终止或者开启一个子进程,内存中终止或者开启(耗费时间)
print(p.is_alive()) # 查看子程序是否存活
print('主程序...')
9.2.6 僵尸进程和孤儿进程
Linux(mac)会有这两个概念,Windows没有,面试会问
from multiprocessing import Process
import time
import os
def task(name):
print(f'{name} is running')
print(f'子进程开始了:{os.getpid()}')
time.sleep(50)
if __name__ == '__main__':
for i in range(10):
p = Process(target=task,args=('Agoni',))
p.start()
print(f'主进程开始了:{os.getpid()}')
僵尸进程
- 主进程是子进程的发起者,按理说,主进程不会管子进程是否结束,对于结束来说,两个进程没有任何联系.但是通过代码发现:主进程并没有结束,实际上你的主进程要等到所有的子进程结束之后,主进程再结束.所以此时的主进程称为 " 僵尸进程 " .
- 父进程为什么不关闭? 此时主进程形成了僵尸进程
- 内存中只包含:主进程的pid以及子进程的开启时间,结束时间,至于主进程的代码以及文件,数据库等等全部消失,因为主进程要进行收尸环节.
- 利用waitepid()方法,对所有的结束的子进程进行收尸.
孤儿进程
- 此时如果主进程由于各种原因,提前消失了,它下面的所有子进程都成为孤儿进程, init就会对孤儿进程进行回收.
- 孤儿进程无害,如果僵尸进程消失,init会对孤儿进程进行回收
- 父进程(僵尸进程)无限的开启子进程,递归的开启,子进程会越来越多,僵尸进程还没结束,导致进程会越来越多,占用内存.
9.2.7 守护进程
from multiprocessing import Process
import time
import os
def func(name):
print(f'{name}:子进程开始了')
print(f'子进程:{os.getpid()}')
time.sleep(100)
if __name__ == '__main__':
p = Process(target=func,args=('Agoni',))
p.daemon = True # 将子进程设置成守护进程,守护主进程,只要主进程结束,子进程就马上结束
p.start()
time.sleep(2)
print(f'主进程:{os.getpid()}')
9.2.8 进程互斥锁
多个进程共抢一个资源,要做到结果第一位,效率第二位.
牺牲效率,保证结果 -- 串行.
from multiprocessing import Process
from multiprocessing import Lock
import time
import random
def task1(lock):
print('task1') # 验证cpu遇到io切换了
lock.acquire()
print('task1: 开始打印')
time.sleep(random.randint(1, 3))
print('task1: 打印完成')
lock.release()
def task2(lock):
print('task2') # 验证cpu遇到io切换了
lock.acquire()
print('task2: 开始打印')
time.sleep(random.randint(1, 3))
print('task2: 打印完成')
lock.release()
def task3(lock):
print('task3') # 验证cpu遇到io切换了
lock.acquire()
print('task3: 开始打印')
time.sleep(random.randint(1, 3))
print('task3: 打印完成')
lock.release()
if __name__ == '__main__':
lock = Lock()
p1 = Process(target=task1,args=(lock,))
p2 = Process(target=task2,args=(lock,))
p3 = Process(target=task3,args=(lock,))
p1.start()
p2.start()
p3.start()
上锁:一定要是同一把锁,只能按照这个规律:上锁一次,解锁一次
互斥锁与join的区别/共同点?
- 共同点:都是完成了进程之间的串行
- 区别:join人为控制进程串行,互斥锁是随机的抢占资源,保证了公平性.
# 多进程原则上是不能互相通信的,它们在内存级别数据隔离的.不代表磁盘上数据隔离.
# 它们可以共同操作一个文件.
缺点
1.操作文件效率低
2.自己加锁很麻烦,很容易出现死锁,递归锁
# 模拟抢票系统
from multiprocessing import Process
from multiprocessing import Lock
import time
import json
import os
import random
def search():
time.sleep(random.random())
with open('db.json',mode='r',encoding='utf-8') as f:
dic = json.load(f)
print(f'剩余票数{dic["count"]}')
def get():
with open('db.json', mode='r', encoding='utf-8') as f:
dic = json.load(f)
time.sleep(random.randint(1,3))
if dic['count'] >= 1:
dic['count'] -= 1
with open('db.json',mode='w',encoding='utf-8') as f:
json.dump(dic,f)
print(f'{os.getpid()}用户购买成功')
else:
print('暂无余票')
def task(lock):
search()
lock.acquire()
get()
lock.release()
if __name__ == '__main__':
lock = Lock()
for i in range(5):
p = Process(target=task,args=(lock,))
p.start()
9.2.9 进程之间的通信:队列
什么是队列? --> 队列就是存在于内存中的一个容器,最大的一个特点:队列的特性就是FIFO,完全支持先进先出的原则
进程批次之间互相隔离,要实现进程间通信(IPC),multiprocessing模块中的队列方式可以实现
创建队列的类(底层就是一管道和锁定的方式实现)
Queue([maxsize]) : 创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实多进程之间的数据传递
from multiprocessing import Queue
q = Queue(3)
q.put(1)
q.put(2)
q.put(3)
# q.put(4) # 当队列数据已经达到上限,再插入数据的时候,程序就会夯住
print(q.get())
print(q.get())
print(q.get())
print(q.get()) # 当队列中的数据取完之后,程序也会夯住
- maxsize() q = Queue(3) 数据量不易过大,队列主要存放精简的重要的数据
- block 默认值是True,当你插入的数据量超过最大限度,默认阻塞,如果block = False 数据超过最大限度,不阻塞了直接报错.
- timeout = 3 延时报错,超过3秒再不put数据,就会报错
# 用进程通信队列模拟实例
from multiprocessing import Process
from multiprocessing import Queue
import os
def task(q):
try:
q.put(f'{os.getpid()}',block=False)
except Exception:
return
if __name__ == '__main__':
q = Queue(10)
for i in range(100):
p = Process(target=task,args=(q,))
p.start() # 给CPU发送命令,开启子进程会有一定时间的延迟,在这个时间段内,主进程会继续执行
for i in range(1,11): # 如果循环次数再多,会取到更多的值
print(f'排名为{i}的用户:{q.get()}')
9.2.10 生产者消费者模型
模型:设计模式.归一化设计,理论等教给你一个变成思路,如果以后遇到类似的情况,直接套用即可.
生产者消费者模型:在并发编程中使用生产设和消费者模式能够解决大多数并发问题.该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度.
主体有三个: 生产者: 产生数据的地方, 消费者: 对数据使用加工地方. 容器: 队列.
对生产者消费者解耦,平衡了生产力和消费力.多用于解决并发的情况.
为什么要使用生产者和消费者模型?
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
生产者 --> 容器 --> 消费者
为什么要夹杂这个容器?
如果没有容器,生产者与消费者增强耦合性,不合理.所以要有一个容器,缓冲区,平衡生产力和消费力.
生产者消费者模型:合理的去调控多个进程去生成数据以及提取数据,中间有个必不可少的环节容器队列.
from multiprocessing import Process
from multiprocessing import Queue
import time
import random
def producer(q,name):
for i in range(1,6):
time.sleep(random.randint(1,3))
res = f'{i}号包子'
q.put(res)
print(f'�33[1;34m生产者{name}:生产{res} �33[0m')
def consumer(q,name):
while 1:
try:
time.sleep(random.randint(1,3))
ret = q.get(timeout=5)
print(f'�33[1;31m消费者{name}:吃了{ret} �33[0m')
except Exception:
return
if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer,args=(q,'Agoni'))
p2 = Process(target=consumer,args=(q,'Lucky'))
p1.start()
p2.start()