3月18日
4744【BZOJ1123】四维偏序
四维偏序模板。
思路就是先 cdq 分治给原来的点的第一维打上 (L/R) 的标记,然后正常的三维偏序即可(但是要注意的是这里多了 (L/R) 的判断。)
具体见代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=2e5+5,LEFT=-1,RIGHT=1;
int n,m,k,Cnt,Acnt,c[N];
#define ll long long
ll Ans;
struct Query{int d1,d2,d3,d4,part,val;}Q[N],Q1[N],Q2[N];
void Add(int x,int v){for(;x<=n;x+=(x&(-x))) c[x]+=v;}
int Ask(int x){int res=0;for(;x;x-=(x&(-x))) res+=c[x];return res;}
void Clear(int x){for(;x<=n;x+=(x&(-x))) c[x]=0;return ;}
inline bool CmpD1(Query a,Query b){return a.d1<b.d1;}
inline bool CmpD2(Query a,Query b){return a.d2<b.d3;}
inline bool CmpD3(Query a,Query b){return a.d3<b.d3;}
inline bool CmpD4(Query a,Query b){return a.d4<b.d4;}
void CDQ_Divide_3D(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide_3D(l,mid),CDQ_Divide_3D(mid+1,r);
int posl=l,posr=mid+1,pos=l;
while(posl<=mid&&posr<=r){
if(Q1[posr].d3>=Q1[posl].d3){
if(Q1[posl].part==LEFT) Add(Q1[posl].d4,Q1[posl].val);
Q2[pos++]=Q1[posl++];
}
else{
if(Q1[posr].part==RIGHT) Ans+=Ask(Q1[posr].d4);
Q2[pos++]=Q1[posr++];
}
}
while(posl<=mid) Q2[pos++]=Q1[posl++];
while(posr<=r){
if(Q1[posr].part==RIGHT) Ans+=Ask(Q1[posr].d4);
Q2[pos++]=Q1[posr++];
}
for(int i=l;i<=r;i++){
if(Q2[i].part==LEFT) Clear(Q2[i].d4);
Q1[i]=Q2[i];
}
return ;
}
void CDQ_Divide_2D(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide_2D(l,mid),CDQ_Divide_2D(mid+1,r);
int posl=l,posr=mid+1,pos=l;
while(posl<=mid&&posr<=r){
if(Q[posr].d2>=Q[posl].d2) Q[posl].part=LEFT,Q1[pos++]=Q[posl++];
else Q[posr].part=RIGHT,Q1[pos++]=Q[posr++];
}
while(posl<=mid) Q[posl].part=LEFT,Q1[pos++]=Q[posl++];
while(posr<=r) Q[posr].part=RIGHT,Q1[pos++]=Q[posr++];
for(int i=l;i<=r;i++) Q[i]=Q1[i];
CDQ_Divide_3D(l,r);
return ;
}
int main(){
read(n);
for(int i=1;i<=n;i++) Q[i].d1=i,Q[i].val=1;
for(int i=1;i<=n;i++) read(Q[i].d2);
for(int i=1;i<=n;i++) read(Q[i].d3);
for(int i=1;i<=n;i++) read(Q[i].d4);
CDQ_Divide_2D(1,n);
write(Ans);
return 0;
}
5645【HDU5126】四维偏序4D Partial Order
5645【HDU5126】四维偏序4D Partial Order
四维数点。
就是四维偏序+前缀和技巧。
注意:这道题的意义在于,我们知道了 cdq 分治对于时间离线上面的应用,对于每个点我们通过打四个标记实现了询问,而且再通过贡献标记实现了分开询问于查询的点。
还有就是要离散化。
剩下的看代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=2e5+5,LEFT=-1,RIGHT=1;
int n,m,k,Cnt,Acnt,idx,c[N],b[N],Ans[N];
#define ll long long
struct Query{int d1,d2,d3,d4,part,val,id;}Q[N],Q1[N],Q2[N];
void Add(int x,int v){if(x==0||v==0) return ; for(;x<=idx;x+=(x&(-x))) c[x]+=v;}
int Ask(int x){int res=0;for(;x;x-=(x&(-x))) res+=c[x];return res;}
void Clear(int x){if(x==0) return ; for(;x<=idx;x+=(x&(-x))) c[x]=0;return ;}
inline bool CmpD1(Query a,Query b){return a.d1<b.d1;}
inline bool CmpD2(Query a,Query b){return a.d2<b.d3;}
inline bool CmpD3(Query a,Query b){return a.d3<b.d3;}
inline bool CmpD4(Query a,Query b){return a.d4<b.d4;}
void CDQ_Divide_3D(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide_3D(l,mid),CDQ_Divide_3D(mid+1,r);
int posl=l,posr=mid+1,pos=l;
while(posl<=mid&&posr<=r){
if(Q1[posr].d3>=Q1[posl].d3){
if(Q1[posl].part==LEFT) Add(Q1[posl].d4,Q1[posl].val);
Q2[pos++]=Q1[posl++];
}
else{
if(Q1[posr].part==RIGHT) Ans[Q1[posr].id]+=Ask(Q1[posr].d4);
Q2[pos++]=Q1[posr++];
}
}
while(posl<=mid) Q2[pos++]=Q1[posl++];
while(posr<=r){
if(Q1[posr].part==RIGHT) Ans[Q1[posr].id]+=Ask(Q1[posr].d4);
Q2[pos++]=Q1[posr++];
}
for(int i=l;i<=r;i++){
if(Q2[i].part==LEFT) Clear(Q2[i].d4);
Q1[i]=Q2[i];
}
return ;
}
void CDQ_Divide_2D(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide_2D(l,mid),CDQ_Divide_2D(mid+1,r);
int posl=l,posr=mid+1,pos=l;
while(posl<=mid&&posr<=r){
if(Q[posr].d2>=Q[posl].d2) Q[posl].part=LEFT,Q1[pos++]=Q[posl++];
else Q[posr].part=RIGHT,Q1[pos++]=Q[posr++];
}
while(posl<=mid) Q[posl].part=LEFT,Q1[pos++]=Q[posl++];
while(posr<=r) Q[posr].part=RIGHT,Q1[pos++]=Q[posr++];
for(int i=l;i<=r;i++) Q[i]=Q1[i];
CDQ_Divide_3D(l,r);
return ;
}
int T;
signed main(){
read(T);
while(T--){
memset(Ans,0,sizeof(Ans));
read(n);int top;Cnt=Acnt=top=0;
for(int i=1,op,x,y,z,x1,y1,z1;i<=n;i++){
read(op);
if(op==1){
read(x),read(y),read(z);
Q[++Cnt]=Query{i,x,y,z,0,1,0};b[++top]=z;
}
else{
read(x),read(y),read(z),read(x1),read(y1),read(z1);
Q[++Cnt]=Query{i,x-1,y-1,z-1,0,0,++Acnt};//-
Q[++Cnt]=Query{i,x1,y-1,z-1,0,0,++Acnt};//+
Q[++Cnt]=Query{i,x-1,y1,z-1,0,0,++Acnt};//+
Q[++Cnt]=Query{i,x-1,y-1,z1,0,0,++Acnt};//+
Q[++Cnt]=Query{i,x1,y1,z-1,0,0,++Acnt};//-
Q[++Cnt]=Query{i,x1,y-1,z1,0,0,++Acnt};//-
Q[++Cnt]=Query{i,x-1,y1,z1,0,0,++Acnt};//-
Q[++Cnt]=Query{i,x1,y1,z1,0,0,++Acnt};//+
b[++top]=z,b[++top]=z1,b[++top]=z-1;
}
}
sort(b+1,b+top+1);
idx=unique(b+1,b+top+1)-b-1;
for(int i=1;i<=Cnt;i++) Q[i].d4=lower_bound(b+1,b+idx+1,Q[i].d4)-b;
sort(Q+1,Q+Cnt+1,CmpD1);
CDQ_Divide_2D(1,Cnt);
for(int i=1;i+7<=Acnt;i+=8){
write(Ans[i+1]+Ans[i+2]+Ans[i+3]+Ans[i+7]-Ans[i]-Ans[i+4]-Ans[i+5]-Ans[i+6]);
puts("");
}
}
return 0;
}
P5621 [DBOI2019]德丽莎世界第一可爱(四维偏序+dp)
P5621 [DBOI2019]德丽莎世界第一可爱(四维偏序+dp)
三倍经验,见下文。
P3769 [CH弱省胡策R2]TATT
也是三倍经验,就是下面一道题的权值贡献改为 1 。
P4849 寻找宝藏
首先,容易发现就是我们对每一个宝藏进行 dp 。
那么转移很好写,就是 (dp_i=max_{x_jleq x_i,y_jleq y_i,z_jleq z_i}{dp_j}+val_i)
我们考虑维护偏序关系,使用经典的四维偏序进行转移。
然后就是 sort+cdq+cdq+BIT ,转移就是树状数组一边维护 (max) 一边维护 (num) 的值。
注意的点:这里的 cdq 分治一定要记得还原,因为我们写的是中序遍历的形式,而且还有因为是 dp 所以我们写中序遍历,中序遍历的意义就是在统计当前答案的时候,要求前面的值必须全部更新完这个点的值的时候。
同时还要注意离散化,还有就是 cdq 分治的排序一定要彻底!!
具体见代码。
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define ll long long
const int N=2e5+5,LEFT=-1,RIGHT=1,MOD=998244353;
int n,m,k,Cnt,Acnt,idx,top;
ll Ans,NNum,dp[N],a[N],b[N],c[N];
int d[N],Num[N];
int inc(int x,int y){return x+y>=MOD?x+y-MOD:x+y;}
int dec(int x,int y){return x-y<0?x-y+MOD:x-y;}
struct Query{ll d1,d2,d3,d4,val;int part,id;}Q[N],Q1[N],Q2[N];
void Add(int x,ll v,int num){
for(;x<=idx;x+=(x&(-x))){
if(c[x]<v) d[x]=num,c[x]=v;
else if(c[x]==v) d[x]=inc(d[x],num);
}
return ;
}
ll AskMax(int x){ll res=0;for(;x;x-=(x&(-x))) res=max(res,c[x]);return res;}
int AskNum(int x){
ll res=0;int num=0;
for(;x;x-=(x&(-x))){
if(c[x]>res) res=c[x],num=d[x];
else if(c[x]==res) num=inc(num,d[x]);
}
return num;
}
void Clear(int x){for(;x<=idx;x+=(x&(-x))) c[x]=d[x]=0;return ;}
inline bool CmpD1(Query a,Query b){
if(a.d1!=b.d1) return a.d1<b.d1;
if(a.d2!=b.d2) return a.d2<b.d2;
if(a.d3!=b.d3) return a.d3<b.d3;
return a.d4<b.d4;
}
inline bool CmpD2(Query a,Query b){
if(a.d2!=b.d2) return a.d2<b.d2;
if(a.d3!=b.d3) return a.d3<b.d3;
if(a.d4!=b.d4) return a.d4<b.d4;
return a.d1<b.d1;
}
inline bool CmpD3(Query a,Query b){
if(a.d3!=b.d3) return a.d3<b.d3;
if(a.d4!=b.d4) return a.d4<b.d4;
if(a.d1!=b.d1) return a.d1<b.d1;
return a.d2<b.d2;
}
inline bool CmpD4(Query a,Query b){
if(a.d4!=b.d4) return a.d4<b.d4;
if(a.d1!=b.d1) return a.d1<b.d1;
if(a.d2!=b.d2) return a.d2<b.d2;
return a.d3<b.d3;
}
void CDQ_Divide_3D(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide_3D(l,mid);
for (int i=l;i<=r;i++) Q2[i]=Q1[i];
sort(Q2+l,Q2+mid+1,CmpD3),sort(Q2+mid+1,Q2+r+1,CmpD3);
for(int i=mid+1,j=l;i<=r;i++){
while(Q2[i].d3>=Q2[j].d3&&j<=mid){
if(Q2[j].part==LEFT) Add(Q2[j].d4,dp[Q2[j].id],Num[Q2[j].id]);
j++;
}
if(Q2[i].part==RIGHT){
ll tmp=AskMax(Q2[i].d4)+Q2[i].val;
if(tmp>dp[Q2[i].id]) dp[Q2[i].id]=tmp,Num[Q2[i].id]=AskNum(Q2[i].d4);
else if(tmp==dp[Q2[i].id]) Num[Q2[i].id]=inc(Num[Q2[i].id],AskNum(Q2[i].d4));
}
}
for(int i=l;i<=mid;i++) if(Q2[i].part==LEFT) Clear(Q2[i].d4);
CDQ_Divide_3D(mid+1,r);
return ;
}
void CDQ_Divide_2D(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide_2D(l,mid);
for(int i=l;i<=r;i++) Q1[i]=Q[i],Q1[i].part=(i<=mid?-1:1);
sort(Q1+l,Q1+r+1,CmpD2);
CDQ_Divide_3D(l,r);
CDQ_Divide_2D(mid+1,r);
return ;
}
signed main(){
read(n),read(m);
for(int i=1;i<=n;i++) read(Q[i].d1),read(Q[i].d2),read(Q[i].d3),read(Q[i].d4),read(a[i]),Q[i].id=i,b[++top]=Q[i].d4,Q[i].val=a[i],Num[i]=1;
sort(b+1,b+top+1);idx=unique(b+1,b+top+1)-b-1;
for(int i=1;i<=n;i++) Q[i].d4=lower_bound(b+1,b+idx+1,Q[i].d4)-b;
sort(Q+1,Q+n+1,CmpD1);top=0;
for(int i=1;i<=n;i++){
if(Q[i].d1==Q[i-1].d1&&Q[i].d2==Q[i-1].d2&&Q[i].d3==Q[i-1].d3&&Q[i].d4==Q[i-1].d4) Q[top].val+=Q[i].val;
else Q[++top]=Q[i],Q[top].id=top;
}
n=top;for(int i=1;i<=n;i++) dp[i]=Q[i].val;
CDQ_Divide_2D(1,n);
for(int i=1;i<=n;i++){
if(dp[i]>Ans) Ans=dp[i],NNum=Num[i];
else if(dp[i]==Ans) NNum=inc(NNum,Num[i]);
}
write(Ans),putchar('
'),write(NNum);
return 0;
}
P2717 寒假作业(二维偏序)
首先把数组 (A) 减掉一个 (k) 。
于是问题就变成了询问:

其中 (sum) 是前缀和。
那么就是一个二维偏序了。
3月19日
P3157 [CQOI2011]动态逆序对 & UVA11990 ‘’Dynamic'' Inversion(三维偏序)
P3157 [CQOI2011]动态逆序对 & UVA11990 ‘’Dynamic'' Inversion(三维偏序)
首先逆序对是一个经典的二维偏序问题,那么我们把这里所谓的删除操作反过来,看成添加操作的时间轴,我们就可以把整个问题看成一个三维偏序了。
那么维度就是 ((t,pos,val)) 注意还要离散化,还有就是对于每个新进来的点要算两遍贡献,具体见代码。
#include<bits/stdc++.h>
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
using namespace std;
const int N=4e5+10;
#define ll long long
int n,m,t[N],c[N];
ll ans[N],Ans[N],sum;
void Add(int x,int v){for(;x<=n;x+=(x&(-x))) c[x]+=v;return ;}
int Ask(int x){int res=0;for(;x;x-=(x&(-x))) res+=c[x];return res;}
void Clear(int x){for(;x<=n;x+=(x&(-x))) c[x]=0;return ;}
struct Query{int d1,d2,d3,id;}Q[N];
inline bool CmpD1_S(Query x,Query y){
if(x.d1!=y.d1) return x.d1<y.d1;
if(x.d2!=y.d2) return x.d2<y.d2;
return x.d3<y.d3;
}
inline bool CmpD1_B(Query x,Query y){
if(x.d1!=y.d1) return x.d1>y.d1;
if(x.d2!=y.d2) return x.d2<y.d2;
return x.d3<y.d3;
}
inline bool CmpD2(Query x,Query y){
if(x.d2!=y.d2) return x.d2<y.d2;
if(x.d3!=y.d3) return x.d3<y.d3;
return x.d1<y.d1;
}
inline bool CmpD2_B(Query x,Query y){
if(x.d2!=y.d2) return x.d2>y.d2;
if(x.d3!=y.d3) return x.d3>y.d3;
return x.d1>y.d1;
}
void CDQ_Divide1(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide1(l,mid),CDQ_Divide1(mid+1,r);
sort(Q+l,Q+mid+1,CmpD2),sort(Q+mid+1,Q+r+1,CmpD2);
for(int i=mid+1,j=l;i<=r;i++){
while(Q[i].d2>=Q[j].d2&&j<=mid) Add(Q[j].d3,1),j++;
Ans[Q[i].id]+=Ask(n)-Ask(Q[i].d3);
}
for(int i=l;i<=r;i++) Clear(Q[i].d3);
return ;
}
void CDQ_Divide2(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide2(l,mid),CDQ_Divide2(mid+1,r);
sort(Q+l,Q+mid+1,CmpD2_B),sort(Q+mid+1,Q+r+1,CmpD2_B);
for(int i=l,j=mid+1;i<=mid;i++){
while(Q[i].d2<=Q[j].d2&&j<=r) Add(Q[j].d3,1),j++;
Ans[Q[i].id]+=Ask(Q[i].d3-1);
}
for(int i=l;i<=r;i++) Clear(Q[i].d3);
return ;
}
int main(){
read(n),read(m);
for(int i=1;i<=n;i++) Q[i].d1=i,Q[i].d2=i,read(Q[i].d3),t[Q[i].d3]=i,Q[i].id=0;
for(int i=1,x;i<=m;i++) read(x),Q[t[x]].d1=m+1+n-i,Q[t[x]].id=m+1-i;
sort(Q+1,Q+n+1,CmpD1_S);
CDQ_Divide1(1,n);
sort(Q+1,Q+n+1,CmpD1_B);
CDQ_Divide2(1,n);
sort(Q+1,Q+n+1,CmpD1_S);int top=-1;
for(int i=0;i<=m;i++) sum+=Ans[i],ans[++top]=sum;
for(int i=m;i>=1;i--) write(ans[i]),putchar('
');
return 0;
}
CF762E Radio stations(三维偏序)
留着写题解。
CF1045G AI robots(三维偏序)
双倍经验,上一题离散化版本。
CF848C Goodbye Souvenir(三维偏序+离线操作)
CF848C Goodbye Souvenir(三维偏序+离线操作)

代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e5+5;
#define ll long long
int n,Cnt,T,q,pos[N],cnt,Top;
ll Ans[N],c[N];
set<int>S[N];
struct Query{ll x,y,id,f;ll val(){return (~f)?(x-y):(y-x);}}Q[N<<3],tmp[N<<3];
void Add(int i,ll x){while(i<=n) c[i]+=x,i+=i&-i;}
ll Ask(int i){ll res=0;while(i) res+=c[i],i^=i&-i;return res;}
void CDQ_Divide(int l,int r){
if(l>=r) return;
int mid=l+r>>1,i,j;
CDQ_Divide(l,mid),CDQ_Divide(mid+1,r);
for(i=mid+1,j=l;i<=r;i++){
if(Q[i].id){
while(j<=mid&&Q[j].x<=Q[i].x){
if(!Q[j].id) Add(Q[j].y,Q[j].val());
j++;
}
Ans[Q[i].id]+=Ask(n)-Ask(Q[i].y-1);
}
}
for(i=l;i<j;i++) if(!Q[i].id) Add(Q[i].y,-Q[i].val());
for(int k=l,i=l,j=mid+1;k<=r;k++) tmp[k]=(j>r||(i<=mid&&Q[i].x<=Q[j].x))?Q[i++]:Q[j++];
for(int k=l;k<=r;k++) Q[k]=tmp[k];
return ;
}
int main(){
read(n),read(q);
for(int i=1;i<=n;i++){
read(pos[i]);
S[pos[i]].insert(i);
if(S[pos[i]].size()>1) Q[++Cnt]=Query{i,*(--S[pos[i]].rbegin()),0,1};
}
while(q--){
int opt,x,y;
read(opt),read(x),read(y);T++;
if(opt==2){Q[++Cnt]=Query{y,x,++cnt,0};continue;}
auto i=S[pos[x]].find(x);int l=0,r=0;
if(i!=S[pos[x]].begin()) Q[++Cnt]=Query{x,l=*--i,0,-1},i++;
if(++i!=S[pos[x]].end()) Q[++Cnt]=Query{r=*i,x,0,-1};
if(l&&r) Q[++Cnt]=Query{r,l,0,1};
S[pos[x]].erase(x);
S[pos[x]=y].insert(x),i=S[y].find(x),l=r=0;
if(i!=S[y].begin()) Q[++Cnt]=Query{x,l=*--i,0,1},i++;
if(++i!=S[y].end()) Q[++Cnt]=Query{r=*i,x,0,1};
if(l&&r) Q[++Cnt]=Query{r,l,0,-1};
}
CDQ_Divide(1,Cnt);
for(int i=1;i<=cnt;i++) write(Ans[i]),putchar('
');
return 0;
}
3月22日
P4390 [BOI2007]Mokia 摩基亚(三维偏序)
P4390 [BOI2007]Mokia 摩基亚(三维偏序)
单点加,询问子矩阵和。
直接把时间轴看做一维,每个操作只会受到 (t_j<t_i) 的操作的影响。
这样就保证了修改,那么我们把询问拆成前缀和,修改直接修改即可。
然后就是三维偏序板题。
P4690 [Ynoi2016] 镜中的昆虫(cdq分治+区间数颜色)
P4690 [Ynoi2016] 镜中的昆虫(cdq分治+区间数颜色)
首先解决单点修改的区间数颜色问题。
先使用经典套路,把区间数颜色转化一下,就是维护每一个点之前第一个与它相同的位置,然后题目就等价于询问区间 ([l,r]) 当中,有多少个 (pre_i<l) 的 (i) 成立。
那么这就是一个经典的二维偏序问题,带上修改,就是三维偏序。
那么对于区间修改,我们有两个做法,第一是直接大力树套树和珂朵莉树维护,第二就是先统计一下答案,然后区间修改会影响的只有两个位置,于是 cdq 分治处理影响即可。
P3206 [HNOI2010]城市建设(线段树分治 + cdq 分治 + Kruskal / 线段树分治 + LCT )
P3206 [HNOI2010]城市建设(线段树分治 + cdq 分治 + Kruskal / 线段树分治 + LCT )
首先这道题是动态维护最小生成树,支持的修改操作是修改边权。
于是第一个做法很轻松的诞生了,LCT维护最小生成树+线段树分治,常数极大,但是可以资瓷更多操作。
然后就是我们的 cdq 分治做法。
其实重点就在于如何把边集缩小到当前分治区间长度一个量级。
首先,我们把要加进来的边设为 -INF ,然后跑最小生成树,此时树上的边是必定在最小生成树上的。
然后设为 INF 再跑一遍,此时没有被选的边一定是不在树上的。
于是我们就缩小这些范围,使用可撤销并查集。
具体见代码。
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define ll long long
const int N=2e4+5,M=5e4+5;
int n,m,Q;
ll a[M],Ans[M];
struct Road{int x,y,id;ll len;}e[20][M],tmp[M],q[M];
inline bool operator <(const Road &u,const Road &v){return u.len<v.len;}
int num[20],top,id[M],fa[M];
struct{int x; ll y;}Que[M];
int Find(int x){return x==fa[x]?x:fa[x]=Find(fa[x]);}
inline void Merge(int u,int v){fa[Find(u)]=Find(v);}
inline void Return(Road *R,int N){for(int i=1;i<=N;i++) fa[R[i].x]=R[i].x,fa[R[i].y]=R[i].y;return ;}
inline void Reduction(Road *R,int &N,ll &V){
Return(R,N);
sort(R+1,R+N+1);
top=0;
for(int i=1;i<=N;i++)if(Find(R[i].x)!=Find(R[i].y))Merge(R[i].x,R[i].y),q[++top]=R[i];
Return(q,top);
for(int i=1;i<=top;i++)if(q[i].len!=-LLONG_MAX and Find(q[i].x)!=Find(q[i].y))V+=q[i].len,Merge(q[i].x,q[i].y);
top=0;
for(int i=1;i<=N;i++) if(Find(R[i].x)!=Find(R[i].y)) q[++top]=R[i],q[top].x=Find(q[top].x),q[top].y=Find(q[top].y);
for(int i=1;i<=top;i++) R[i]=q[i],id[q[i].id] = i;
N=top;
return ;
}
inline void Reduction(Road *R,int &N){
Return(R,N);
sort(R+1,R+N+1);top=0;
for(int i=1;i<=N;i++){
if(Find(R[i].x)!=Find(R[i].y)) q[++top]=R[i],Merge(R[i].x,R[i].y);
else if(R[i].len==LLONG_MAX) q[++top]=R[i];
}
for(int i=1;i<=top;i++) R[i]=q[i],id[q[i].id] = i;
N=top;
return ;
}
void Solve(int l,int r,ll val,int dep){
int N=num[dep];
if(l==r) a[Que[l].x]=Que[l].y;
for(int i=1;i<=N;i++) e[dep][i].len=a[e[dep][i].id],tmp[i]=e[dep][i],id[tmp[i].id]=i;
if(l==r){
sort(tmp+1,tmp+N+1);
Return(tmp,N);
for(int i=1;i<=N;i++) if(Find(tmp[i].x)!=Find(tmp[i].y)) Merge(tmp[i].x,tmp[i].y),val+=tmp[i].len;
Ans[l]=val;
return;
}
for(int i=l;i<=r;i++) tmp[id[Que[i].x]].len=-LLONG_MAX;
Reduction(tmp,N,val);
for(int i=l;i<=r;i++) tmp[id[Que[i].x]].len=LLONG_MAX;
Reduction(tmp,N);
for(int i=1;i<=N;i++) e[dep+1][i]=tmp[i];
num[dep+1]=N;
int mid=l+r>>1;
Solve(l,mid,val,dep+1);
Solve(mid+1,r,val,dep+1);
return ;
}
int main(){
read(n),read(m),read(Q);
for(int i=1;i<=m;i++){
read(e[0][i].x),read(e[0][i].y),
read(a[i]),e[0][i].id=id[i]=i;
}
num[0]=m;
for(int i=1;i<=Q;i++) read(Que[i].x),read(Que[i].y);
Solve(1,Q,0,0);
for(int i=1;i<=Q;i++) write(Ans[i]),putchar('
');
return 0;
}
P4169 [Violet]天使玩偶/SJY摆棋子(三维偏序)
P4169 [Violet]天使玩偶/SJY摆棋子(三维偏序)
万年前的题,直到现在才 AC 。
首先以时间轴为一维,然后我们可以把询问分成四个方向来去掉绝对值(就是跑四个方向)。
比如左下角,那这个就是一个经典的三维偏序了,直接 cdq 分治维护即可。
BS1782【BZOJ4237】 稻草人(单调栈+cdq分治)
BS1782【BZOJ4237】 稻草人(单调栈+cdq分治)
题意就是统计点对:在这两个点构成的矩阵中只有这两个点 的数量。
首先,可以考虑 cdq 分治,然后我们可以观察发现对于横坐标相对关系已经确定的点来说,贡献其实可以使用单调栈维护,然后就是 cdq 分治 + 单调栈了。
具体见这篇题解即可。
3月23日
CF446C DZY Loves Fibonacci Numbers(根号分治+差分)
CF446C DZY Loves Fibonacci Numbers(根号分治(定期重构)+差分)
首先我们发现直接维护区间加斐波那契数列不好维护,于是考虑差分。
我们可以构造这样的一个差分:设 (b) 为差分数组,还原后我们的 (b) 是所有修改全部结束后,每个位置的增量。
然后我们就可以这样做:构造一个还原公式是 (b_i=b_i+b_{i-1}+b_{i-2}) ,然后修改操作 ([l,r]) 我们就是 (b_l+=1) ,然后 (b_{r+1}-=Fib_{r-l+2}) 和 (b_{r+2}-=Fib_{r-l+1})。
带入进去还原一下发现这样做是正确的,也就是我们每次就相当于加上前两项,然后我们发现必须在 (r+1) 处消去 (Fib_{r-l+2}) 的贡献,在 (r+2) 处消去 (Fib_{r-l+1}) 的贡献。
然后我们可以考虑这样做对于多次差分还成立否。
假设两次修改分别是 (a) 和 (b) 我们可以发现 (a_i=a_{i-1}+a_{i-2}) 和 (b_i=b_{i-1}+b_{i-2}) 可以合并成 (a_i+b_i=a_{i-1}+a_{i-2}+b_{i-1}+b_{i-2}) 。
于是我们发现对于多次差分过后再还原也是成立的。
那么我们现在就可以做到 (O(1)) 修改,(O(n)) 查询了。
这是很明显的可以根号平衡,也就是这里使用对修改操作的根号分治。
那么最后时间复杂度 (O(nsqrt(n))) 。
代码:
#include<bits/stdc++.h>
using namespace std;
const int MOD=1e9+9,N=3e5+5;
int n,m,fib[N],sum[N],b[N],v[N],val[N],l[N],r[N],tot;
int md(int x){
if(x>MOD) return x-MOD;
if(x<0) return x+MOD;
return x;
}
vector<int> p1[N],p2[N];
void rebuild(){
for(int i=1;i<=tot;++i){
p1[l[i]].emplace_back(i);
p2[r[i]].emplace_back(i);
}
int a=0,b=0;
for(int i=1;i<=n;++i){
int c=md(a+b);
val[i]=md(val[i]+c);
a=b,b=c;
for(auto x:p1[i]) b=md(b+1),val[i]=md(val[i]+1);
for(auto x:p2[i]){
int L=l[x],R=r[x];
b=md(b-fib[R-L+1]);
a=md(a-fib[R-L]);
}
v[i]=md(v[i-1]+val[i]);
}
for(int i=1;i<=tot;++i){
p1[l[i]].clear();
p2[r[i]].clear();
}
tot=0;
}
int main(){
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
cin>>n>>m;
fib[1]=1,fib[2]=1;
for(int i=3;i<=n;i++) fib[i]=md(fib[i-1]+fib[i-2]);
for(int i=1;i<=n;i++) sum[i]=md(sum[i-1]+fib[i]);
for(int i=1;i<=n;i++) cin>>val[i],v[i]=md(v[i-1]+val[i]);
int lim=sqrt(m);
for(int k=1;k<=m;k++){
int opt,a,b;cin>>opt>>a>>b;
if(opt==1) l[++tot]=a,r[tot]=b;
else{
int ans=0;
for(int i=1;i<=tot;i++){
int L=max(a,l[i]),R=min(b,r[i]);
if(L<=R){
ans=md(ans+md(sum[R-l[i]+1]-sum[L-l[i]]));
if(ans>MOD) ans-=MOD;
}
}
cout<<md(ans+md(v[b]-v[a-1]))<<'
';
}
if(tot==lim) rebuild();
}
return 0;
}
P2137 Gty的妹子树(根号分治(定期重构)+ 主席树 + DFS序 + LCA)
P2137 Gty的妹子树(根号分治(定期重构)+ 主席树 + DFS序 + LCA)

首先看到操作 0 的询问子树,我们可以直接想到 DFS 序。
然后题目的操作 1 让我们意识到这就是一个经典的三维偏序,而且必须在线。
操作 2 就更厉害了,我们就必须得要动态维护树的形态吗?显然那样的话不太可做,于是我们可以考虑定期重构,也就是根号分治。
我们每 (sqrt{n}) 个节点就可以直接暴力重构整个主席树,这样的每次重构是 (O(nlogn)) 的,一共会有 (sqrt{n}) 次重构,也就是这部分的复杂度是 (O(nlognsqrt{n})) 。
那么接下来我们可以考虑整块询问和零散询问的贡献。
首先对于零散的修改的询问,因为这样的零散点不超过 (sqrt{n}) 个,我们可以直接暴力询问,怎么暴力呢?那就是我们可以直接枚举每一个点,然后询问 (LCA(u,x)) 的值是不是当前询问的 (x) ,如果是则代表在其子树内,然后我们再判断大小关系即可,这部分的复杂度很明显是 (O(nlognsqrt{n}))。
然后我们考虑整块询问,相当于我们直接在主席树上询问,复杂度是 (O(nlog^2n)) 。
总贡献是 (O(nlog^2n+nlognsqrt{n})=O(nlognsqrt{n})) 。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int T=2e6+10,N=1e5+10;
int s[T],ls[T],rs[T],rt[N],g[N],a[N],to[N],nx[N],x[N],n,sz;
int in[N],out[N],b[N],w[N],p[N],nw[N],pr[N],nn,Z,r,tot,tp,C;
void add(int u,int v){to[++C]=v;nx[C]=pr[u];pr[u]=C;}
void adds(int u,int v){add(u,v);add(v,u);}
int F(int x){
int L=1,R=nn,m;
for(;L!=R;b[m=L+R>>1]>=x?R=m:L=m+1);
return L;
}
void Ins(int &cp,int np,int L,int R,int v){
s[cp=++Z]=s[np]+1;
if(L==R)return ;int m=L+R>>1;
if(v<=m)Ins(ls[cp],ls[np],L,m,v),rs[cp]=rs[np];
else Ins(rs[cp],rs[np],m+1,R,v),ls[cp]=ls[np];
}
void Que(int lt,int rt,int L,int R,int k){
if(L==k)return void (r+=s[rt]-s[lt]);
int m=L+R>>1;
if(k<=m)Que(ls[lt],ls[rt],L,m,k),r+=s[rs[rt]]-s[rs[lt]];
else Que(rs[lt],rs[rt],m+1,R,k);
}
void Dfs(int u,int f){
in[u]=++tot;p[tot]=u;g[u]=0;
for(int i=pr[u];i;i=nx[i])if(to[i]!=f)Dfs(to[i],u);
out[u]=tot;
}
void Work(int u,int k){
w[u]>=k?++r:0;
for(int i=pr[u];i;i=nx[i])Work(to[i],k);
}
void Build(){
Z=0;n=sz;
for(int i=1;i<=n;i++)b[i]=w[i];
std::sort(b+1,b+n+1);b[nn=1]=b[1];
for(int i=2;i<=n;i++)if(b[i]!=b[i-1])b[++nn]=b[i];
tot=0;Dfs(1,0);
for(int i=1;i<=n;i++)Ins(rt[i],rt[i-1],1,nn,F(w[p[i]]));
}
int Que(int u,int v){
++v;r=0;
if(u>n)return Work(u,v),r;
if(v<=b[nn])Que(rt[in[u]-1],rt[out[u]],1,nn,F(v));
for(int i=n+1;i<=sz;i++)
if(in[u]<=in[g[i]]&&in[g[i]]<=out[u]&&w[i]>=v)++r;
for(int i=1;i<=tp;i++)
if(in[u]<=in[a[i]]&&in[a[i]]<=out[u])
x[i]>=v?--r:0,nw[i]>=v?++r:0;
return r;
}
int main(){
read(n),sz=n;
for(int i=1,u,v;i<n;i++) read(u),read(v),adds(u,v);
for(int i=1;i<=n;i++) read(w[i]);
Build();int m;read(m);
for(int la=0,C=0,pr=0,M=547;m--;){
int op,u,x;read(op),read(u),read(x);u^=la,x^=la;
!op?printf("%d
",la=Que(u,x)):++C;
if(op==1)u>n?w[u]=x:(a[++tp]=u,::x[tp]=w[u],nw[tp]=w[u]=x);
if(op==2)add(u,++sz),g[sz]=(u<=n?u:g[u]),w[sz]=x;
if(C-pr>=M)Build(),pr=C,tp=0;
}
return 0;
}
UVA1676 背单词 GRE Words Revenge(ACAM+二进制分组)
UVA1676 背单词 GRE Words Revenge(ACAM+二进制分组)
咕咕咕。
3214【2015年国家集训队测试】玄学(二进制分组+线段树)
3214【2015年国家集训队测试】玄学(二进制分组+线段树)

首先我们发现题目的第一个操作比较简单,我们直接一个线段树都可以维护(因为标记可以合并)。
但是第二个操作就很难处理了。
于是我们可以直接考虑,我们发现这样也还是一个区间的询问,那么其实我们也还可以这样做:直接对于操作时间序列建一棵线段树(这就是广义上的二进制分组,使得我们可以询问一个区间内的操作影响,类线段树分治?)
那么我们现在重新考虑怎么维护第一个操作。
对于每个第一操作,我们可以考虑这样一件事情:打三个标记,第一个是 ((1,x-1,1,0)) 第二个是 ((x,y,a,b)) 第三个是 ((y+1,n,1,0))。
然后我们可以在时间线段树上合并这些操作即可。
代码:
#include<bits/stdc++.h>
using namespace std;
inline char gc(){
static char buf[100000],*p1=buf,*p2=buf;
return p1==p2&&(p2=(p1=buf)+fread(buf,1,100000,stdin),p1==p2)?EOF:*p1++;
}
template <typename T>
inline void read(T &x){
x=0;char ch=gc();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=gc();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=gc();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define int long long
const int N=1e6+5;
int n,m,a[N],typ,MOD,tot,Ans;
inline int mul(const int &a,const int &b){return 1ll*a*b%MOD;}
inline int add(const int &a,const int &b){return a+b>=MOD?a+b-MOD:a+b;}
struct node{
int a,b,r;
node(int x=0,int y=0,int z=0){a=x,b=y,r=z;}
friend inline node operator + (const node &a,const node &b){return node(mul(a.a,b.a),add(mul(a.b,b.a),b.b),min(a.r,b.r));}
friend inline bool operator < (const node &a,const node &b){
if(a.r^b.r) return a.r<b.r;
if(a.a^b.a) return a.a<b.a;
return a.b<b.b;
}
};
vector<node>t[N<<2];
inline void Merge(vector<node>&Now,vector<node>L,vector<node>R){
unsigned int l=0,r=0;
while(l<L.size()&&r<R.size()){
Now.push_back(L[l]+R[r]);
if(L[l].r==R[r].r) l++,r++;
else if(R[r].r<L[l].r) r++;
else l++;
}
return ;
}
void Modify(int p,int l,int r,const int &x,const int &y,const int &a,const int &b){
if(l==r){
t[p].push_back(node(1,0,x-1));
t[p].push_back(node(a,b,y));
if(y^n) t[p].push_back(node(1,0,n));
return;
}
int mid=(l+r)>>1;
if(tot<=mid) Modify(p<<1,l,mid,x,y,a,b);
else Modify(p<<1|1,mid+1,r,x,y,a,b);
if(tot==r) Merge(t[p],t[p<<1],t[p<<1|1]);
return ;
}
void Query(int p,int l,int r,int ql,int qr,int pos){
if(ql<=l&&qr>=r){
int x=lower_bound(t[p].begin(),t[p].end(),node(0,0,pos))-t[p].begin();
Ans=add(mul(Ans,t[p][x].a),t[p][x].b);return;
}
int mid=(l+r)>>1;
if(ql<=mid) Query(p<<1,l,mid,ql,qr,pos);
if(qr>mid) Query(p<<1|1,mid+1,r,ql,qr,pos);
return ;
}
signed main(){
read(typ),typ=typ&1,read(n),read(MOD);
for(int i=1;i<=n;i++) read(a[i]);read(m);
for(int i=1;i<=m;i++){
int op,l,r,b,c;
read(op),read(l),read(r);
if(typ) l^=Ans,r^=Ans;
if(op==1){
read(b),read(c);
b%=MOD,c%=MOD;++tot;
Modify(1,1,m,l,r,b,c);
}
else{
int pos;read(pos);
if(typ) pos^=Ans;Ans=a[pos];
Query(1,1,m,l,r,pos);
write(Ans),putchar('
');
}
}
return 0;
}
Ex
感觉这就是狭义上的线段树分治?
3月24日
P3834 【模板】可持久化线段树 2(主席树)(整体二分)
P3834 【模板】可持久化线段树 2(主席树)(整体二分)
整体二分模板,静态区间第 k 小。
首先我们可以发现对于每一个询问,我们有这样一种处理办法:
二分一个数,然后遍历原数组看一下小于等于这个数的个数,然后和 k 比较,然后循环这样做即可。
而整体二分的思想就是一次二分我们就回答所有询问。(也就是所有的询问一起二分。)
具体暂不讲解。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=4e5+5,M=2e6+5,INF=1e9;
struct query{
int op,x,y,k,id;
query(int op=0,int x=0,int y=0,int k=0,int id=0):op(op),x(x),y(y),k(k),id(id){}
}Q[N],Ql[N],Qr[N];
int n,m,Ans[N],c[N];
void Add(int x,int v){for(;x<=n;x+=(x&(-x))) c[x]+=v;return ;}
int Ask(int x){int res=0;for(;x>0;x-=(x&(-x))) res+=c[x];return res;}
void Solve(int vl,int vr,int ql,int qr){
if(ql>qr) return ;
if(vl==vr){
for(int i=ql;i<=qr;i++) if(Q[i].op) Ans[Q[i].id]=vl;
return ;
}
int mid=(vl+vr)>>1,nl=0,nr=0;
for(int i=ql;i<=qr;i++){
if(!Q[i].op){
if(Q[i].x<=mid) Add(Q[i].y,1),Ql[++nl]=Q[i];
else Qr[++nr]=Q[i];
}
else{
int k=Ask(Q[i].y)-Ask(Q[i].x-1);
if(k>=Q[i].k) Ql[++nl]=Q[i];
else Q[i].k-=k,Qr[++nr]=Q[i];
}
}
for(int i=ql;i<=qr;i++) if(!Q[i].op&&Q[i].x<=mid) Add(Q[i].y,-1);
for(int i=1;i<=nl;i++) Q[i+ql-1]=Ql[i];
for(int i=1;i<=nr;i++) Q[i+ql+nl-1]=Qr[i];
Solve(vl,mid,ql,ql+nl-1),Solve(mid+1,vr,ql+nl,qr);
return ;
}
int main(){
read(n),read(m);
for(int i=1,x;i<=n;i++) read(x),Q[i]=query(0,x,i);
for(int i=1,x,y,k;i<=m;i++) read(x),read(y),read(k),Q[i+n]=query(1,x,y,k,i);
Solve(-INF,INF,1,n+m);
for(int i=1;i<=m;i++) write(Ans[i]),putchar('
');
return 0;
}
P2617 Dynamic Rankings(整体二分)
动态区间第 k 大模板,使用整体二分解决。
相比于上一道题,这道题多了修改。
我们可以考虑把一个修改拆成两个来处理,一个删除一个插入。
具体见代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=3e5+5,M=2e6+5,INF=1e9;
struct query{
int op,x,y,k,id;
query(int op=0,int x=0,int y=0,int k=0,int id=0):op(op),x(x),y(y),k(k),id(id){}
}Q[N],Ql[N],Qr[N];
int n,m,Ans[N],c[N],a[N],Cnt,Acnt;
void Add(int x,int v){for(;x<=n;x+=(x&(-x))) c[x]+=v;return ;}
int Ask(int x){int res=0;for(;x>0;x-=(x&(-x))) res+=c[x];return res;}
void Solve(int vl,int vr,int ql,int qr){
if(ql>qr) return ;
if(vl==vr){
for(int i=ql;i<=qr;i++) if(Q[i].op==2) Ans[Q[i].id]=vl;
return ;
}
int mid=(vl+vr)>>1,nl=0,nr=0;
for(int i=ql;i<=qr;i++){
if(Q[i].op!=2){
if(Q[i].x<=mid) Add(Q[i].y,Q[i].op),Ql[++nl]=Q[i];
else Qr[++nr]=Q[i];
}
else{
int k=Ask(Q[i].y)-Ask(Q[i].x-1);
if(k>=Q[i].k) Ql[++nl]=Q[i];
else Q[i].k-=k,Qr[++nr]=Q[i];
}
}
for(int i=ql;i<=qr;i++) if(Q[i].op!=2&&Q[i].x<=mid) Add(Q[i].y,-Q[i].op);
for(int i=1;i<=nl;i++) Q[i+ql-1]=Ql[i];
for(int i=1;i<=nr;i++) Q[i+ql+nl-1]=Qr[i];
Solve(vl,mid,ql,ql+nl-1),Solve(mid+1,vr,ql+nl,qr);
return ;
}
int main(){
read(n),read(m);
for(int i=1,x;i<=n;i++) read(x),Q[++Cnt]=query(1,x,i),a[i]=x;char op[5];
for(int i=1,x,y,k;i<=m;i++){
scanf("%s",op);
if(op[0]=='Q') read(x),read(y),read(k),Q[++Cnt]=query(2,x,y,k,++Acnt);
else read(x),read(y),Q[++Cnt]=query(-1,a[x],x),Q[++Cnt]=query(1,y,x),a[x]=y;
}
Solve(-INF,INF,1,Cnt);
for(int i=1;i<=Acnt;i++) write(Ans[i]),putchar('
');
return 0;
}
Ex
其实整体二分来解决区间第 k 大其本质就是把求区间第 k 大转化成了求二维偏序,只不过这个时候第一维(时间)天然有序,所以我们只需要处理第二维(值域)即可。
P1527 [国家集训队]矩阵乘法(整体二分+三维偏序/整体二分+二维树状数组)
P1527 [国家集训队]矩阵乘法(整体二分+三维偏序/整体二分+二维树状数组)
首先我们看到第 k 大,可以想一下整体二分,一般的是“区间”,这里却是“矩阵”,那么其实差别就是从一维到了二维。
我们回想一下区间第 k 大实际上是二维偏序的话,这里多了一维,那么不就是三维偏序吗?
事实上也是的。
于是我们可以考虑使用 cdq分治和树套树了(而且这里的第一维时间轴天然有序),那么这道题因为 (n) 比较小,我们可以直接使用二维树状数组来实现这个三维偏序。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
//#define int long long
#define y1 qwq
const int N=5e3+5,M=4e5+5,INF=1e9+7;
int n,m,c[N][N],Ans[M],Cnt;
struct query{
int op,x1,y1,k,x2,y2,id,Id;
query(int op=0,int x1=0,int y1=0,int k=0,int x2=0,int y2=0,int id=0,int Id=0):op(op),x1(x1),y1(y1),k(k),x2(x2),y2(y2),id(id),Id(Id){}
bool operator < (const query &B) const{return Id<B.Id;}
}Q[M],Ql[M],Qr[M];
bool flag;
void Add(int x,int y,int v){
if(!x||!y) return ;
for(int i=x;i<=n;i+=(i&(-i))){
for(int j=y;j<=n;j+=(j&(-j))){
c[i][j]+=v;
}
}
return ;
}
int Ask(int x,int y){
int res=0;
for(int i=x;i;i-=(i&(-i))){
for(int j=y;j;j-=(j&(-j))){
res+=c[i][j];
}
}
return res;
}
void Solve(int vl,int vr,int ql,int qr){
if(vl>vr||ql>qr) return ;
if(vl==vr){
for(int i=ql;i<=qr;i++) if(!Q[i].op) Ans[Q[i].id]=vl;
return ;
}
int mid=vl+vr>>1,nl=0,nr=0;
sort(Q+ql,Q+qr+1);
for(int i=ql;i<=qr;i++){
if(Q[i].op){
if(Q[i].k<=mid) Add(Q[i].x1,Q[i].y1,1),Ql[++nl]=Q[i];
else Qr[++nr]=Q[i];
}
else{
int k=Ask(Q[i].x2,Q[i].y2)-Ask(Q[i].x2,Q[i].y1-1)-Ask(Q[i].x1-1,Q[i].y2)+Ask(Q[i].x1-1,Q[i].y1-1);
if(k>=Q[i].k) Ql[++nl]=Q[i];
else Q[i].k-=k,Qr[++nr]=Q[i];
}
}
for(int i=ql;i<=qr;i++) if(Q[i].op&&Q[i].k<=mid) Add(Q[i].x1,Q[i].y1,-1);
for(int i=1;i<=nl;i++) Q[ql+i-1]=Ql[i];
for(int i=1;i<=nr;i++) Q[ql+i+nl-1]=Qr[i];
Solve(vl,mid,ql,ql+nl-1);
Solve(mid+1,vr,ql+nl,qr);
return ;
}
signed main(){
read(n),read(m);
for(int i=1;i<=n;i++){
for(int j=1,v;j<=n;j++){
read(v);
Q[++Cnt]=query(1,i,j,v);Q[Cnt].Id=Cnt;
}
}
for(int i=1,x1,y1,x2,y2,k;i<=m;i++){
read(x1),read(y1),read(x2),read(y2),read(k);
Q[++Cnt]=query(0,x1,y1,k,x2,y2,i);Q[Cnt].Id=Cnt;
}
Solve(0,INF,1,Cnt);
for(int i=1;i<=m;i++) write(Ans[i]),putchar('
');
return 0;
}
P3332 [ZJOI2013]K大数查询(整体二分+线段树)
P3332 [ZJOI2013]K大数查询(整体二分+线段树)
这道题有点清奇,因为一个下标里可能有很多个数。
那么我们想一下我们之前使用树状数组的原因:单修区查。
那么其实这里就是对整个区间加了之后再区间询问即可,所以可以使用线段树来解决这个问题。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define int long long
const int N=3e5+5,M=2e6+5,INF=1e12;
struct query{
int op,x,y,k,id;
query(int op=0,int x=0,int y=0,int k=0,int id=0):op(op),x(x),y(y),k(k),id(id){}
}Q[N],Ql[N],Qr[N];
int n,m,Ans[N],c[N],a[N],Cnt,Acnt;
int sum[N<<2],add[N<<2];
void PushDown(int x,int l,int r){
if(!add[x]) return ;
int mid=l+r>>1;
sum[x<<1]+=add[x]*(mid-l+1);
sum[x<<1|1]+=add[x]*(r-mid);
add[x<<1]+=add[x],add[x<<1|1]+=add[x];
add[x]=0;
return ;
}
void Pushup(int x){sum[x]=sum[x<<1]+sum[x<<1|1];return ;}
void Modify(int x,int l,int r,int ql,int qr,int v){
if(ql<=l&&r<=qr){
add[x]+=v;
sum[x]+=(r-l+1)*v;
return ;
}
PushDown(x,l,r);
int mid=l+r>>1;
if(ql<=mid) Modify(x<<1,l,mid,ql,qr,v);
if(qr>mid) Modify(x<<1|1,mid+1,r,ql,qr,v);
Pushup(x);
return ;
}
int Query(int x,int l,int r,int ql,int qr){
if(ql<=l&&r<=qr) return sum[x];
PushDown(x,l,r);
int mid=l+r>>1,res=0;
if(ql<=mid) res=Query(x<<1,l,mid,ql,qr);
if(qr>mid) res+=Query(x<<1|1,mid+1,r,ql,qr);
return res;
}
void Solve(int vl,int vr,int ql,int qr){
if(ql>qr) return ;
if(vl==vr){
for(int i=ql;i<=qr;i++) if(Q[i].op==2) Ans[Q[i].id]=vl;
return ;
}
int mid=(vl+vr)>>1,nl=0,nr=0;
for(int i=ql;i<=qr;i++){
if(Q[i].op!=2){
if(Q[i].k<=mid) Modify(1,1,n,Q[i].x,Q[i].y,Q[i].op),Ql[++nl]=Q[i];
else Qr[++nr]=Q[i];
}
else{
int k=Query(1,1,n,Q[i].x,Q[i].y);
if(k>=Q[i].k) Ql[++nl]=Q[i];
else Q[i].k-=k,Qr[++nr]=Q[i];
}
}
for(int i=ql;i<=qr;i++) if(Q[i].op!=2&&Q[i].k<=mid) Modify(1,1,n,Q[i].x,Q[i].y,-Q[i].op);
for(int i=1;i<=nl;i++) Q[i+ql-1]=Ql[i];
for(int i=1;i<=nr;i++) Q[i+ql+nl-1]=Qr[i];
Solve(vl,mid,ql,ql+nl-1),Solve(mid+1,vr,ql+nl,qr);
return ;
}
signed main(){
read(n),read(m);
for(int i=1,op,x,y,k;i<=m;i++){
read(op);
if(op==2) read(x),read(y),read(k),Q[++Cnt]=query(2,x,y,k,++Acnt);
else read(x),read(y),read(k),k=-k,Q[++Cnt]=query(1,x,y,k);
}
Solve(-INF,INF,1,Cnt);
for(int i=1;i<=Acnt;i++) write(-Ans[i]),putchar('
');
return 0;
}
P3527 [POI2011]MET-Meteors&SP10264 METEORS - Meteors(整体二分)
P3527 [POI2011]MET-Meteors&SP10264 METEORS - Meteors(整体二分)
这道题才是整体二分的真正应用。
首先,我们可以发现,假设我们现在只考虑一个国家,那么答案显然可以二分,于是我们二分答案。
怎么判定呢,就是直接树状数组+差分维护区间修改,然后查询每一个点的贡献再求和,再去和原题给定的标准值比较即可。
那么现在有很多个询问,故我们可以考虑整体二分。(就是所有的询问一起二分,每一个国家都一起二分)
还是树状数组维护区间和,我们可以对每一个国家开一个 vector ,然后求和之后直接和刚刚一样比较即可,再根据比较结果划分给 左/右 半区间。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=3e5+5;
#define ll long long
ll c[N];
vector<int> G[N];
int L[N],R[N],val[N],P[N],ans[N],q[N],q1[N],q2[N];
int n,m,k,now=0;
inline void add(int x,int v){for(;x<=m;x+=(x&(-x))) c[x]+=v;}
inline ll query(int x) {ll tmp=0;for(;x>0;x-=(x&(-x))) tmp+=c[x];return tmp;}
inline void update(int l,int r,int v) {
if(l<=r) add(l,v),add(r+1,-v);
else add(1,v),add(r+1,-v),add(l,v),add(m+1,-v);
return ;
}
void solve(int l,int r,int s,int t){//lr流星雨区间 mid答案 st未解决的国家区间
if(s>t) return;
if(l==r){for(int i=s;i<=t;i++)ans[q[i]]=l;return;}
int mid=(l+r)>>1;
while(now<mid) now++,update(L[now],R[now],val[now]);
while(now>mid) update(L[now],R[now],-val[now]),now--;
int s1=0,s2=0;
for(int i=s;i<=t;i++) {
ll tmp=0;
int x=q[i];
for (int j=0;j<G[x].size();j++) {
tmp+=query(G[x][j]);
if (tmp>=P[x]) break;
}
if (tmp>=P[x]) q1[++s1]=x;
else q2[++s2]=x;
}
for(int i=1;i<=s1;i++) q[s+i-1]=q1[i];
for(int i=1;i<=s2;i++) q[s+s1+i-1]=q2[i];
solve(l,mid,s,s+s1-1);
solve(mid+1,r,s+s1,t);
return ;
}
int main() {
read(n),read(m);
for(int i=1,x;i<=m;i++) read(x),G[x].push_back(i);
for(int i=1;i<=n;i++) read(P[i]),q[i]=i;
read(k);
for(int i=1;i<=k;i++) read(L[i]),read(R[i]),read(val[i]);
solve(1,k+1,1,n);
for(int i=1;i<=n;i++){
if(ans[i]==k+1) puts("NIE");
else write(ans[i]),puts("");
}
return 0;
}
P4602 [CTSC2018]混合果汁(整体二分)
和上一道题一样,也是整体二分的应用。
同样我们可以发现,对于每一个小朋友的答案我们都可以二分,从而可以扩展到整体二分。
现在考虑如何判定。
其实询问就相当于是把果汁按照代价排序,选一段前缀。
于是我们可以直接维护两个前缀和(体积/钱的总和),这里使用两个树状数组可以实现。
然后询问的时候我们直接二分然后在树状数组上询问即可,当然也可以选择树状数组上二分。
也就是我们算出填满当前体积所在的位置,再算这个位置对应的钱,再比较一下这个值和小朋友本身有的钱即可。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define ll long long
const int N=2e5+5;
const ll inf=1e18+7;
ll n,m,now,Maxn,ans[N];
struct node{ll d,p,l;}t[N];
bool cmp(const node &a,const node &b){return a.d>b.d;}
struct Ask{ll g,l;int id;}Q[N],Q1[N],Q2[N];
struct Tree{
ll c[N];
void Add(int x,ll v){for(;x<=Maxn;x+=(x&(-x))) c[x]+=v;return ;}
ll Ask(int x){ll res=0;for(;x;x-=(x&(-x))) res+=c[x];return res;}
}Li,Pr;
void Modify(int x,int type){Li.Add(t[x].p,type*t[x].l),Pr.Add(t[x].p,type*t[x].p*t[x].l);return ;}
ll Find(int x){
int l=1,r=Maxn,pr=Maxn;
while(l<=r){
int mid=(l+r)>>1;
if(Li.Ask(mid)>=Q[x].l) pr=mid,r=mid-1;
else l=mid+1;
}
return pr;
}
void Solve(int L,int R,int l,int r){
if(L>R) return;
if(l==r){for(int i=L;i<=R;i++) ans[Q[i].id]=t[l].d;return;}
int mid=(l+r)>>1;
while(now<mid) Modify(++now,1);
while(now>mid) Modify(now--,-1);
int cnt1=0,cnt2=0;
for(int i=L;i<=R;i++){
ll pr=Find(i),lv=Li.Ask(pr),pv=Pr.Ask(pr);
if(lv>=Q[i].l&&pv-pr*(lv-Q[i].l)<=Q[i].g) Q1[++cnt1]=Q[i];
else Q2[++cnt2]=Q[i];
}
for(int i=1;i<=cnt1;i++) Q[L+i-1]=Q1[i];
for(int i=1;i<=cnt2;i++) Q[L+cnt1+i-1]=Q2[i];
Solve(L,L+cnt1-1,l,mid),Solve(L+cnt1,R,mid+1,r);
return ;
}
int main(){
read(n),read(m);
for(int i=1;i<=n;i++) read(t[i].d),read(t[i].p),read(t[i].l),Maxn=max(Maxn,t[i].p);
t[++n].d=-1,t[n].p=1,t[n].l=inf,sort(t+1,t+n+1,cmp);
for(int i=1;i<=m;i++) read(Q[i].g),read(Q[i].l),Q[i].id=i;
Solve(1,m,1,n);
for(int i=1;i<=m;i++) write(ans[i]),putchar('
');
return 0;
}
注意
做这种整体二分的应用的固定格式要记住,每一次二分的时候不能直接全部线性重来!!
不然复杂度就是假的,会退化成 (O(n^2logn)) 。
感性证明时间复杂度
关于这样写的时间复杂度,我之前也想过为什么这个就和暴力不一样?
其实证明很简单,我们感性理解一下:
首先,代码里唯一需要讨论复杂度的就是那两个 while 是什么复杂度。
其次,我们可以知道,两个 while 在当前这一次分治中只会执行一个。
第三,我们知道这时这个 (now) 和 (mid) 的差一定是 (1/4) 上一个区间长度。
((1/4) ,(1/4) 分别对应左右区间,第一个是 (1/4) 很好理解,就是从上一个的 (mid) 移动到了 (l+(l+mid)/2) ,至于第二个为什么是 (1/4):因为我们在处理完了左区间之后才会处理右区间,这时我们的 (now) 一定会处在左区间的最右端点,此时我们 (now) 需要移动到右区间的中点,那么也就是 (1/4) 上一个区间长度)。
那么这里的时间复杂度即为 (O(nlogn)) 得证。
3月25日
U156941 能进行值域查询的时光鸡1(cdq 分治+树状数组)
U156941 能进行值域查询的时光鸡1(cdq 分治+树状数组)
一道 cdq 分治离线问题的应用。
首先发现答案具有可加性和可减性。
于是考虑 cdq 分治,然后第一维就是保证操作时间轴有序。
然后是一个值域树状数组统计和就行了。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=3e5+5;
#define ll long long
int q,n,t,idx,Acnt,Cnt,b[N];
ll Ans[N],c[N];
struct Query{
int op,t,x;ll y;int id;
Query(int op=0,int t=0,int x=0,ll y=0,int id=0):op(op),t(t),x(x),y(y),id(id){}
}Q[N];
inline bool CmpD1(Query a,Query b){
if(a.t^b.t) return a.t<b.t;
return a.op<b.op;
}
void Add(int x,ll v){for(;x<=idx;x+=(x&(-x))) c[x]+=v;return ;}
ll Ask(int x){ll res=0;for(;x;x-=(x&(-x))) res+=c[x];return res;}
void Clear(int x){for(;x<=idx;x+=(x&(-x))) c[x]=0;return ;}
void CDQ_Divide(int l,int r){
if(l==r) return ;
int mid=l+r>>1;
CDQ_Divide(l,mid),CDQ_Divide(mid+1,r);
sort(Q+l,Q+mid+1,CmpD1),sort(Q+mid+1,Q+r+1,CmpD1);
for(int i=mid+1,j=l;i<=r;i++){
while(Q[i].t>=Q[j].t&&j<=mid){
if(Q[j].op==1||Q[j].op==2) Add(Q[j].x,Q[j].y);
j++;
}
if(Q[i].op==3) Ans[Q[i].id]+=Ask(Q[i].y)-Ask(Q[i].x-1);
}
for(int i=l;i<=mid;i++) if(Q[i].op==1||Q[i].op==2) Clear(Q[i].x);
return ;
}
int main(){
read(q),read(n),read(t);
for(int i=1;i<=q;i++){
read(Q[i].op);
if(Q[i].op==1) read(Q[i].t),read(Q[i].x),Q[i].y=Q[i].x,b[++Cnt]=Q[i].x;
else if(Q[i].op==2) read(Q[i].t),read(Q[i].x),Q[i].y=-Q[i].x;
else read(Q[i].t),read(Q[i].x),read(Q[i].y),b[++Cnt]=Q[i].x,b[++Cnt]=Q[i].y,Q[i].id=++Acnt;
}
sort(b+1,b+Cnt+1);
idx=unique(b+1,b+Cnt+1)-b-1;
for(int i=1;i<=q;i++){
Q[i].x=lower_bound(b+1,b+idx+1,Q[i].x)-b;
if(Q[i].op==3) Q[i].y=lower_bound(b+1,b+idx+1,Q[i].y)-b;
}
CDQ_Divide(1,q);
for(int i=1;i<=Acnt;i++) write(Ans[i]),putchar('
');
return 0;
}
BS3539【模拟试题】区间第k大问题 EXT(整体二分)
uploading-image-939594.png
先按照操作序列的对应时间点排序,然后整体二分求区间第 k 大。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define int long long
const int N=3e5+5,M=2e6+5,INF=1e16;
struct query{
int op,x,y,k,id,d;
query(int op=0,int x=0,int y=0,int k=0,int id=0,int d=0):op(op),x(x),y(y),k(k),id(id),d(d){}
}Q[N],Ql[N],Qr[N];
int n,m,Ans[N],c[N],a[N],Cnt,Acnt;
void Add(int x,int v){for(;x<=n;x+=(x&(-x))) c[x]+=v;return ;}
int Ask(int x){int res=0;for(;x>0;x-=(x&(-x))) res+=c[x];return res;}
void Solve(int vl,int vr,int ql,int qr){
if(ql>qr||vl>vr) return ;
if(vl==vr){
for(int i=ql;i<=qr;i++) if(Q[i].op==2) Ans[Q[i].id]=vl;
return ;
}
int mid=(vl+vr)>>1,nl=0,nr=0;
for(int i=ql;i<=qr;i++){
if(Q[i].op!=2){
if(Q[i].x<=mid) Add(Q[i].y,Q[i].op),Ql[++nl]=Q[i];
else Qr[++nr]=Q[i];
}
else{
int k=Ask(Q[i].y)-Ask(Q[i].x-1);
if(k>=Q[i].k) Ql[++nl]=Q[i];
else Q[i].k-=k,Qr[++nr]=Q[i];
}
}
for(int i=ql;i<=qr;i++) if(Q[i].op!=2&&Q[i].x<=mid) Add(Q[i].y,-Q[i].op);
for(int i=1;i<=nl;i++) Q[i+ql-1]=Ql[i];
for(int i=1;i<=nr;i++) Q[i+ql+nl-1]=Qr[i];
Solve(vl,mid,ql,ql+nl-1),Solve(mid+1,vr,ql+nl,qr);
return ;
}
inline bool CmpD1(query x,query y){
if(x.d^y.d) return x.d<y.d;
return x.op<y.op;
}
signed main(){
read(n),read(m);
for(int i=1,x;i<=n;i++) read(x),Q[++Cnt]=query(1,x,i,0,0,0),a[i]=x;char op[5];
for(int i=1,x,y,t,k;i<=m;i++){
scanf("%s",op);
if(op[0]=='Q') read(t),read(x),read(y),read(k),Q[++Cnt]=query(2,x,y,k,++Acnt,t);
else read(x),read(y),Q[++Cnt]=query(-1,a[x],x,0,0,i),Q[++Cnt]=query(1,y,x,0,0,i),a[x]=y;
}
sort(Q+1,Q+Cnt+1,CmpD1);
Solve(0,INF,1,Cnt);
for(int i=1;i<=Acnt;i++) write(Ans[i]),putchar('
');
return 0;
}
BS3868【BZOJ4604】The kth maximum number(整体二分+二维偏序)
BS3868【BZOJ4604】The kth maximum number(整体二分+二维偏序)
终究是逃不过了。。
思路之前讲过了,我们现在把问题转化成了二维偏序问题(整体二分自带修改)。
于是考虑可以 cdq 分治解决。
代码:
#include<cstdio>
#include<cstring>
#include<iostream>
#include<cstdlib>
using namespace std;
struct node{
int op,x,y,c;
}Q[200010],q[200010],q1[200010],q2[200010],tmp[200010];int cnt=0,qcnt=0;
const int inf=1e9;
int n,m,K[50010],ans[50010],num[50010],tr[500010],re[200010],tim=0,C[50010];
void change(int k,int c) {for(int i=k;i<=n;i+=(i&-i)) tr[i]+=c;}
int get(int k) {int ans=0;for(int i=k;i>=1;i-=(i&-i)) ans+=tr[i];return ans;}
int read()
{
int x=0,f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
void cdq(int l,int r,int Mid)
{
if(l==r) return;
int mid=(l+r)/2;
cdq(l,mid,Mid);cdq(mid+1,r,Mid);
int i=l,j=mid+1,len=0,st=0;
while(i<=mid&&j<=r)
{
if(Q[i].x<=Q[j].x)
{
if(Q[i].op==1&&Q[i].c>Mid) change(Q[i].y,1),re[++st]=Q[i].y;
tmp[++len]=Q[i++];
}
else
{
if(Q[j].op==2) num[Q[j].c]+=get(Q[j].y);
if(Q[j].op==3) num[Q[j].c]-=get(Q[j].y);
tmp[++len]=Q[j++];
}
}
while(i<=mid) tmp[++len]=Q[i++];
while(j<=r)
{
if(Q[j].op==2) num[Q[j].c]+=get(Q[j].y);
if(Q[j].op==3) num[Q[j].c]-=get(Q[j].y);
tmp[++len]=Q[j++];
}
for(i=1;i<=st;i++) change(re[i],-1);
for(i=1;i<=len;i++) Q[l+i-1]=tmp[i];
}
void solve(int l,int r,int L,int R)
{
if(l>r) return;
if(L==R)
{
for(int i=l;i<=r;i++) {if(q[i].op!=1) num[q[i].c]=0;Q[i]=q[i];}
cdq(l,r,L-1);
for(int i=l;i<=r;i++)
if(q[i].op!=1)
if(K[q[i].c]==num[q[i].c]) ans[q[i].c]=L;
else ans[q[i].c]=-1;
return;
}
int mid=(L+R)/2,l1=0,l2=0;
for(int i=l;i<=r;i++) {if(q[i].op!=1) num[q[i].c]=0;Q[i]=q[i];}
cdq(l,r,mid);
for(int i=l;i<=r;i++)
{
if(q[i].op==1)
{
if(q[i].c<=mid) q1[++l1]=q[i];
else q2[++l2]=q[i];
}
else
{
if(num[q[i].c]<K[q[i].c]) q1[++l1]=q[i];
else q2[++l2]=q[i];
}
}
tim++;
for(int i=l;i<=r;i++) if(q[i].op!=1&&num[q[i].c]<K[q[i].c]&&C[q[i].c]!=tim) K[q[i].c]-=num[q[i].c],C[q[i].c]=tim;
for(int i=1;i<=l1;i++) q[l+i-1]=q1[i];
for(int i=1;i<=l2;i++) q[l+i+l1-1]=q2[i];
solve(l,l+l1-1,L,mid);solve(l+l1,r,mid+1,R);
}
int main()
{
n=read();m=read();
for(int i=1;i<=m;i++)
{
int op;op=read();
if(op==1)
{
int x,y,c;x=read();y=read();c=read();
q[++cnt].op=1;q[cnt].x=x;q[cnt].y=y;q[cnt].c=c;
}
else
{
int x,y,x1,y1;qcnt++;x=read();y=read();x1=read();y1=read();K[qcnt]=read();
q[++cnt].op=2;q[cnt].x=x1;q[cnt].y=y1;q[cnt].c=qcnt;
q[++cnt].op=3;q[cnt].x=x-1;q[cnt].y=y1;q[cnt].c=qcnt;
q[++cnt].op=3;q[cnt].x=x1;q[cnt].y=y-1;q[cnt].c=qcnt;
q[++cnt].op=2;q[cnt].x=x-1;q[cnt].y=y-1;q[cnt].c=qcnt;
}
}
solve(1,cnt,1,inf);
for(int i=1;i<=qcnt;i++)
{
if(ans[i]==-1) printf("NAIVE!ORZzyz.
");
else printf("%d
",ans[i]);
}
}
CF603E Pastoral Oddities(整体二分)
CF603E Pastoral Oddities(整体二分)
神仙思路。
首先做这个题必须要先手玩样例推出一个重要的性质:当一个图可以满足题目条件当且仅当途中所有连通块的大小都是偶数。
这里就暂不赘述具体的做法了,我们重点在于整体二分。
然后我们发现每次询问的答案可以二分,而且因为我们不断地加边,答案肯定越来越优,也就是说答案单调不升,于是我们可以考虑整体二分。
我们可以这样来二分:(Solve(ql,qr,vl,vr)) 表示当前我们要处理的询问区间是 ([ql,qr]) ,且这些询问的答案一定在 (val_vl) ~ (val_vr) 之间。(假设事先对于边集以权值为关键字排过序,并用一个数组存了下来)
注意:这里的 ([vl,vr]) 是下标区间,具体来说是所有边按边权排完序过后的下标区间。
接下来想一下对于每一次分治具体怎么做:
首先,我们在处理到当前区间之前,要先保证:区间 ([1,ql]) 的所有值 (leq val_vl) 的边都在我们当前的边集内。
然后我们才可以考虑二分,我们每次二分 (mid=ql+qr>>1) ,那么我们现在就相当于是在权值为 (val_{vl+1}) ~ (val_{vr}) 且编号在 ([ql,qr]) 中 的区间当中找到一个最小的点 (MID) 使得这个图满足条件。
那么因为之前我们已经排过序并用一个数组存下来了,所以我们直接不停的从小到大加边直到满足条件或加完所有的边为止,那么我们把这个点记作 (MID)。( (MID) 一定是 ([vl,vr]) 上的。)
然后我们判断当前状态下图是否满足形态,更新一下 (Ans[Q[mid].id]) 。
那么现在我们就把区间分成了左右两半,要递归的子区间明显是 (Solve(ql,mid-1,MID,vr)) 和 (Solve(mid+1,qr,vl,MID)) 。(还是因为答案的单调不上升。)
但是在进入之前我们都要先处理一下边集:
也就是我们先还原我们在当前区间的所有操作(使用可撤销并查集即可),然后在递归左边之前,先把边权在 (val_{vl}) ~ (val_{MID}) 当中且边的编号在 ([1,ql]) 中的边全部加进去。
在递归右边之前,先还原左边的影响,然后把编号在 ([ql,mid]) 且权值 (leq val_{vl}) 的边加入。
然后记得我们这里的“图是否满足条件”的状态是在全局维护的(代码里就是 (Now) ),维护的是奇数连通块个数。
最后就是并查集要按秩合并(可撤销并查集基操)。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=4e5+5;
int n,m,Now,Ans[N];
struct Query{
int x,y,v,id;
}Q[N],P[N];
inline bool Cmp(Query a,Query b){return (a.v==b.v)?(a.id<b.id):(a.v<b.v);}
namespace DSU{//可撤销并查集(按秩合并)
int fa[N],siz[N],top;
struct _Node{int x,y,fa1,fa2,siz1,siz2;}sta[N];
void PreWork(){
top=0;
for(int i=1;i<=n;i++) fa[i]=i,siz[i]=1;
return ;
}
int Getfa(int x){return x==fa[x]?x:Getfa(fa[x]);}
void Merge(int x,int y){
int fx=Getfa(x),fy=Getfa(y);
if(fx==fy) return ;
if(siz[fx]>siz[fy]) swap(fx,fy);
if((siz[fx]&1)&&(siz[fy]&1)) Now-=2;
sta[++top].x=fx,sta[top].fa1=fx;
sta[top].y=fy,sta[top].fa2=fy;
sta[top].siz1=siz[fx],sta[top].siz2=siz[fy];
fa[fx]=fy,siz[fy]+=siz[fx];
return ;
}
void Return(){
fa[sta[top].x]=sta[top].fa1,siz[sta[top].x]=sta[top].siz1;
fa[sta[top].y]=sta[top].fa2,siz[sta[top].y]=sta[top].siz2;
Now+=((sta[top].siz1&1)&&(sta[top].siz2&1))*2;
top--;return ;
}
};
using namespace DSU;
namespace Solve{
void Solve(int vl,int vr,int ql,int qr){//处理下标在 ql-qr 的答案,且答案一定在区间下标为 vl-vr 当中。
if(ql>qr) return ;
int mid=ql+qr>>1,now=top,NOW=vl,MID; //以 ans[mid] 为基准处理左右区间
for(int i=ql;i<=mid;i++) if(P[i].v<=vl) Merge(P[i].x,P[i].y);
for(int i=vl;i<=vr&&Now;i++,NOW++) if(Q[i].id<=mid) Merge(Q[i].x,Q[i].y);
MID=max(NOW-1,vl);
if(!Now) Ans[P[mid].id]=Q[MID].v;
else Ans[P[mid].id]=-1;
while(top>now) Return();
for(int i=vl;i<=MID;i++) if(Q[i].id<=ql) Merge(Q[i].x,Q[i].y);
Solve(MID,vr,ql,mid-1);
while(top>now) Return();
for(int i=ql;i<=mid;i++) if(P[i].v<=vl) Merge(P[i].x,P[i].y);
Solve(vl,MID,mid+1,qr);
while(top>now) Return();
return ;
}
}
namespace Main{
void main(){
read(n),read(m);
for(int i=1,x,y,v;i<=m;i++){
read(x),read(y),read(v);
Q[i]=Query{x,y,v,i};
P[i]=Q[i];
}
sort(Q+1,Q+m+1,Cmp);
for(int i=1;i<=m;i++) P[Q[i].id].v=i;
Now=n;
PreWork();
Solve::Solve(1,m,1,m);
for(int i=1;i<=m;i++) printf("%d
",Ans[i]);
return ;
}
};
int main(){
Main::main();
return 0;
}
3月26日
P5163 WD与地图(整体二分+tarjan+线段树合并)
P5163 WD与地图(整体二分+tarjan+线段树合并)
神仙题。
首先我们发现可以把操作倒过来,就是删边变成加边。
然后我们可以看出一个暴力做法:求出每一条边的 ((u,v)) 在某一时刻成为了同一连通分量的时间。
这个明显是可以二分的。
这样求完了的话就是一个值域线段树合并和询问全局第 k 大了。
现在的问题在于怎么求这个,暴力二分肯定不行。
于是我们可以考虑整体二分。
(Solve(vl,vr,ql,qr)) 表示:询问下标在 ([ql,qr]) 中的这些边当中,答案一定在 ([vl,vr]) 之间。
于是我们二分时间 (mid=vl+vr>>1) 。
然后就是很简单的处理:将区间 ([ql,qr]) 中的边且出现时间在 (mid) 之前的边加入当前图中。
然后在当前图跑一遍 Tarjan 缩点。
接下来划分区间:如果当前边的 ((u,v)) 现在在一个连通分量当中且当前边的时间 (leq mid) 的话,就加入到左边,否则右边。
然后我们先递归右边,再回溯过后递归左边分治。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
#define ll long long
typedef pair<int,int> PII;
const int N=1e5+5,M=2e5+5;
int n,m,q,a[N],op[M],A[M],B[M],Cnt,Acnt,b[N*3],aa[N],Edge[M*2],stkx[M],stky[M],top,Fa[N],Siz[N],to[M],nex[M],head[N],idx;
inline void Add(int s,int t){to[++idx]=t;nex[idx]=head[s];head[s]=idx;}
map<PII,int>Map;
ll Ans[M];
struct edge{int s,t,tim;}Q[M],Q1[M],Q2[M];
struct Que{int op,s,t,tim;}D[M<<1];
inline int Getid(int x){return lower_bound(b+1,b+1+Cnt,x)-b;}
int tot,rt[N],ls[N<<6],rs[N<<6],siz[N<<6];
ll sum[N<<6];
void Modify(int& t,int vl,int vr,int pos,int v){
if(!t) t=++tot;siz[t]+=v;sum[t]+=v*b[pos];
if(vl==vr) return;int mid=vl+vr>>1;
if(pos<=mid) Modify(ls[t],vl,mid,pos,v);
else Modify(rs[t],mid+1,vr,pos,v);
}
int merge(int rt1,int rt2,int vl,int vr){
if(!rt1||!rt2)return rt1+rt2;
if(vl==vr){siz[rt1]+=siz[rt2];sum[rt1]+=sum[rt2];return rt1;}
int mid=vl+vr>>1;
ls[rt1]=merge(ls[rt1],ls[rt2],vl,mid);
rs[rt1]=merge(rs[rt1],rs[rt2],mid+1,vr);
siz[rt1]=siz[ls[rt1]]+siz[rs[rt1]];
sum[rt1]=sum[ls[rt1]]+sum[rs[rt1]];
return rt1;
}
ll Query(int t,int vl,int vr,int k){
if(vl==vr)return 1ll*k*b[vl];int mid=vl+vr>>1;
if(k<=siz[rs[t]])return Query(rs[t],mid+1,vr,k);
return sum[rs[t]]+Query(ls[t],vl,mid,k-siz[rs[t]]);
}
int Getfa(int x){return Fa[x]==x?x:Getfa(Fa[x]);}
inline void merge(int x,int y){
x=Getfa(x);y=Getfa(y);
if(x==y)return;
if(Siz[x]<Siz[y]) swap(x,y);
Fa[y]=x;stky[++top]=y;
if(Siz[x]==Siz[y]) Siz[x]++,stkx[top]=x;
}
inline void Merge(int x,int y){
x=Getfa(x);y=Getfa(y);
if(x==y)return;
if(Siz[x]<Siz[y])swap(x,y);
Fa[y]=x;
if(Siz[x]==Siz[y])Siz[x]++;
rt[x]=merge(rt[x],rt[y],1,Cnt);
}
int dfn[N],low[N],stk[N],Top,Idx;
bool vis[N];
void Tarjan(int st){
dfn[st]=low[st]=++Idx;
vis[stk[++Top]=st]=true;
for(int i=head[st];i;i=nex[i]){
if(!dfn[to[i]]) Tarjan(to[i]),low[st]=min(low[st],low[to[i]]);
else if(vis[to[i]]) low[st]=min(low[st],dfn[to[i]]);
}
if(dfn[st]==low[st]){
int loc=stk[Top--];
vis[loc]=false;
while(stk[Top+1]!=st){
vis[stk[Top]]=false;
merge(loc,stk[Top--]);
}
}
return ;
}
void Solve(int vl,int vr,int ql,int qr){
if(ql>qr) return;
if(vl==vr){for(int i=ql;i<=qr;i++) Q[i].tim=vl;return;}
int Ncnt=0,ttop=top,mid=vl+vr>>1;
for(int i=ql,s,t;i<=qr;i++){
if(Q[i].tim<=mid){
s=Getfa(Q[i].s);t=Getfa(Q[i].t);
Edge[++Ncnt]=s;Edge[++Ncnt]=t;
Add(s,t);
}
}
for(int i=1;i<=Ncnt;i++) if(!dfn[Edge[i]]) Tarjan(Edge[i]);
int Cnt1=0,Cnt2=0;
for(int i=ql;i<=qr;i++){
if(Getfa(Q[i].s)==Getfa(Q[i].t)&&Q[i].tim<=mid) Q1[++Cnt1]=Q[i];
else Q2[++Cnt2]=Q[i];
}
for(int i=1;i<=Cnt1;i++) Q[ql+i-1]=Q1[i];
for(int i=1;i<=Cnt2;i++) Q[ql+Cnt1+i-1]=Q2[i];
Idx=idx=0;
for(int i=1;i<=Ncnt;i++) head[Edge[i]]=dfn[Edge[i]]=low[Edge[i]]=0;
Solve(mid+1,vr,ql+Cnt1,qr);
while(top!=ttop){
Fa[stky[top]]=stky[top];
if(stkx[top]) Siz[stkx[top]]--;
top--;
}
Solve(vl,mid,ql,ql+Cnt1-1);
return ;
}
inline bool Cmp(Que a,Que b){return a.tim==b.tim?a.op<b.op:a.tim<b.tim;}
int main(){
read(n),read(m),read(q);
for(int i=1;i<=n;i++) read(a[i]),b[++Cnt]=aa[i]=a[i];
for(int i=1;i<=n;i++) Fa[i]=i,Siz[i]=1;
for(int i=1,x,y;i<=m;i++) read(x),read(y),Q[i]=(edge){x,y,0},Map[make_pair(x,y)]=i;
for(int i=1,id;i<=q;i++){
read(op[i]),read(A[i]),read(B[i]);
if(op[i]==1) Q[Map[make_pair(A[i],B[i])]].tim=q-i+1;
if(op[i]==2) b[++Cnt]=aa[A[i]]+B[i],aa[A[i]]+=B[i];
}
Solve(0,q+1,1,m);
for(int i=1;i<=m;i++) D[++Acnt]=(Que){1,Q[i].s,Q[i].t,Q[i].tim};
for(int i=1;i<=q;i++) if(op[i]>1) D[++Acnt]=(Que){op[i],A[i],B[i],q-i+1};
sort(D+1,D+1+Acnt,Cmp);
sort(b+1,b+1+Cnt);Cnt=unique(b+1,b+1+Cnt)-b-1;
for(int i=1;i<=n;i++) Modify(rt[i],1,Cnt,Getid(aa[i]),1),Fa[i]=i;
for(int i=1;i<=n;i++) Fa[i]=i,Siz[i]=1;
memset(Ans,-1,sizeof(Ans));
for(int i=1,x,y;i<=Acnt;i++){
if(D[i].op==1) Merge(D[i].s,D[i].t);
if(D[i].op==2){
y=Getfa(x=D[i].s);
Modify(rt[y],1,Cnt,Getid(aa[x]),-1);
aa[x]-=D[i].t;
Modify(rt[y],1,Cnt,Getid(aa[x]),1);
}
if(D[i].op==3){
x=Getfa(D[i].s);
Ans[q-D[i].tim+1]=Query(rt[x],1,Cnt,min(D[i].t,siz[rt[x]]));
}
}
for(int i=1;i<=q;i++) if(~Ans[i]) write(Ans[i]),putchar('
');
return 0;
}
3月27日
P7469 [NOI Online 2021 提高组] 积木小赛(哈希/SAM)
P7469 [NOI Online 2021 提高组] 积木小赛(哈希/SAM)
cyx是 SAM ,听说复杂度是 (O()本质不同子串个数()),他太强了。
我们比较菜,这里介绍两个做法:
首先,这道题其实很简单,就是在询问我们一个串的所有任意后缀可以和文本串匹配的最长前缀当中的本质不同子串个数。
所以我们可以直接字符串哈希然后排序去重,复杂度 (O(n^2logn)) ,使用 (STL) (set) 也可以。
我们也可以直接哈希,复杂度 (O(n^2)) 。
3月28日
P5384 [Cnoi2019]雪松果树(k 级祖先,差分,dsu on tree)
P5384 [Cnoi2019]雪松果树(k 级祖先,差分,dsu on tree)
首先要求出 k 级祖先,这道题非常恶心卡空间,于是我们考虑重剖求 k 级祖先。
代码:
int QueryKth(int x,int k){
int tmp=dep[x]-k;
while(dep[top[x]]>tmp) x=fa[top[x]];
tmp=dep[x]-tmp;
return rev[dfn[x]-tmp];
}
然后这道题可以直接离线挂询问然后 dsu on tree ,但是正解是 O(n) 的差分。
也就是说,我们在进去的时候记录一下所有询问深度的 (cnt) ,然后出来的时候把两者相减就是这棵树里的信息了。
P3850 [TJOI2007]书架(平衡树)
裸的 (FHQ) (Treap/Splay) ,直接类似 (Map) 处理即可。
CF17E Palisection(manacher)

先直接 manacher ,然后

P1505 [国家集训队]旅游(树链剖分)

树剖板子,路径取反,单点修改,查询路径和,路径最大值,路径最小值。
3月29日
P3804 【模板】后缀自动机 (SAM)
SAM 模板题。
求出 子串出现次数大于 1 的串的出现次数乘上子串长度的值的最大值。
首先每个子串的出现次数其实就是这个子串对应 (endpos) 集合的大小,然后同一个 (endpos) 集合当中最长的肯定是该状态的 (len) (这里只取最长的是贪心,因为 (endpos) 集合此时相同,则字符串越长越好)。
那么 (endpos) 集合大小是常见套路,我们可以直接通过 (parent) 树得到,具体来说对于每一个点就是 (siz_u+=siz_v((u,v)in E)) 。
注意还要初始化。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5;
char str[N];
bool isnode[N<<1];
int tot=1,last=1,siz[N<<1],q[N<<1],c[N<<1],idx;
long long Ans;
struct SAM{int son[26],fa,len;}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;siz[nq]=0;
t[nq]=t[q];t[nq].len=t[p].len+1;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
siz[np]=1;
return ;
}
int main(){
scanf("%s",str);int len=strlen(str);
for(int i=0;i<len;i++) Extend(str[i]-'a');
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--){
siz[t[q[i]].fa]+=siz[q[i]];
if(siz[q[i]]>1) Ans=max(Ans,1ll*siz[q[i]]*t[q[i]].len);
}
write(Ans);
return 0;
}
P4070 [SDOI2016]生成魔咒(SAM)
求本质不同子串个数。
首先要明白为什么是"本质不同子串"。
这其实就是说明:在同一个 (endpos) 集合当中的所有串中,本来出现了 (|endpos(S)|) 个这个串,现在我们这个串只算贡献为 1 。
也就是说,我们可以这样来计算答案:每一个节点对应的贡献,就是 (len_x-len_{fa(x)}) 。(也就是当前这个节点对应的串的个数)
那么答案就是所有节点的和,这里我们可以通过一个一个读入字符,就一个一个统计答案即可。
同时这道题还有一个值得一提的就是其字符集太大,我们可以使用 哈希/Map 来存储。
核心代码:
struct SAM{
map<int,int> son;
int fa,len;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son.count(c)) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
ans+=t[np].len-t[t[np].fa].len;
return ;
}
P3975 [TJOI2015]弦论(SAM)
求字典序第 k 大的子串。
首先我们要想清楚怎么去求这个第 k 大。
我们可以类似线段树上二分的操作,每次贪心的从小到大看,如果当前状态有这个结点,但是如果要去的结点所延伸出去的所有字符串的个数都比 (k) 小,那么就不能这样走下去,需要把经过这个结点的所有子串的数量减去。
然后再循环到下一个字符去,同样看满不满足条件,如果刚好 (kleq siz_v) ,那么就可以去到那个结点。
那么现在的问题变成了如何统计经过一个点的子串个数。
这里有两种求法,第一种就是在 DAG 上 dp ,第二种是利用 parent 树来做。
第一种是这里要用的,因为题目有两种情况,一种是所有排序的子串本质不同,一种是可以相同。
具体怎么做呢?
首先我们要先统计出每个结点的 (endpos) 的大小 (siz)。
然后我们就可以在 DAG 上 dp :一个点被经过,那么就代表从这个点连出去的边都是要经过这个点的串,于是我们可以写出这样一个方程:
含义就是:那个点就是当前点加上一个字符得到的,而加了多少个呢? (siz_v) 个。
那么 dp 结束过后我们就可以得到每一个状态对应的答案了,我们接下来就可以开始匹配。
对于另外一种情况就是把 (siz_v) 换成了 1 。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=2e6+5;
int x,n,last=1,tot=1,type,K,q[N<<1];
long long ans,c[N];
bool flag;
char str[N];
struct SAM{
int son[26];
int fa,len,sum,siz;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[nq].sum=t[nq].siz=0;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
t[np].siz=1;
return ;
}
void Print(int x,int k){
k-=t[x].siz;
if(k<=0) return ;
for(int i=0;i<26;i++){
if(t[x].son[i]){
if(k>t[t[x].son[i]].sum) k-=t[t[x].son[i]].sum;
else return void((putchar(i+'a'),Print(t[x].son[i],k),flag=true));
}
}
return ;
}
int main(){
scanf("%s",str);int len=strlen(str);
for(int i=0;i<len;i++) Extend(str[i]-'a');
read(type),read(K);
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--) t[t[q[i]].fa].siz+=t[q[i]].siz;
for(int i=1;i<=tot;i++) t[i].sum=type?t[i].siz:(t[i].siz=1);
t[1].siz=t[1].sum=0;
for(int i=tot;i>=1;i--) for(int j=0;j<26;j++) t[q[i]].sum+=t[t[q[i]].son[j]].sum;
Print(1,K);
if(!flag) write(-1);
return 0;
}
SP7258 SUBLEX - Lexicographical Substring Search(SAM)
SP7258 SUBLEX - Lexicographical Substring Search(SAM)
这个就是求第 k 大子串的裸题了。
SP1811 LCS - Longest Common Substring(SAM)
SP1811 LCS - Longest Common Substring(SAM)
求两个串的最长公共子串。
我们先对一个串建出一个 SAM ,然后拿另外一个串这样一个字符一个字符匹配:
设当前匹配长度为 (len) ,当前匹配到的状态为 (u) 。
每次查看当前结点是否有出边 (c) ,如果有直接去到状态 (v) ((u,v,c)in E) ,然后 (len++) 结束。
不然就往 (parent) 树的父亲上跳,直到满足条件或者跳到 0 为止。
如果跳到了 0 ,说明无法匹配,那么我们令 (len=0,v=1) ,结束。
这里为什么是正确的?
因为这里就是利用了 SAM 类 AC 自动机的性质,其实我们在 parent 树上跳就可以看作是在 fail 树上跳,也就是不断地缩小后缀(把一部分前缀扔掉)。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=3e5+5;
int x,n,last=1,tot=1,Ans;
bool flag;
char str[N];
struct SAM{
int son[26];
int fa,len,sum,siz;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[nq].sum=t[nq].siz=0;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
t[np].siz=1;
return ;
}
int Len;
void Search(int &x,int c){
if(t[x].son[c]) Len++,x=t[x].son[c];
else{
int p=x;
while(p&&!t[p].son[c]) p=t[p].fa;
if(!p) x=1,Len=0;
else x=t[p].son[c],Len=t[p].len+1;
}
Ans=max(Ans,Len);
return ;
}
int main(){
scanf("%s",str);int len=strlen(str);
for(int i=0;i<len;i++) Extend(str[i]-'a');
scanf("%s",str);len=strlen(str);
for(int i=0,now=1;i<len;i++) Search(now,str[i]-'a');
write(Ans);
return 0;
}
SP1812 LCS2 - Longest Common Substring II(SAM)
SP1812 LCS2 - Longest Common Substring II(SAM)
上一题的多串版本。
主要就是多串的答案应该怎么处理。
我们可以直接先对一个串建出 SAM ,然后用剩下的串每一个匹配,匹配完了更新一下答案。
具体来说大概就是每个状态都会有一个在当前串匹配的最长长度,而对于全局,我们要对所有串的这个状态的答案取 min 即可。
还有就是注意子节点对父亲的影响。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=3e5+5,INF=1e9+7;
int x,n,last=1,tot=1,Ans[N<<1],AAns[N<<1],ans,c[N],q[N<<1];
bool flag;
char str[N];
struct SAM{
int son[26];
int fa,len;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return ;
}
int Len;
void Search(int &x,int c){
if(t[x].son[c]) Len++,x=t[x].son[c],AAns[x]=max(AAns[x],Len);
else{
int p=x;
while(p&&!t[p].son[c]) p=t[p].fa;
if(!p) x=1,Len=0;
else x=t[p].son[c],Len=t[p].len+1,AAns[x]=max(AAns[x],Len);
}
return ;
}
int main(){
scanf("%s",str);int len=strlen(str);
for(int i=0;i<len;i++) Extend(str[i]-'a');
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=0;i<=tot;i++) Ans[i]=INF;
while(~scanf("%s",str)){
if(str[0]=='0') break;
len=strlen(str);Len=0;
for(int i=0,now=1;i<len;i++) Search(now,str[i]-'a');
for(int i=tot;i>=1;i--){
int x=q[i];
AAns[t[x].fa]=max(AAns[t[x].fa],min(AAns[x],t[t[x].fa].len));
Ans[x]=min(Ans[x],AAns[x]);AAns[x]=0;
}
}
for(int i=1;i<=tot;i++) ans=max(ans,Ans[i]);
write(ans);
return 0;
}
SP10570 LONGCS - Longest Common Substring(SAM)
SP10570 LONGCS - Longest Common Substring(SAM)
和上两题一样,但是这里要注意的是多组数据的清空,一个都不能少!
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=2e4+5,INF=1e9+7;
int x,n,last=1,tot=1,Ans[N<<1],AAns[N<<1],ans,c[N],q[N<<1];
bool flag;
char str[N];
struct SAM{
int son[26];
int fa,len;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return ;
}
int Len;
void Search(int &x,int c){
if(t[x].son[c]) Len++,x=t[x].son[c],AAns[x]=max(AAns[x],Len);
else{
int p=x;
while(p&&!t[p].son[c]) p=t[p].fa;
if(!p) x=1,Len=0;
else x=t[p].son[c],Len=t[p].len+1,AAns[x]=max(AAns[x],Len);
}
return ;
}
int main(){
int T;
read(T);
while(T--){
int tt;
read(tt);tt--;
scanf("%s",str);int len=strlen(str);tot=last=1;ans=0;Len=0;
for(int i=0;i<len;i++) Extend(str[i]-'a');
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=0;i<=tot;i++) Ans[i]=INF;
while(tt--){
scanf("%s",str);
len=strlen(str);Len=0;
for(int i=0,now=1;i<len;i++) Search(now,str[i]-'a');
for(int i=tot;i>=1;i--){
int x=q[i];
AAns[t[x].fa]=max(AAns[t[x].fa],min(AAns[x],t[t[x].fa].len));
Ans[x]=min(Ans[x],AAns[x]);AAns[x]=0;
}
}
for(int i=1;i<=tot;i++) ans=max(ans,Ans[i]),Ans[i]=AAns[i]=c[i]=q[i]=0;
for(int i=1;i<=tot;i++){
t[i].fa=t[i].len=0;
for(int j=0;j<26;j++) t[i].son[j]=0;
}
write(ans);putchar('
');
}
return 0;
}
P2408 不同子串个数(SAM)
给一个字符串,求本质不同子串个数。
本质不同其实就是把一个 endpos 集合内的字符串,原本该有 (|S|) 个该子串,现在只算一次而已。
那么我们直接把当前节点代表的串的个数加上即可。
也就是每次加字符的时候 (Ans+=len[x]-len[fa[x]]) 。
CF802I Fake News (hard)(SAM)
求区间本质不同子串出现次数平方和。
把柿子改成 (Ans+=(len[x]-len[fa[x]])*(siz[x])^2) 即可。
CF123D String(SAM)

还是直接改柿子变成 (Ans+=(len[x]-len[fa[x]])*(siz[x]*(siz[x]+1)/2)) 就行了。
CF235C Cyclical Quest(SAM)
把 SAM 当成 AC 自动机来使用。
首先是常见套路,把每个串复制一遍。
然后我们把每个串拿到 SAM 上面匹配,匹配不成功就可以跳 parent 树,这个其实本质就是相当于 AC 自动机的跳 Fail 树。
然后注意可能重复,所以每一个串都要打标记,只统计一次,还有就是如果一个串可以那么我们要尽量向上跳,因为我们要尽量多匹配个数。
最后答案就是那些结点的 siz 之和。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5;
#define int long long
int x,n,last=1,tot=1,c[N<<1],q[N<<1],T,vis[N<<1];
long long Ans;
bool flag;
char str[N];
struct SAM{
int son[26];
int fa,len,siz;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[nq].siz=0;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
t[np].siz=1;
return ;
}
void Search(int &x,int &len,int c,int tim){
if(t[x].son[c]) len++,x=t[x].son[c];
else{
int p=x;
while(p&&!t[p].son[c]) p=t[p].fa;
if(!p) len=0,x=1;
else len=t[p].len+1,x=t[p].son[c];
}
if(len<T) return ;
while(t[t[x].fa].len>=T) x=t[x].fa;
if(vis[x]!=tim) Ans+=t[x].siz,vis[x]=tim;
return ;
}
signed main(){
scanf("%s",str);int len=strlen(str);
for(int i=0;i<len;i++) Extend(str[i]-'a');
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--) t[t[q[i]].fa].siz+=t[q[i]].siz;
read(n);
for(int i=1;i<=n;i++){
scanf("%s",str);len=strlen(str);T=len;Ans=0;
for(int j=0;j<len;j++) str[j+len]=str[j];
for(int j=0,now=1,Len=0;j<len+len;j++) Search(now,Len,str[j]-'a',i);
write(Ans);putchar('
');
}
return 0;
}
P6640 [BJOI2020] 封印(SAM)
给定一个串,每次给定一个区间,询问这这个子串和一个串 T 的 LCP 。(T最开始给定)
SAM 经典应用:SAM可以求出每一个位置作为右端点和另外一个串的最大匹配长度。
具体做法是对“另外一个串”建SAM然后拿当前串一位一位去匹配。
也就是说,我们先这样求一下,然后我们的目的就是找到 ([l,r]) 当中的 (max{(min{(Len[i],i-l+1)})}) 。

代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5;
#define int long long
int x,n,last=1,tot=1,c[N<<1],q[N<<1],T,vis[N<<1],L[N],Le[N];
long long Ans;
bool flag;
char str[N],str1[N];
struct SAM{
int son[26];
int fa,len,siz;
}t[N<<1];
void Extend(int c){
int p=last,np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[p].len+1==t[q].len) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[nq].siz=0;
t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
t[np].siz=1;
return ;
}
void Search(int &x,int &len,int c){
if(t[x].son[c]) len++,x=t[x].son[c];
else{
int p=x;
while(p&&!t[p].son[c]) p=t[p].fa;
if(!p) len=0,x=1;
else len=t[p].len+1,x=t[p].son[c];
}
return ;
}
struct ST{
int maxn[300000][20],n,lg[300000];
void init(int *a,int nn){
n=nn;lg[0]=-1;for(int i=1;i<=n;i++)lg[i]=lg[i>>1]+1;
for(int i=1;i<=n;i++)maxn[i][0]=a[i];
for(int j=1;(1<<j)<=n;j++){
for(int i=1;i+(1<<j)-1<=n;i++){
maxn[i][j]=max(maxn[i][j-1],maxn[i+(1<<(j-1))][j-1]);
}
}
}
int query(int l,int r){
int len=lg[r-l+1];
return max(maxn[l][len],maxn[r-(1<<len)+1][len]);
}
}M;
signed main(){
scanf("%s",str);scanf("%s",str1);int len1=strlen(str),len2=strlen(str1);
for(int i=0;i<len2;i++) Extend(str1[i]-'a');
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--) t[t[q[i]].fa].siz+=t[q[i]].siz;
for(int i=0,now=1,Len=0;i<len1;i++) Search(now,Len,str[i]-'a'),Le[i+1]=Len,L[i+1]=i+1-Len+1;
M.init(Le,len2);
int q=0;read(q);
while(q--){
int l,r;
read(l),read(r);
if(L[l]>=l){printf("%d
",M.query(l,r));}
else if(L[r]<=l){printf("%d
",r-l+1);}
else{
int p=lower_bound(L+l,L+r+1,l)-L;
printf("%d
",max(p-l,M.query(p,r)));
}
}
return 0;
}
3月30日
P5341 [TJOI2019]甲苯先生和大中锋的字符串(SAM)
P5341 [TJOI2019]甲苯先生和大中锋的字符串(SAM)
求一个串中出现 k 次的子串中出现次数的最多的长度。
先统计 endpos 集合大小,也就是出现次数,然后维护子串长度的值域的前缀和即可。
P6272 [湖北省队互测2014]没有人的算术(替罪羊树)
P6272 [湖北省队互测2014]没有人的算术(替罪羊树)

第二个询问操作直接就是询问区间最大值,平凡维护即可。
重点在于修改 pair 操作怎么维护。
我们考虑通过维护中位数来做。
也就是说,对于一个数 pair<X,Y> ,我们以 X 集合作为第一关键字, Y 作为第二关键字,现在我们要用一个数 (mid) 来表示 pair<X,Y> 。
那么其实这就相当于每次赋值的时候,第一关键字是数 (V_l) ,第二关键字是数 (V_r) ,我们把 (V_k) 赋成两者中位数即可。
同时这里的相对顺序不能旋转,于是考虑替罪羊树,而每次重构的时候重新维护代表值即可。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char ch=getchar();bool f=false;
while(!isdigit(ch)){if(ch=='-'){f=true;}ch=getchar();}
while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=5e5+5;
const double alpha=0.75;
double a[N];
struct PII{
int l,r;
inline bool operator<(PII x){return a[l]==a[x.l]?a[r]<a[x.r]:a[l]<a[x.l];}
inline bool operator==(PII x){return l==x.l&&r==x.r;}
inline bool operator>(PII x){return !((*this)<x)&&!((*this)==x);}
};
int n,m,root,pos[N],tot,top,siz[N],ls[N],rs[N],len,Q[N];
PII val[N];
void dfs(int t){if(!t)return;dfs(ls[t]);Q[++len]=t;dfs(rs[t]);}
void Build(int& t,int l,int r,double L,double R){
if(l>r)return (void)(t=0);
double Mid=(L+R)/2;int mid=l+r>>1;
t=Q[mid];a[t]=Mid;
Build(ls[t],l,mid-1,L,Mid);
Build(rs[t],mid+1,r,Mid,R);
siz[t]=siz[ls[t]]+siz[rs[t]]+1;
return ;
}
void ReBuild(int& t,double L,double R){len=0;dfs(t);Build(t,1,len,L,R);}
int Insert(int& t,double L,double R,PII v){
double Mid=(L+R)/2;
if(!t){
t=++tot;siz[t]=1;val[t]=v;
a[t]=Mid;return t;
}
if(v==val[t])return t;
siz[t]++;int res=0;
if(v<val[t])res=Insert(ls[t],L,Mid,v);
else res=Insert(rs[t],Mid,R,v);
if(max(siz[ls[t]],siz[rs[t]])<siz[t]*alpha){
if(top){
if(ls[t]==top)ReBuild(ls[t],L,Mid);
else ReBuild(rs[t],Mid,R);top=0;
}
}
else top=t;
return res;
}
#define ls (t<<1)
#define rs (t<<1|1)
int Maxn[N];
void Modify(int t,int l,int r,int pos){
if(l==r)return (void)(Maxn[t]=l);int mid=l+r>>1;
if(pos<=mid) Modify(ls,l,mid,pos);
else Modify(rs,mid+1,r,pos);
if(a[::pos[Maxn[ls]]]>=a[::pos[Maxn[rs]]])Maxn[t]=Maxn[ls];
else Maxn[t]=Maxn[rs];
}
int Query(int t,int l,int r,int a,int b){
if(a<=l&&r<=b)return Maxn[t];int mid=l+r>>1;
if(b<=mid)return Query(ls,l,mid,a,b);
if(a>mid)return Query(rs,mid+1,r,a,b);
int pl=Query(ls,l,mid,a,mid),pr=Query(rs,mid+1,r,mid+1,b);
if(::a[pos[pl]]>=::a[pos[pr]])return pl;
else return pr;
}
int main(){
read(n),read(m);
a[0]=-1;
Insert(root,0,1,(PII){0,0});
for(int i=1;i<=n;i++) pos[i]=1;
for(int i=1;i<=n;i++) Modify(1,1,n,i);
while(m--){
char op[5];int l,r,x;
scanf("%s",op),read(l),read(r);
if(op[0]=='C'){
read(x);
pos[x]=Insert(root,0,1,(PII){pos[l],pos[r]});
if(top) ReBuild(root,0,1),top=0;
Modify(1,1,n,x);
}
if(op[0]=='Q') write(Query(1,1,n,l,r)),putchar('
');
}
return 0;
}
P6139 【模板】广义后缀自动机(广义 SAM)
广义 SAM 模板题。
和 SAM 的唯一区别就是特判不需要修改的点,而如果新用一个串要重置 last=1 。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool f=false;
while(!isdigit(c)){if(c=='-'){f=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5;
int n;
long long ans;
char str[N];
int last=1,tot=1;
struct SuffixAutoMaton{int son[26],fa,len;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
int main(){
read(n);
for(int i=1;i<=n;i++){
scanf("%s",str);int len=strlen(str);last=1;
for(int j=0;j<len;j++) last=Extend(str[j]-'a');
}
for(int i=1;i<=tot;i++) ans+=t[i].len-t[t[i].fa].len;
write(ans);
return 0;
}
3月31日
SP8093 JZPGYZ - Sevenk Love Oimaster(广义SAM)
SP8093 JZPGYZ - Sevenk Love Oimaster(广义SAM)
广义 SAM 和 AC 自动机的结合。
首先我们插入模板串的时候,每次在每一个前缀的对应结点打一个标记。
然后我们一个串成为这个串的子串本质就是这个串在那个匹配串的子树当中。
那么其实我们对于每一个询问,那就是子树数颜色,如果打一个 DFN 序就是区间数颜色问题,直接离线+树状数组解决。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool f=false;
while(!isdigit(c)){if(c=='-'){f=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5;
int n,m;
long long Ans[N];
char str[N];
int last=1,tot=1,now=1;
struct SuffixAutoMaton{int son[26],fa,len;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
vector<int> vec[N<<1];
struct Query{int l,r,id,node;}Q[N];
int dfn[N<<1],DFN,c[N<<1],Cnt,siz[N<<1],pre[N<<1],rev[N<<1];
void Add(int x,int v){for(;x<=DFN;x+=(x&(-x))) c[x]+=v;return ;}
int Ask(int x){int res=0;for(;x;x-=(x&(-x))) res+=c[x];return res;}
int head[N<<1],to[N<<1],nex[N<<1],idx;
void add(int u,int v){
nex[++idx]=head[u];
to[idx]=v;
head[u]=idx;
return ;
}
void Dfs(int x){
dfn[x]=++DFN,rev[DFN]=x;siz[x]=1;
for(int i=head[x];i;i=nex[i]){
int y=to[i];
Dfs(y);siz[x]+=siz[y];
}
return ;
}
inline bool cmp(Query x,Query y){return x.r<y.r;}
void Search(char *s,int id){
int len=strlen(s);now=1;
for(int i=0;i<len;i++){
int c=s[i]-'a';
if(t[now].son[c]) now=t[now].son[c];
else return ;
}
Q[++Cnt].id=id,Q[Cnt].l=dfn[now],Q[Cnt].r=dfn[now]+siz[now]-1;
return ;
}
int main(){
read(n),read(m);
for(int i=1;i<=n;i++){
scanf("%s",str);int len=strlen(str);last=1;
for(int j=0;j<len;j++) last=Extend(str[j]-'a'),vec[last].push_back(i);
}
for(int i=2;i<=tot;i++) add(t[i].fa,i);
Dfs(1);
for(int i=1;i<=m;i++){scanf("%s",str);Search(str,i);}
sort(Q+1,Q+Cnt+1,cmp);
for(int i=1,pos=1;i<=Cnt;i++){
int x=rev[pos];
while(pos<=Q[i].r){
for(auto c:vec[x]){
if(pre[c]) Add(pre[c],-1);
Add(pre[c]=pos,1);
}
x=rev[++pos];
}
Ans[Q[i].id]=Ask(Q[i].r)-Ask(Q[i].l-1);
}
for(int i=1;i<=m;i++) write(Ans[i]),putchar('
');
return 0;
}
P3346 [ZJOI2015]诸神眷顾的幻想乡(广义SAM)
P3346 [ZJOI2015]诸神眷顾的幻想乡(广义SAM)
稍微思考一下题意就转变成为:树上的所有路径构成的所有串的全局的本质不同子串的个数。
但是我们发现这样会有很多串而且很多重复的。
那么我们根据性质:其实我们如果把所有的叶子结点依次当做树的根,然后求一遍到所有当前叶子结点的串,再加入SAM即可。
然后再求一遍本质不同子串个数即可。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool f=false;
while(!isdigit(c)){if(c=='-'){f=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5,INF=1e9+7;
int n,m,str[N],s[N];
long long Ans;
int last=1,tot=1,now=1;
struct SuffixAutoMaton{int son[11],fa,len;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
int nex[N<<1],to[N<<1],head[N],vis[N],idx;
void add(int u,int v){
nex[++idx]=head[u];
to[idx]=v;
head[u]=idx;
return ;
}
void dfs(int x,int fa,int ls){
last=ls;
int now=Extend(s[x]);
for(int i=head[x];i;i=nex[i]){
int y=to[i];
if(y==fa) continue;
dfs(y,x,now);
}
return ;
}
int main(){
read(n),read(m);
for(int i=1;i<=n;i++) read(s[i]);
for(int i=1,u,v;i<n;i++){
read(u),read(v);
add(u,v);add(v,u);
vis[u]++,vis[v]++;
}
for(int i=1;i<=n;i++) if(vis[i]==1) dfs(i,0,1);
for(int i=1;i<=tot;i++) Ans+=t[i].len-t[t[i].fa].len;
write(Ans);
return 0;
}
CF427D Match & Catch(广义SAM)
就是我们把两个串加入广义 SAM 然后找所有的 siz 为 1 且在两个串都出现的结点的对应最小 (len) 的全局最小值就是答案。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool f=false;
while(!isdigit(c)){if(c=='-'){f=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=1e6+5,INF=1e9+7;
int n,m,siz[N<<1][2],q[N<<1],c[N<<1],Ans;
bool vis[N<<1][2];
char str[N];
int last=1,tot=1,now=1;
struct SuffixAutoMaton{int son[26],fa,len;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
int main(){
scanf("%s",str);int len=strlen(str);Ans=INF;
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),vis[last][0]=true,siz[last][0]=1;
scanf("%s",str);last=1;len=strlen(str);
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),vis[last][1]=true,siz[last][1]=1;
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--){
int x=q[i];
siz[t[x].fa][0]+=siz[x][0];
siz[t[x].fa][1]+=siz[x][1];
}
for(int i=2;i<=tot;i++) if(siz[i][0]==1&&siz[i][1]==1) Ans=min(Ans,t[t[i].fa].len+1);
write(Ans==INF?-1:Ans);
return 0;
}
CF452E Three strings(广义 SAM)
求在三个串都出现的子串的出现次数的乘积的总和(可重)。
先直接广义 SAM 然后统计每个结点分别对于串 (A,B,C) 的出现次数,然后在值域上差分一下即可。
代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool f=false;
while(!isdigit(c)){if(c=='-'){f=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=3e5+5,INF=1e9+7,MOD=1e9+7;
#define inc(x,y) (x+y>=MOD?x+y-MOD:x+y)
int n,m,siz[N<<1][3],q[N<<1],c[N<<1],d[N<<1];
char str[N];
int last=1,tot=1,now=1;
struct SuffixAutoMaton{int son[26],fa,len;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
int main(){
scanf("%s",str);int len=strlen(str);int L=len;
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),siz[last][0]=1;
scanf("%s",str);last=1;len=strlen(str);L=min(L,len);
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),siz[last][1]=1;
scanf("%s",str);last=1;len=strlen(str);L=min(L,len);
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),siz[last][2]=1;
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--){
int x=q[i];
siz[t[x].fa][0]=inc(siz[t[x].fa][0],siz[x][0]);
siz[t[x].fa][1]=inc(siz[t[x].fa][1],siz[x][1]);
siz[t[x].fa][2]=inc(siz[t[x].fa][2],siz[x][2]);
}
for(int i=2;i<=tot;i++){
d[t[t[i].fa].len+1]=inc(d[t[t[i].fa].len+1],1ll*siz[i][0]*siz[i][1]*siz[i][2]%MOD);
d[t[i].len+1]=inc((d[t[i].len+1]-1ll*siz[i][0]*siz[i][1]*siz[i][2]%MOD),MOD);
}
for(int i=1;i<=L;i++) d[i]=inc(d[i],d[i-1]),write(d[i]),putchar(' ');
return 0;
}
P3181 [HAOI2016]找相同字符(广义SAM)
先是求出所有在两个串中都出现的子串,然后就是 (Sigma{ siz_1 * siz_2 }) 即可。
具体见题解。

代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool f=false;
while(!isdigit(c)){if(c=='-'){f=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=f?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=4e5+5,INF=1e9+7;
#define inc(x,y) (x+y>=MOD?x+y-MOD:x+y)
int n,m,q[N<<1],c[N<<1];
char str[N];
int last=1,tot=1,now=1;
long long Ans,d[N<<1],siz[N<<1][2];
struct SuffixAutoMaton{int son[26],fa,len;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
int main(){
scanf("%s",str);int len=strlen(str);
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),siz[last][0]=1;
scanf("%s",str);last=1;len=strlen(str);
for(int i=0;i<len;i++) last=Extend(str[i]-'a'),siz[last][1]=1;
for(int i=1;i<=tot;i++) c[t[i].len]++;
for(int i=1;i<=tot;i++) c[i]+=c[i-1];
for(int i=1;i<=tot;i++) q[c[t[i].len]--]=i;
for(int i=tot;i>=1;i--){
int x=q[i];
siz[t[x].fa][0]+=siz[x][0];
siz[t[x].fa][1]+=siz[x][1];
}
for(int i=2;i<=tot;i++){
d[t[t[i].fa].len+1]+=siz[i][0]*siz[i][1];
d[t[i].len+1]-=siz[i][0]*siz[i][1];
}
for(int i=1;i<=len;i++) d[i]+=d[i-1],Ans+=d[i];
write(Ans);
return 0;
}
CF653F Paper task(SAM)
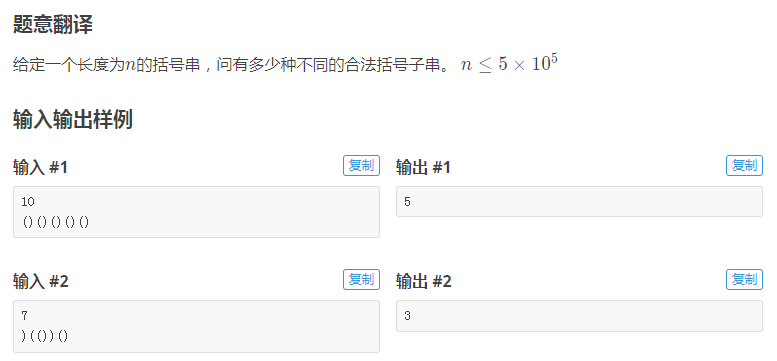
见题解。

代码:
#include<bits/stdc++.h>
using namespace std;
template <typename T>
inline void read(T &x){
x=0;char c=getchar();bool fa=false;
while(!isdigit(c)){if(c=='-'){fa=true;}c=getchar();}
while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();}
x=fa?-x:x;
return ;
}
template <typename T>
inline void write(T x){
if(x<0) putchar('-'),x=-x;
if(x>9) write(x/10);
putchar(x%10^48);
return ;
}
const int N=5e5+5,INF=1e9+7;
#define inc(x,y) (x+y>=MOD?x+y-MOD:x+y)
int n,m,siz[N<<1][2],q[N<<1],c[N<<1],d[N<<1];
char str[N];
int last=1,tot=1,now=1;
long long Ans;
struct SuffixAutoMaton{int son[2],fa,len,ed;}t[N<<1];
int Extend(int c){
int p=last;
if(t[p].son[c]){
int q=t[p].son[c];
if(t[q].len==t[p].len+1) return q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
return nq;
}
}
p=last;int np=++tot;last=np;
t[np].len=t[p].len+1;
while(p&&!t[p].son[c]) t[p].son[c]=np,p=t[p].fa;
if(!p) t[np].fa=1;
else{
int q=t[p].son[c];
if(t[q].len==t[p].len+1) t[np].fa=q;
else{
int nq=++tot;
t[nq]=t[q];t[nq].len=t[p].len+1;t[np].fa=t[q].fa=nq;
while(p&&t[p].son[c]==q) t[p].son[c]=nq,p=t[p].fa;
}
}
return np;
}
vector<int> p[N<<1],g[N<<1];
int ST[20][N],Log[N],s[N];
int qry(int l,int r){
int k=Log[r-l+1];
return min(ST[k][l],ST[k][r-(1<<k)+1]);
}
long long ans;
void dfs(int u){
for(int i=0;i<g[u].size();i++){
dfs(g[u][i]);
t[u].ed=t[g[u][i]].ed;
}
int ed=t[u].ed,l=ed-t[u].len+1,sr=ed-t[t[u].fa].len,mid,r=sr+1;
while(l<r){
mid=(l+r)>>1;
if(qry(mid,ed)>=s[ed+1]) r=mid;
else l=mid+1;
}
ans+=upper_bound(p[n+s[ed+1]].begin(),p[n+s[ed+1]].end(),sr)-lower_bound(p[n+s[ed+1]].begin(),p[n+s[ed+1]].end(),r);
return ;
}
int main(){
read(n);scanf("%s",str+1);
for(int i=n;i;i--) ST[0][i]=s[i]=s[i+1]+((str[i]=='(' ? -1 : 1));
for(int i=1;i<=n+1;i++) p[n+s[i]].push_back(i);
for(int i=2;i<=n;i++) Log[i]=Log[i>>1]+1;
for(int j=1;(1<<j)<=n;j++) for(int i=1;i<=n;i++) ST[j][i]=min(ST[j-1][i],ST[j-1][i+(1<<j-1)]);
for(int i=1;i<=n;i++) Extend(str[i]-'(');
for(int i=1,p=1;i<=n;i++) t[p=t[p].son[str[i]-'(']].ed=i;
for(int i=2;i<=tot;i++) g[t[i].fa].push_back(i);
dfs(1);
write(ans);
return 0;
}