前几天写过一篇《Elasticsearch 7.x 最详细安装及配置》,今天继续最新版基础入门内容。这一篇简单总结了 Elasticsearch 7.x 之文档、索引和 REST API。
- 什么是文档
- 文档Unique ID
- 文档元数据
- 什么是索引
- REST API
一、索引文档(Document)
1.1 白话什么是文档
从使用案例出发,Elasticsearch 是面向文档,文档是所有搜索数据的最小单元。
-
案例一:每个公司都有业务日志平台,比如交易业务日志。
文档:每一条日志文件中的日志项,就是文档 -
案例二:可以搜索并播放电影的在线视频网站
文档:每一个电影的具体信息,就是文档 -
案例三:可以搜索并下载文件的云存储网站,类似百度云
文档:每一个文件具体内容信息,就是文档
等等案例很多,那么文档就是类似数据库里面的一条长长的存储记录。文档(Document)是索引信息的基本单位。
文档被序列化成为 JSON 格式,物理保存在一个索引中。JSON 是一种常见的互联网数据交换格式:
- 文档字段名:JSON 格式由 name/value pairs 组成,对应的 name 就是文档字段名
- 文档字段类型:每个字段都有对应的字段类型:String、integer、long 等,并支持数据&嵌套
1.2 文档的 Unique ID
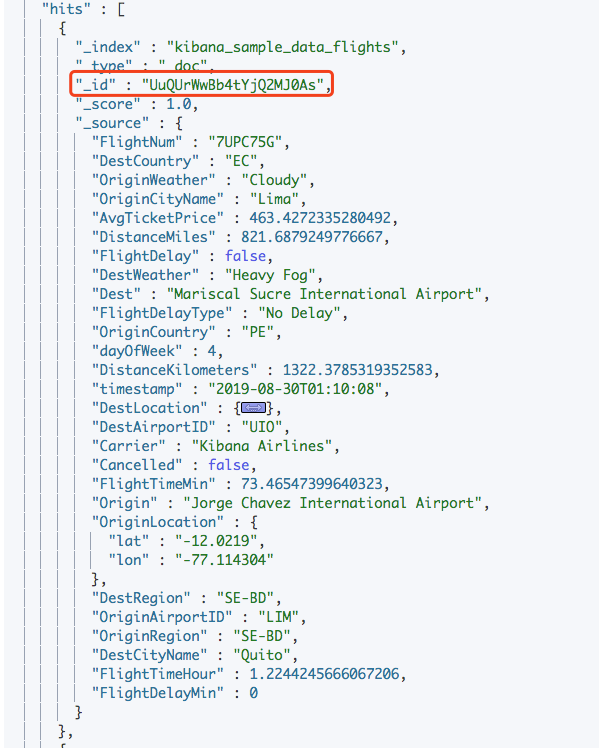
每个文档都会有一个 Unique ID,其字段名称为 _id :
- 自行设置指定 ID 或通过 Elasticsearch 自动生成
- 其值不会被索引
- 注意:该 _id 字段的值可以在某些查询 term, terms, match, query_string, simple_query_string 等中访问,但不能在 aggregations,scripts 或 sorting 中使用。如果需要对 _id 字段进行排序或汇总,建议新建一个文档字段复制 _id 字段的内容
PUT my_index/_doc/1
{
"text": "Document with ID 1"
}
PUT my_index/_doc/2&refresh=true
{
"text": "Document with ID 2"
}
GET my_index/_search
{
"query": {
"terms": {
"_id": [ "1", "2" ]
}
}
}
1.3 文档元数据

元数据是用于标注文档的相关信息,那么索引文档的元数据如下:
- _index 文档所属索引名称
- _type 文档所属类型名
- _id 文档唯一 ID
- _score 文档相关性打分
- _source 文档 JSON 数据
- _version 文档版本信息
其中 _type 文档所属类型名,需要关注版本不同之间区别:
- 7.0 之前,一个索引可以设置多个 types
- 7.0 开始,被 Deprecated 了。一个索引只能创建一个 type,值为 _doc
二、索引(Index)
2.1 索引不同意思
作为名词,索引代表是在 Elasticsearch 集群中,可以创建很多不同索引。也是本小节要总结的内容。
作为动词,索引代表保存一个文档到 Elasticsearch。就是在 Elasticsearch 创建一个倒排索引的意思
2.2 什么是索引
索引,就是相似类型文档的集合。类似 Spring Bean 容器装载着很多 Bean ,ES 索引就是文档的容器,是一类文档的集合。
以前导入了 kibana_sample_data_flights 索引,通过 GET 下面这个 URL ,就能得到索引一些信息:
GET http://localhost:9200/kibana_sample_data_flights
结果如下:
{
"kibana_sample_data_flights": {
"aliases": {},
"mappings": {
"properties": {
"AvgTicketPrice": {
"type": "float"
},
"Cancelled": {
"type": "boolean"
},
"Carrier": {
"type": "keyword"
},
"DestLocation": {
"type": "geo_point"
},
"FlightDelay": {
"type": "boolean"
},
"FlightDelayMin": {
"type": "integer"
},
"timestamp": {
"type": "date"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-1",
"blocks": {
"read_only_allow_delete": "true"
},
"provided_name": "kibana_sample_data_flights",
"creation_date": "1566271868125",
"number_of_replicas": "0",
"uuid": "SfR20UNiSLKJWIpR1bcrzQ",
"version": {
"created": "7020199"
}
}
}
}
}
根据返回结果,我们知道:
- mappings:定义文档字段的类型
- settings:定义不同数据分布
- aliases:定义索引的别名,可以通过别名访问该索引
索引,是逻辑空间概念,每个索引有对那个的 Mapping 定义,对应的就是文档的字段名和字段类型。相比后面会讲到分片,是物理空间概念,索引中存储数据会分散到分片上。
实战经验总结:aliases 别名大有作为,比如 my_index 迁移到 my_index_new , 数据迁移后,只需要保持一致的别名配置。那么通过别名访问索引的业务方都不需要修改,直接迁移即可。
2.3 跟 MySQL 类比
基本理解了 Elasticsearch 重要的两个概念,可以将 ES 关键点跟关系型数据库类比如下:

三、REST API 方便 ES 被各种语言调用
如图,Elasticsearch 提供了 REST API,方便,相关索引 API 如下:
# 查看索引相关信息
GET kibana_sample_data_ecommerce
# 查看索引的文档总数
GET kibana_sample_data_ecommerce/_count
# 查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search
{
}
# _cat indices API
# 查看indices
GET /_cat/indices/kibana*?v&s=index
# 查看状态为绿的索引
GET /_cat/indices?v&health=green
# 按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
# 查看具体的字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt
# How much memory is used per index?
GET /_cat/indices?v&h=i,tm&s=tm:desc
具体 API 可以通过 POSTMan 等工具操作,或者安装 kibana ,对应的 Dev Tools
工具进行访问。
(完),更多可以看 ES 7.x 系列教程 bysocket.com
资料:
- Elasticsearch 7.x 最详细安装及配置
https://www.bysocket.com/elasticsearch/2417.html - 极客时间 Elasticsearch核心技术与实战
- CAT Index API https://www.elastic.co/guide/en/elasticsearch/reference/7.1/cat-indices.html
- 为什么不再支持单个Index下,多个Tyeps https://www.elastic.co/cn/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0
转载,请保留原文地址,谢谢 ~