pandas介绍
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
它是使Python成为强大而高效的数据分析环境的重要因素之一。
pandas基础
import pandas
food_info=pandas.read_csv("food_info.csv")
print(type(food_info))
print(food_info.dtypes)
print(food_info.head(3))
print(food_info.tail(4))
print(food_info.columns)
print(food_info.shape)
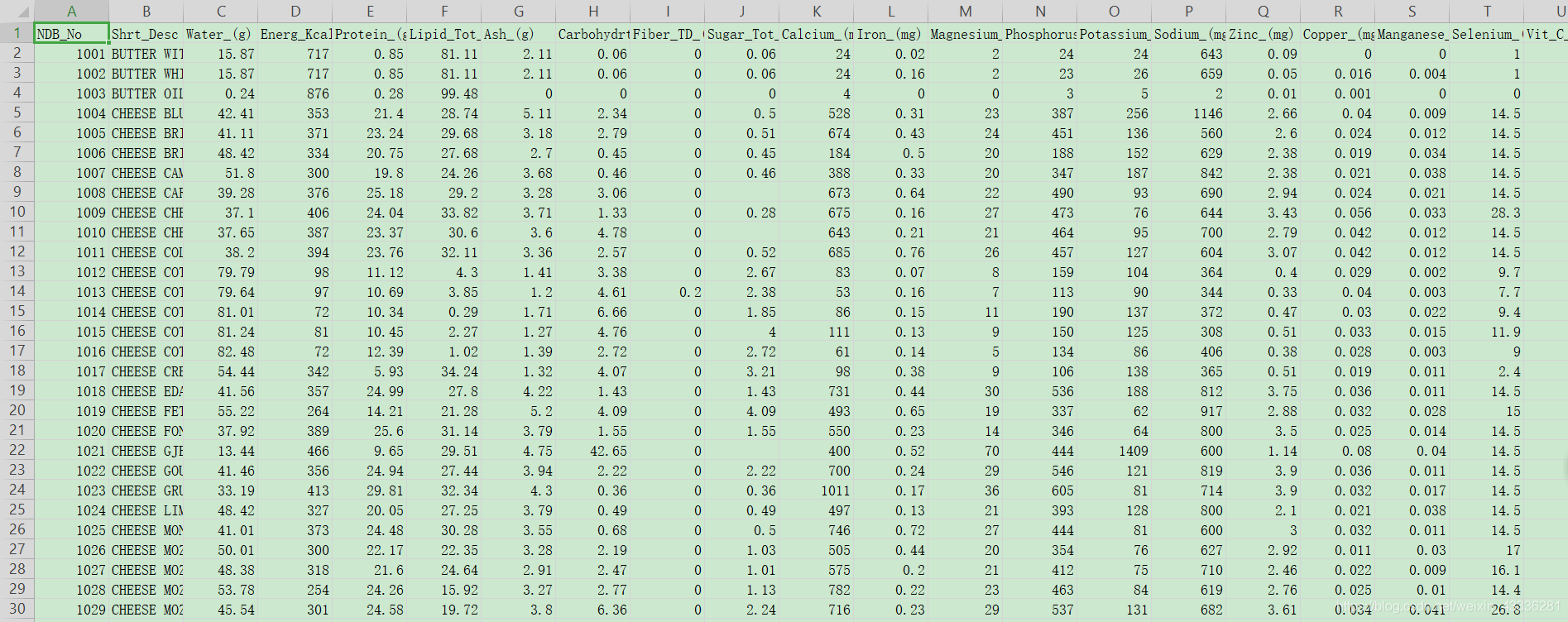
打开一个文件:
food_info=pandas.read_csv("food_info.csv")
文件截图:
打印它的类型:
print(type(food_info))

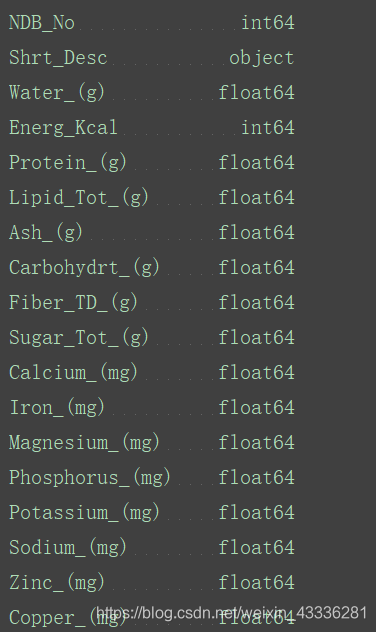
打印每一列的类型:
print(food_info.dtypes)
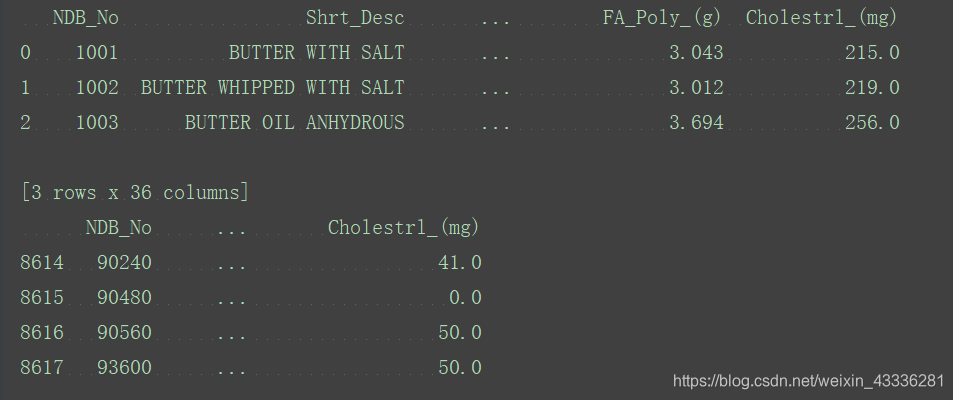
打印头三行和尾四行:
print(food_info.head(3))
print(food_info.tail(4))
打印所有的列标题和文件规模:
print(food_info.columns)
print(food_info.shape)

(8618表示样本,即行,36表示指标,即列)
打印第一行:
print(food_info.loc[0])

切片操作:
print(food_info.loc[3:6])

取出某一列值要根据列名:
ndb_col=food_info["NDB_No"]
print(ndb_col)
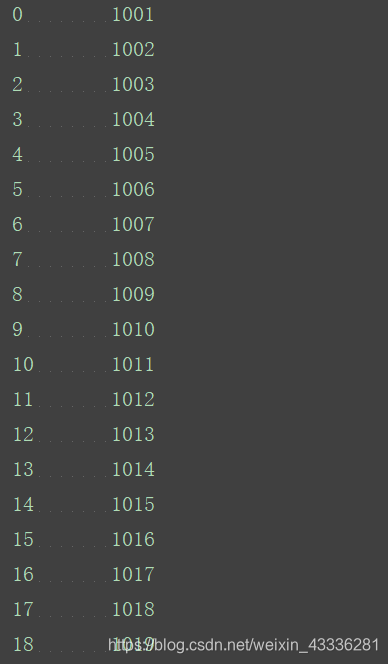
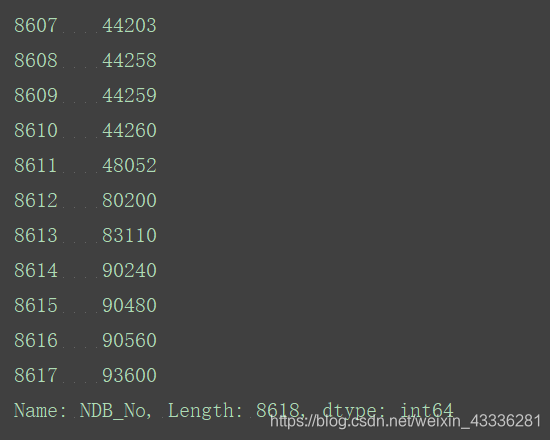
取出某几列的值,同样也是根据列名:
columns=["Shrt_Desc","Water_(g)"]
zinc_copper=food_info[columns]
print(zinc_copper)
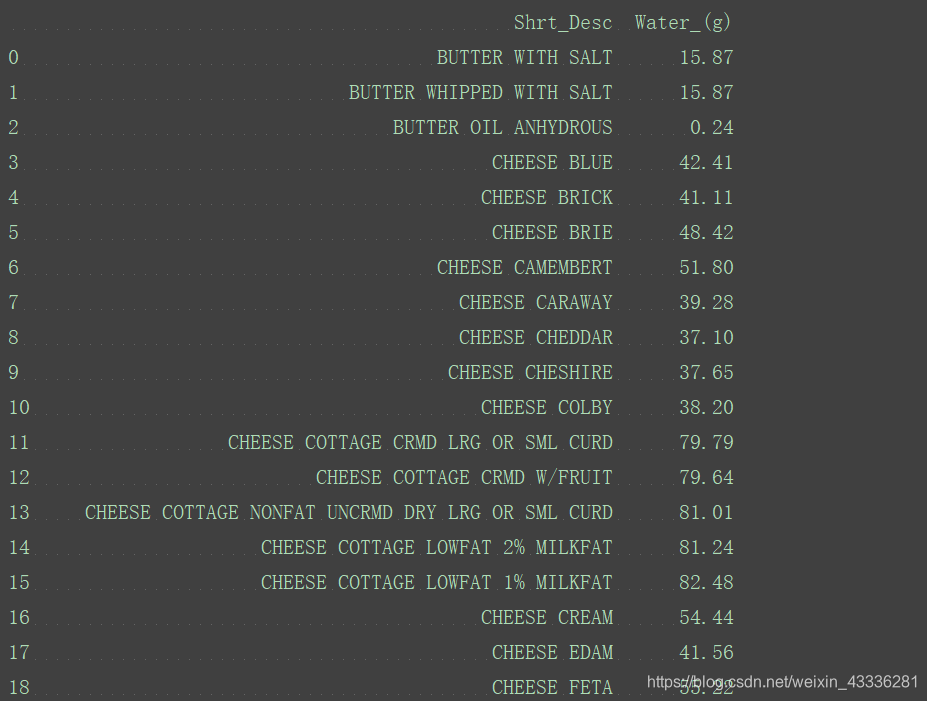
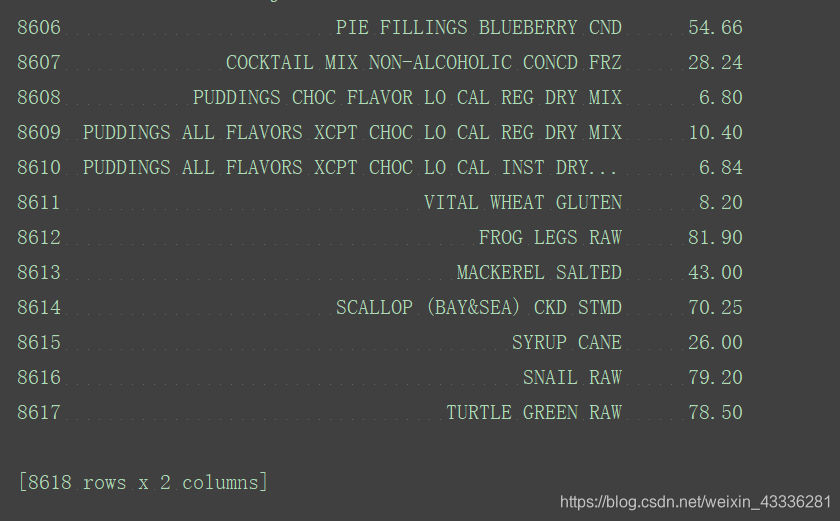
取出指定列的内容(以g为单位的列):
col_names=food_info.columns.tolist()
print(col_names)
gram_columns=[]
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df=food_info[gram_columns]
print(gram_df.head(3))
先用一个列表存储以g为单位的列名,然后打印前三行数据
找到相应的列并对列中所有的数据进行四则运算:
print(food_info["Iron_(mg)"])
div_1000=food_info["Iron_(mg)"]/1000
print(div_1000)
将某两列中的数据进行乘法运算以及创建一个新的列:
water_energy=food_info["Water_(g)"]*food_info["Energ_Kcal"]
iron_grams=food_info["Iron_(mg)"]/1000
print(food_info.shape)
food_info["Iron_(g)"]=iron_grams
print(food_info.shape)

将数据进行升序和降序排列:
food_info.sort_values("Sodium_(mg)",inplace=True)
print(food_info["Sodium_(mg)"])
food_info.sort_values("Sodium_(mg)",inplace=True,ascending=False)
print(food_info["Sodium_(mg)"])
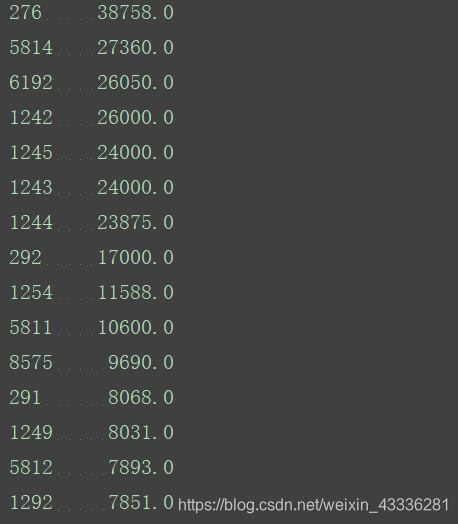

某一列中的 NaN (not a number)值:
打印前十行:
age=titanic_survival["Age"]
print(age.loc[0:10])
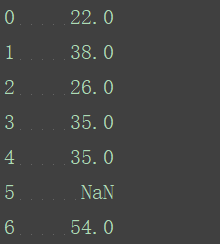
判断是否为NaN值:
age_is_null=pd.isnull(age)
print(age_is_null)
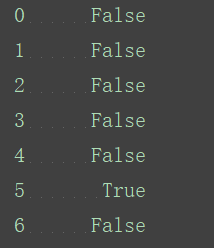
打印所有值为NaN的行号:
age_null_true=age[age_is_null]
print(age_null_true)
统计为NaN的行数:
age_null_count=len(age_null_true)
print(age_null_count)

如果直接计算平均年龄:
mean_age=sum(titanic_survival["Age"])/len(titanic_survival["Age"])
print(mean_age)

去除NaN值之后计算平均年龄:
good_ages=titanic_survival["Age"][age_is_null==False]
print(good_ages)
correct_mean_age=sum(good_ages)/len(good_ages)
print(correct_mean_age)

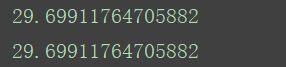
其实在pandas中有内置的去除NaN值后计算的方法:
correct_mean_age=titanic_survival["Age"].mean()
print(correct_mean_age)
两次结果一致
计算不同等级船舱的票价:
passenger_classes=[1,2,3]
fares_by_class={}
for this_class in passenger_classes:
pclass_rows=titanic_survival[titanic_survival["Pclass"]==this_class]
pclass_fares=pclass_rows["Fare"]
fare_for_class=pclass_fares.mean()
fares_by_class[this_class]=fare_for_class
print(fares_by_class)

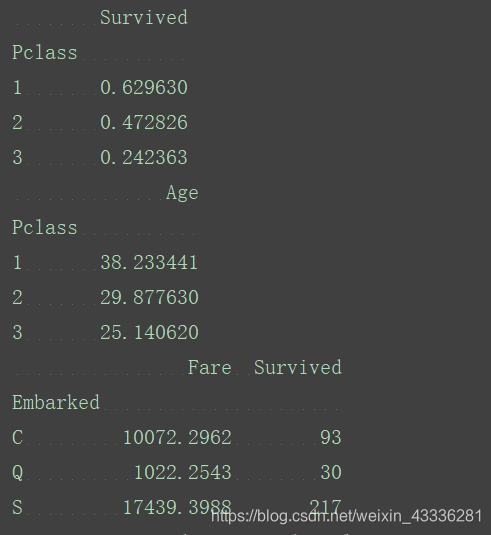
计算相关关系(数据透视表):
passenger_survial=titanic_survival.pivot_table(index="Pclass",values="Survived",aggfunc=np.mean)
print(passenger_survial)
passenger_age=titanic_survival.pivot_table(index="Pclass",values="Age")
print(passenger_age)
port_stats=titanic_survival.pivot_table(index="Embarked",values=["Fare","Survived"],aggfunc=np.sum)
print(port_stats)
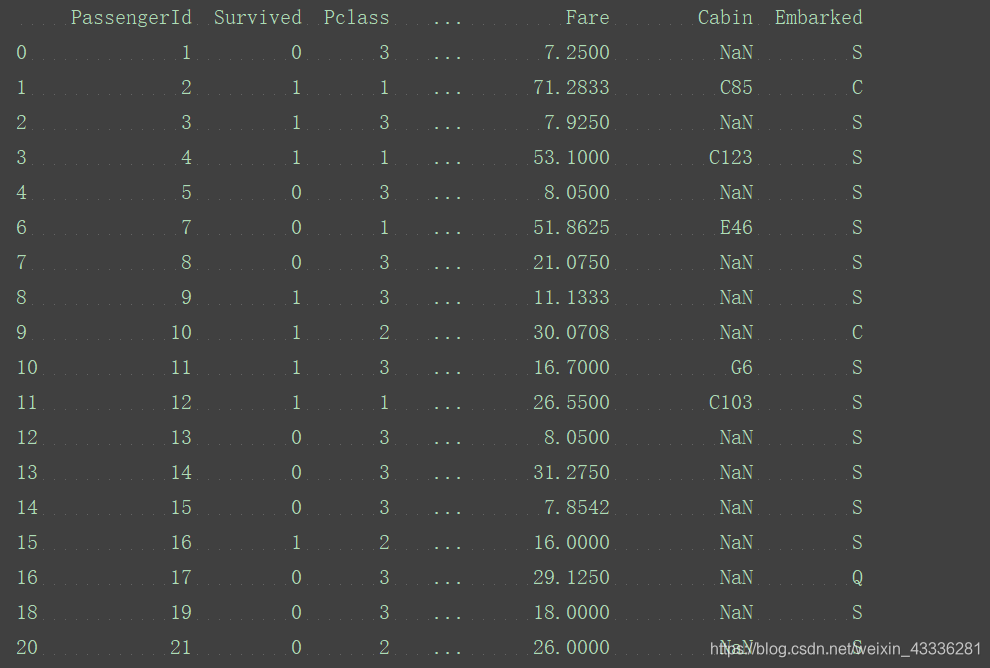
去掉缺失值:
drop_na_columns=titanic_survival.dropna(axis=1)
new_titanic_survival=titanic_survival.dropna(axis=0,subset=["Age","Sex"])
print(new_titanic_survival)
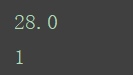
根据索引找到相应的值:
row_index_83_age=titanic_survival.loc[83,"Age"]
row_index_1000_pclass=titanic_survival.loc[766,"Pclass"]
print(row_index_83_age)
print(row_index_1000_pclass)
排序:
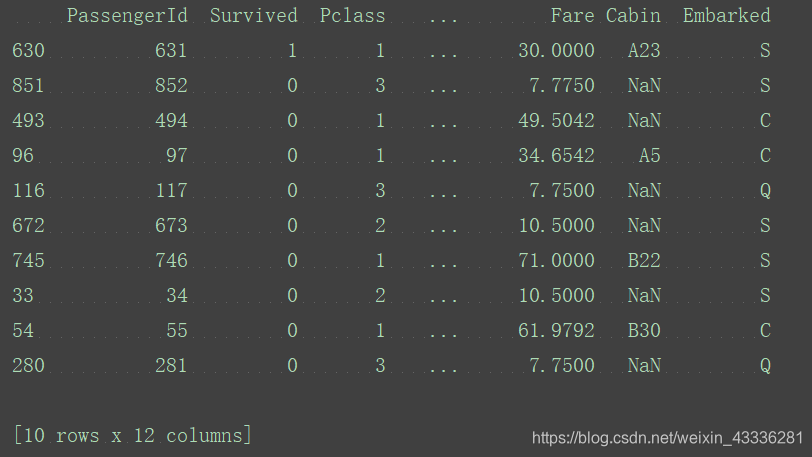
new_titanic_survival=titanic_survival.sort_values("Age",ascending=False)
print(new_titanic_survival[0:10])
titanic_reindexed=new_titanic_survival.reset_index(drop=True)
print(titanic_survival.loc[0:10])
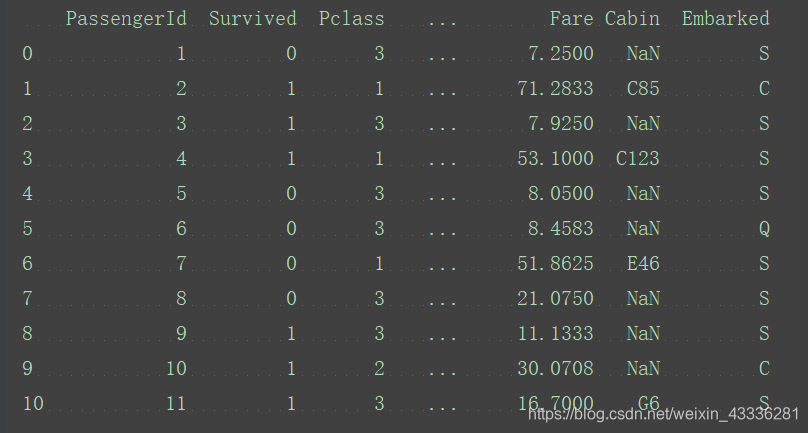
定义一个函数,找到第100个值:
def hundredth_row(columns):
hundredth_item=columns.loc[99]
return hundredth_item
hundredth_row=titanic_survival.apply(hundredth_row)
print(hundredth_row)

定义一个函数,统计缺失值:
def not_null_count(column):
column_null=pd.isnull(column)
null=column[column_null]
return len(null)
column_null_count=titanic_survival.apply(not_null_count)
print(column_null_count)
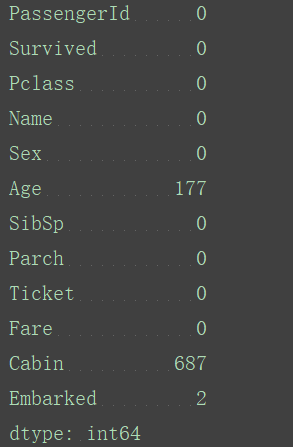
定义一个函数,对数据进行整体转换:
def which_class(row):
pclass=row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass==1:
return "First Class"
elif pclass==2:
return "Second Class"
elif pclass==3:
return "Third Class"
classes=titanic_survival.apply(which_class,axis=1)
print(classes)
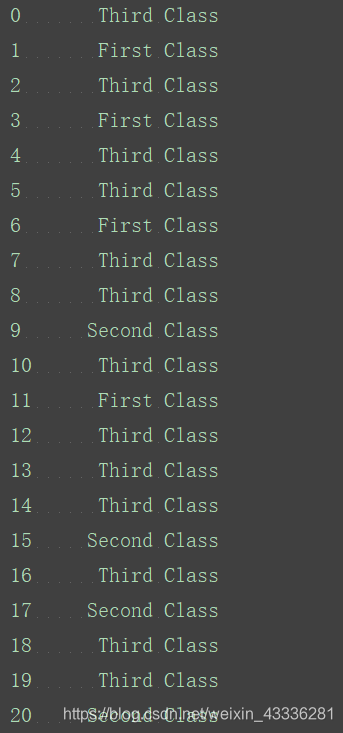

定义一个函数,判断是否成年:
def is_minor(row):
if row["Age"]<18:
return True
else:
return False
minors=titanic_survival.apply(is_minor,axis=1)
print(minors)
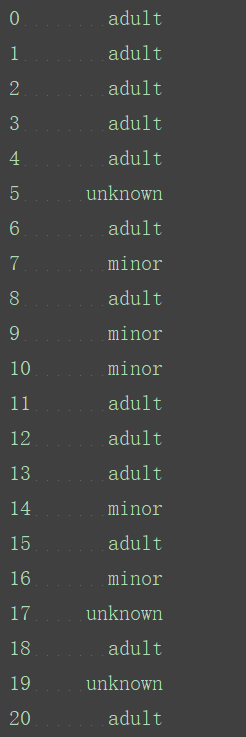
定义一个函数,根据年龄返回相应值:
def generate_age_label(row):
age=row["Age"]
if pd.isnull(age):
return "unknown"
elif age<18:
return "minor"
else:
return "adult"
age_labels=titanic_survival.apply(generate_age_label,axis=1)
print(age_labels)