概述
在Elasticsearch中,一个节点就是es对象,而一个集群(cluster)是由一个或者多个节点构成,它们具有相同的集群名字,相互协同工作,分享数据和负载的能力,如果有新的节点加入或者被删除掉,集群会自动感知到并且还能够平衡数据。
若构建高可用和扩展的系统,可扩展的方式:纵向扩展(买更好的机器),横向扩展(买更多的机器,推荐),这样如果单点挂掉其它的也可用,也就证实了集群的高可用特性。
集群中加节点
广播形式(一直ping) 特点:不可控
在本地单独的目录复制elasticsearch,再启动bin目录的bat文件
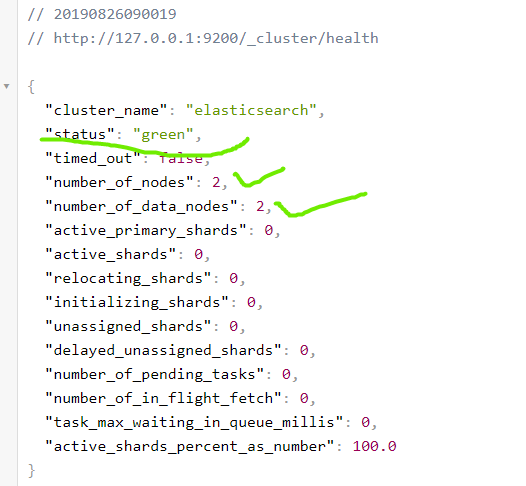
1 http://127.0.0.1:9200/_cluster/health
可以看出节点数为2并且状态为green
单播形式(理想模式,可控性比较高)
流程图:

主节点的选取:
在集群中节点发生改变,各个节点就会协商谁成为主节点。在配置文件设置主节点
discovery.zen.minimum_master_nodes: 2
如果节点总节点数为3,一般配置3/2 + 1 防止脑裂
防止脑裂
脑裂通常是在重负载中出现,就是集群中其它的节点与主节点失去通信称脑裂,这样就得设置节点总数,比如说现在节点总数为5个
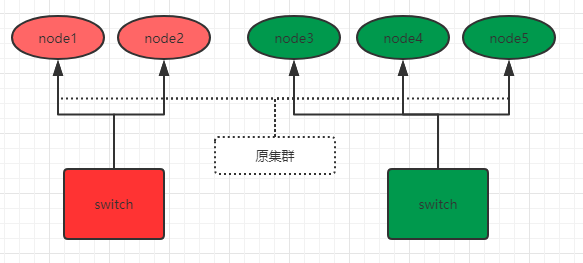
防止脑裂的方法
1 discovery.zen.minimum_master_nodes: 3 # 3 = 5/2 +1
如图所示: 集群主节点为node1,由于网络负载等问题,原来集群被分成两个,分别由node1/2和node3/4/5但是我们设置参数最小节点要超过3才能组成新的集群,所以只能node3/4/5才能组成新的集群,node1/2只能网络负载恢复之后,寻求node3/4/5才能加入该集群中,此时我们还需设置node_master参数,方便新的集群选取主节点。
错误识别
主节点被确定之后,内部的ping机制来识别其它的节点是否还存活,是否处于健康,在ping的时候我们也可以进行参数设置
1 discovery.zen.fd.ping_interval: 1 # 每个节点隔1s发送一个ping请求 2 discovery.zen.fd.ping_timeout: 30 # 最多等待30s 3 discovery_zen.fd.ping_retries: 3 # 最多尝试3次 如果没回应此节点被认为失联
本地搭建总节点数为3的单播集群
配置单播发现
节点1的配置
1 cluster.name: my_escluster # 集群名字 2 node.name: node1 # 节点1 3 network.host: 127.0.0.1 # ip 4 http.port: 9200 # 本地监听端口9200 5 transport.tcp.port: 9300 # 集群监听端口9300 6 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9304"] # 允许的ip:端口组成集群
节点2的配置
1 cluster.name: my_escluster 2 node.name: node2 3 network.host: 127.0.0.1 4 http.port: 9202 5 transport.tcp.port: 9302 6 node.master: true #可以权限成为主节点 7 node.data: true #读写磁盘 8 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9304"]
节点3的配置
1 cluster.name: my_escluster 2 node.name: node3 3 network.host: 127.0.0.1 4 http.port: 9204 5 transport.tcp.port: 9304 6 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9304"]
搭建成功
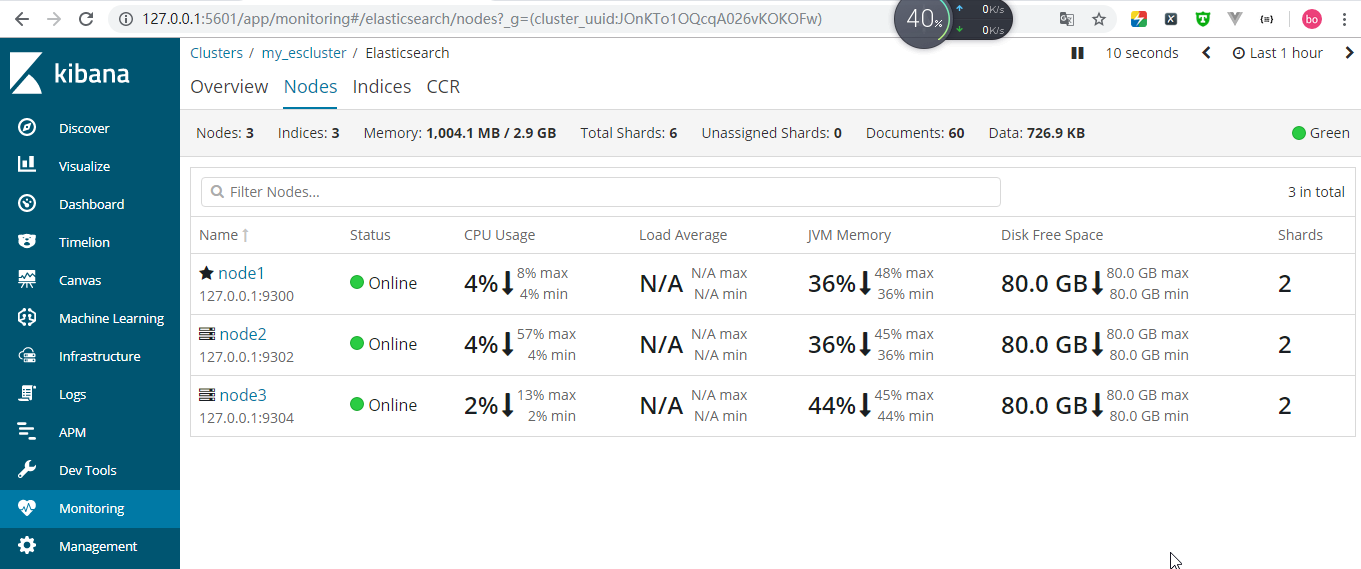
在上图中可以发现,此集群中有三个节点,并且处于green状态,再看节点信息,node1成为了主节点,因为我先启动的node1,总的分片数为6
再探集群
当打开一个单点的node1,此时没有数据和索引,name这个集群就为空集群
集群健康信息查询
1 GET cluster/health # 在kibana的Dev Tools中查询 2 http://127.0.0.1:9200/_cluster/health?pretty # 浏览器中输入
返回结果如下
1 { 2 "cluster_name" : "my_escluster", 3 "status" : "green", 4 "timed_out" : false, 5 "number_of_nodes" : 1, 6 "number_of_data_nodes" : 1, 7 "active_primary_shards" : 3, 8 "active_shards" : 3, 9 "relocating_shards" : 0, 10 "initializing_shards" : 0, 11 "unassigned_shards" : 0, 12 "delayed_unassigned_shards" : 0, 13 "number_of_pending_tasks" : 0, 14 "number_of_in_flight_fetch" : 0, 15 "task_max_waiting_in_queue_millis" : 0, 16 "active_shards_percent_as_number" : 100.0 17 }
可以看到集群名称,健康状态,超时,节点,是否权限可存储等信息
健康状态
| 颜色 | 描述 |
| green | 所有主要分片和复制分片都可用 |
| yellow | 所有主要分片可用,但不是所有复制分片都可用 |
| red | 不是所有的主要分片都可用 |
一个分片是最小级别的工作单元,一个分片只是保存索引中所有数据的一部分
分片分为主分片和复制分片 主分片数量级固定,复制分片的数量可以进行调整
复制分片是主分片的一个副本,防止数据丢失
此时添加索引
PUT blogs { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } }
分配3个分片,默认为5,一个复制分片,默认情况下(每个主分片都有一个复制分片)
查看健康状态
{ "cluster_name" : "my_escluster", "status" : "yellow", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 6, "active_shards" : 6, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 3, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 66.66666666666666 }
此时状态为yellow,主分片正常,复制分片还没有全部可用,复制分片处于unassigned状态,还没有分配节点。如果保存在同一个节点上,那么节点挂掉,数据将丢失。
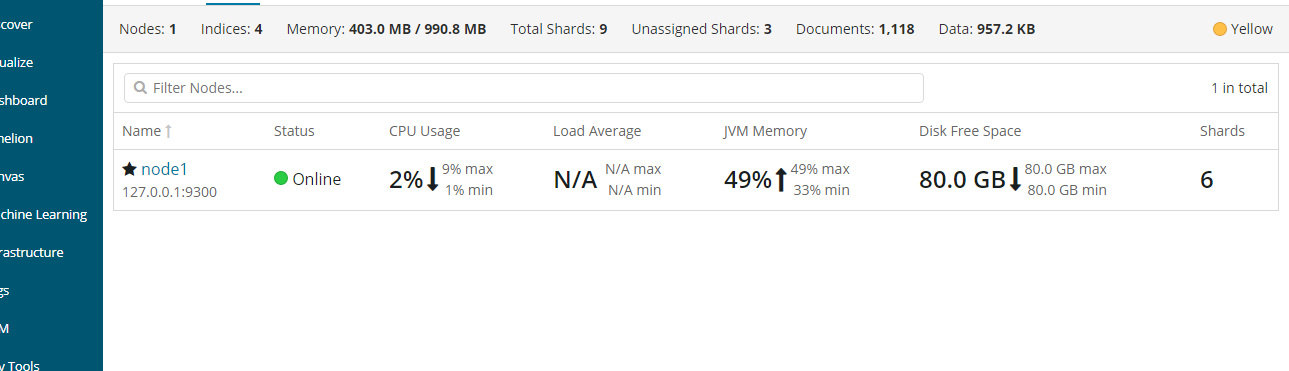
添加更多的节点 承担数据丢失的风险,此时三个复制分片已经被分配,保证数据的完整性
(存储在主分片中的数据,然后并发复制到对应的复制分片上了)
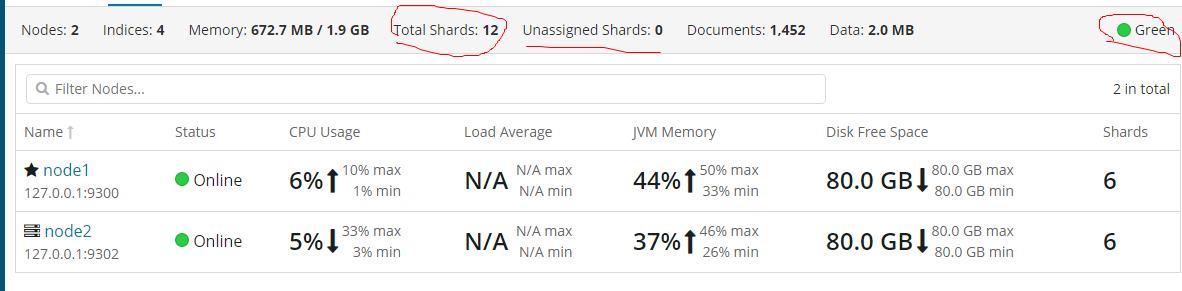
此时再查看下状态
{ "cluster_name" : "my_escluster", "status" : "green", "timed_out" : false, "number_of_nodes" : 2, "number_of_data_nodes" : 2, "active_primary_shards" : 6, "active_shards" : 12, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0 }
继续扩展

现在可以看到越来越多的节点获取到资源了 都进行了对资源的分配,通过命令查看信息
1 GET _cluster/state/master_node,nodes?pretty # 返回所有节点 2 GET _cluster/state/master_node,node?pretty # 返回当前主节点的信息 3 GET _nodes # 返回所有节点列表
主节点挂掉的情况
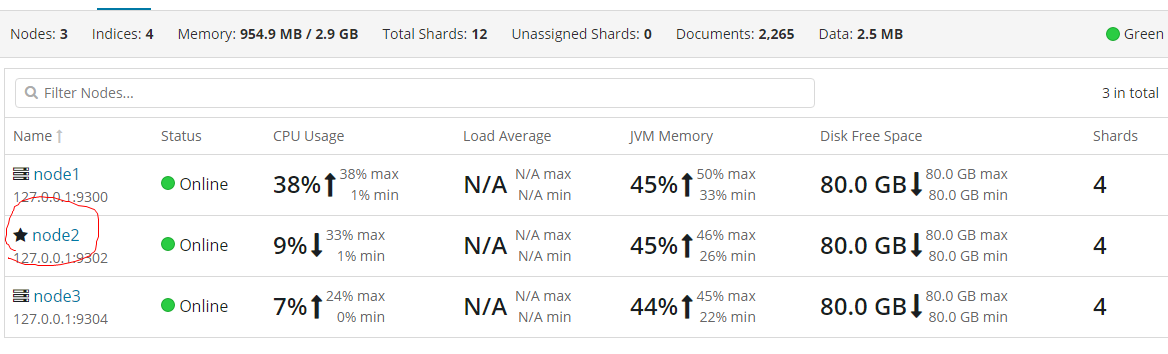
此时node2节点成为主节点
1 node.master: false # 该节点是否可以被选举为主节点,默认为true 2 node.data: true # 该节点是否有存储权限,默认为true
停用节点可以通过命令
PUT /_cluster/settings { "transient": { "cluster.routing.allocation.exclude._ip": "192.168.1.1" } }
如果被停用 该节点上的全部分片转移到其他的节点上 ,并且这个设置是暂时的,集群重启后不再有效。