装饰器(docorator)
本质是函数,起装饰其他函数作用,为原函数添加附加功能
原则:不能修改被装饰函数的源代码
不修改被装饰函数的调用方式
装饰器需要的知识:
函数即变量
高阶函数
嵌套函数
装饰器=高阶函数+嵌套函数
含参方式
import time
def times(func): #times=deco(test) func=test
def deco(*arge,**kwarge):
start_time=time.time()
func(*arge,**kwarge)
stop_time=time.time()
print("in the test run %s"%(stop_time-start_time))
return deco
@times
def test(name):
time.sleep(2)
print(name)
print(" in the test")
#test=times(test)=@time
test('zyp')
当被装饰函数有几个不同的需求,但是大部分代码相同可以如下:
user,passwd = 'aaa','123456' def outer(auth_type): def waper(func): def into(*args,**kwargs): if auth_type == "local": username = input("Username:").strip() password = input("Password:").strip() if user == username and passwd == password: print("�33[32;1mUser has passed authentication�33[0m") func(*args, **kwargs) print("--------待续。。。。 ") return func else: exit("�33[31;1mInvalid username or password�33[0m") elif auth_type == "ldap": print("待续。。。。") return into return waper def index(): print("welocome in the index ") @outer(auth_type="local") def home(): print("welocome in the home ") @outer(auth_type="ldap") def bbs(): print("welocome in the bbs ") index() print(home()) bbs()
生成器(generator)
1、边循环边计算的机制
2、只有在调用的时候才会生成相应的数据
3、__next()__() 取元素 和next() 一样用法
4、yield使生成器只有在调用的时候才会运行
5、协同程序就是可以独立运行的独立函数的调用,函数可以暂停或者挂起,并在需要的时候从程序离开的地方继续或重新开始
>>> a=(i for i in range(10)) >>> print(a) <generator object <genexpr> at 0x0061B930> >>> b=[i for i in range(10)] >>> print(b) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
6、generator执行循序和函数不一样,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句开始执行
7、for循环条用生成器是,拿不到返回值,若要返回值必须捕获stopIteration错误
迭代器
可迭代对象(Iterator):可以作用于for循环的对象
使用isinstance()可判断是否是可迭代对象
可被next()函数调用并不断返回下一个值的对象称迭代器
将可迭代对象转迭代器:Iter()
python3内置函数
python内置了一系列的常用函数,以便于我们使用,python英文官方文档详细说明:https://docs.python.org/3/library/functions.html?highlight=built#ascii

abs() 获取绝对值
>>> abs(-5)
5
all() 接受一个迭代器,若迭代器中所有元素都为真,则返回True,否则返回False (非0即为真)
a=[1,2,3,4] b=[0,1,2,3,4] c=b[1:] #切片去掉零 print(all(a)) #True print(all(b)) #False print(all(c)) #True
any() 接受一个迭代器,若迭代器中有一个元素都为真,则返回True,否则返回False
b=[0,1,2,3,4] print(any(b)) #True a=[0,0,0,1] print(any(a)) #True
ascii() 调用对象的__repr__()方法,获得该方法的返回值.
bin(), oct(), hex() 三个函数功能为:将十进制数分别转换为2/8/16进制
bool() 测试一个对象是True还是False
bytes() 将一个字符串转换成字节类型
>>> a='123avx' >>> print(bytes(a,encoding='utf-8')) b'123avx' >>> a='中国' >>> print(bytes(a,encoding='utf-8')) b'xe4xb8xadxe5x9bxbd'
bytearray() 方法返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
参数
- 如果 source 为整数,则返回一个长度为 source 的初始化数组;
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值
返回新字节数组。
a=bytearray('abcd',encoding='utf-8') a[0]=100 print(a) #bytearray(b'dbcd') b=bytearray() print(b) #bytearray(b'')
callable() 判断变量是否可以被调用,能被调用的对象就是一个callables对象,比如函数和带有__call__()的实例
def add(): print('函数可被调用') print(callable(add)) #True a=[1,2,3,4] print(callable(a)) #False
chr() 输出十进制对应的ASCII值,ord() 输出ASCII对应的十进制
>>> chr(100) 'd' >>> chr(65) 'A' >>> ord('a') 97 >>> ord('A') 65 >>> ord('0') 48
compile() 将字符串编译成python能识别或可以执行的代码,也可以将文字读成字符串再编译
参数
- source -- 字符串或者AST(Abstract Syntax Trees)对象。。
- filename -- 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode -- 指定编译代码的种类。可以指定为 exec, eval, single。
- flags -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。。 参数为可选参数。
- flags和dont_inherit是用来控制编译源码时的标志,参数为可选参数。
返回值: 返回表达式执行结果。
f = open("fib.py") data =compile(f.read(),' ','exec') exec(data) #执行了fib函数,输出斐波那契数列
delattr() 删除对象的属性
dict() 创建数据字典
dir() 查看内置函数
divmod() 分别取商和余数
>>> divmod(10,2) (5, 0) >>> divmod(10,3) (3, 1)
enumerate() 返回一个可以枚举的对象,该对象的next()方法将返回一个元组
>>> a=[1,2,3,4] >>> for index,i in enumerate(a):print(index,i) ... 0 1 1 2 2 3 3 4
eval() 将字符串str当成有效的表达式来求值并返回计算结果
1 >>> s = "1+2*3" 2 >>> type(s) 3 <class 'str'> 4 >>> eval(s) 5 7
exec() 执行字符串或complie方法编译过的字符串,没有返回值
filter() 过滤器,构造一个序列,等价于[ item for item in iterables if function(item)],在函数中设定过滤条件,逐一循环迭代器中的元素,将返回值为True时的元素留下,形成一 个filter类型数据
filter(function, iterable)
2 参数function:返回值为True或False的函数,可以为None。
3 参数iterable:序列或可迭代对象。
>>> r=filter(lambda x: x>5,range(10)) >>> for i in r: ... print(i) 6 7 8 9
float() 讲一个字符串或整数转换为浮点数
format() 格式化输出字符串
frozenset() 创建一个不可修改的集合
1 frozenset([iterable]) 2 set和frozenset最本质的区别是前者是可变的,后者是不可变的。当集合对象会被改变时(例如删除,添加元素),只能使用set, 3 一般来说使用fronzet的地方都可以使用set。 4 参数iterable:可迭代对象
globals() 返回一个描述当前全局变量的字典(变量为key,值为value)
locals() 返回一个描述当前局部变量的字典(变量为key,值为value)
hash() 哈希值
1 hash(object) 2 如果对象object为哈希表类型,返回对象object的哈希值。哈希值为整数,在字典查找中,哈希值用于快递比价字典的键。 3 两个数值如果相等,则哈希值也相等。
help() 返回对象的帮助文档
id() 返回对象的内存地址
int() 将一个字符串或数值转换为一个普通整数
1 int([x[,radix]]) 2 如果参数是字符串,那么它可能包含符号和小数点。参数radix表示转换的基数(默认是10进制)。 3 它可以是[2,36]范围内的值,或者0。如果是0,系统将根据字符串内容来解析。 4 如果提供了参数radix,但参数x并不是一个字符串,将抛出TypeError异常; 5 否则,参数x必须是数值(普通整数,长整数,浮点数)。通过舍去小数点来转换浮点数。 6 如果超出了普通整数的表示范围,一个长整数被返回。 7 如果没有提供参数,函数返回0。
isinstance() 检查对象是否是类的对象,返回True或False
a=[1,2,3,4] print(isinstance(a,str)) #False print(isinstance(a,list)) #True print(isinstance(123,int)) #True
issubclass() 检查一个类是否是另一个类的子类。返回True或False
issubclass(sub, super)
1 检查sub类是否是super类的派生类(子类)。返回True 或 False
iter()
1 iter(o[, sentinel]) 2 返回一个iterator对象。该函数对于第一个参数的解析依赖于第二个参数。 3 如果没有提供第二个参数,参数o必须是一个集合对象,支持遍历功能(__iter__()方法)或支持序列功能(__getitem__()方法), 4 参数为整数,从零开始。如果不支持这两种功能,将处罚TypeError异常。 5 如果提供了第二个参数,参数o必须是一个可调用对象。在这种情况下创建一个iterator对象,每次调用iterator的next()方法来无 6 参数的调用o,如果返回值等于参数sentinel,触发StopIteration异常,否则将返回该值。
len() 返回对象长度,参数可以是序列类型(字符串,元组或列表)或映射类型(如字典)
list()
list([iterable]) 2 list的构造函数。参数iterable是可选的,它可以是序列,支持编译的容器对象,或iterator对象。 3 该函数创建一个元素值,顺序与参数iterable一致的列表。如果参数iterable是一个列表,将创建 4 列表的一个拷贝并返回,就像语句iterables[:]
map()
map(function, iterable,...) 2 对于参数iterable中的每个元素都应用fuction函数,并将结果作为列表返回。 3 如果有多个iterable参数,那么fuction函数必须接收多个参数,这些iterable中相同索引处的元素将并行的作为function函数的参数。 4 如果一个iterable中元素的个数比其他少,那么将用None来扩展改iterable使元素个数一致。 5 如果有多个iterable且function为None,map()将返回由元组组成的列表,每个元组包含所有iterable中对应索引处值。 6 参数iterable必须是一个序列或任何可遍历对象,函数返回的往往是一个列表(list)。 7 8 li = [1,2,3] 9 data = map(lambda x :x*100,li) 10 print(type(data))
11 data = list(data) 12 print(data) 13 14 运行结果: 15 16 <class 'map'> 17 [100, 200, 300]
max() 返回给定元素里最大值
min() 返回给定元素里最小值
next() 返回一个可迭代数据结构(如列表)中的下一项
object()
获取一个新的,无特性(geatureless)对象。Object是所有类的基类。它提供的方法将在所有的类型实例中共享。
该函数时2.2.版本新增,2.3版本之后,该函数不接受任何参数。
open() 打开文件
open(filename [, mode [, bufsize]]) 打开一个文件,返回一个file对象。 如果文件无法打开,将处罚IOError异常。 应该使用open()来代替直接使用file类型的构造函数打开文件。 参数filename表示将要被打开的文件的路径字符串; 参数mode表示打开的模式,最常用的模式有:'r'表示读文本,'w'表示写文本文件,'a'表示在文件中追加。 Mode的默认值是'r'。 当操作的是二进制文件时,只要在模式值上添加'b'。这样提高了程序的可移植性。 可选参数bufsize定义了文件缓冲区的大小。0表示不缓冲;1表示行缓冲;任何其他正数表示使用该大小的缓冲区; 负数表示使用系统默认缓冲区大小,对于tty设备它往往是行缓冲,而对于其他文件往往完全缓冲。如果参数值被省却。 使用系统默认值。
pow() 幂函数
>>> pow(2,10)
1024
repr() 将任意值转换为字符串,供计时器读取的形式
1 repr(object) 2 返回一个对象的字符串表示。有时可以使用这个函数来访问操作。 3 对于许多类型来说,repr()尝试返回一个字符串,eval()方法可以使用该字符串产生对象; 4 否则用尖括号括起来的,包含类名称和其他二外信息的字符串被返回。
reversed() 反转,逆序对象
reversed(seq) 2 返回一个逆序的iterator对象。参数seq必须是一个包含__reversed__()方法的对象或支持序列操作(__len__()和__getitem__()) 3 该函数是2.4中新增的
round() 四舍五入
round(x [, n]) 对参数x的第n+1位小数进行四舍五入,返回一个小数位数为n的浮点数。 参数n的默认值是0。结果是一个浮点数。如round(0.5)结果为1.0 >>> round(4,6) 4 >>> round(5,6) 5
set() 集合
setattr() 与getattr()相对应
slice() 切片功能
sorted() 排序
>>> sorted([36,6,-12,9,-22]) 列表排序 [-22, -12, 6, 9, 36] >>> sorted([36,6,-12,9,-22],key=abs) 高阶函数,以绝对值大小排序 [6, 9, -12, -22, 36] >>> sorted(['bob', 'about', 'Zoo', 'Credit']) 字符串排序,按照ASCII的大小排序 ['Credit', 'Zoo', 'about', 'bob'] 如果需要排序的是一个元组,则需要使用参数key,也就是关键字。 >>> a = [('b',2), ('a',1), ('c',0)] >>> list(sorted(a,key=lambda x:x[1])) 按照元组第二个元素排序 [('c', 0), ('a', 1), ('b', 2)] >>> list(sorted(a,key=lambda x:x[0])) 按照元组第一个元素排序 [('a', 1), ('b', 2), ('c', 0)] >>> sorted(['bob', 'about', 'Zoo', 'Credit'],key=str.lower) 忽略大小写排序 ['about', 'bob', 'Credit', 'Zoo'] >>> sorted(['bob', 'about', 'Zoo', 'Credit'],key=str.lower,reverse=True) 反向排序 ['Zoo', 'Credit', 'bob', 'about']
>>>myslice = slice(5) # 设置截取5个元素的切片 >>> myslice slice(None, 5, None) >>> arr = range(10) >>> arr [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> arr[myslice] # 截取 5 个元素 [0, 1, 2, 3, 4] >>>
str() 字符串构造函数
sum() 求和
super() 调用父类的方法
tuple() 元组构造函数
type() 显示对象所属的类型
vars() 函数返回对象object的属性和属性值的字典对象
zip() 将对象逐一配对,多余舍弃
items() 转列表
python json.dumps() json.dump()的区别
dumps是将dict转化成str格式,loads是将str转化成dict格式。
dump和load也是类似的功能,只是与文件操作结合起来了。
dump需要一个类似于文件指针的参数(并不是真的指针,可称之为类文件对象),可以与文件操作结合,也就是说可以将dict转成str然后存入文件中;而dumps直接给的是str,也就是将字典转成str。
实际中dump用的较少
python 原始类型向 json 类型的转化对照表:
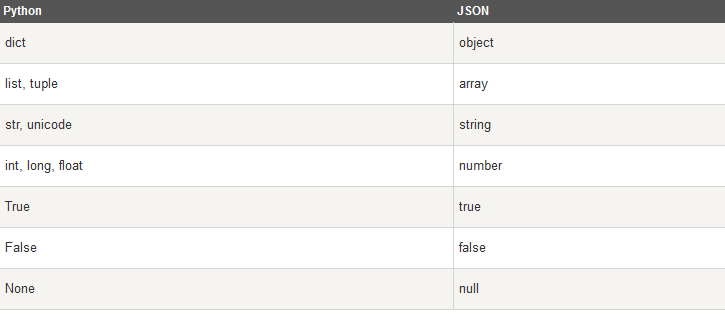
json 类型转换到 python 的类型对照表:
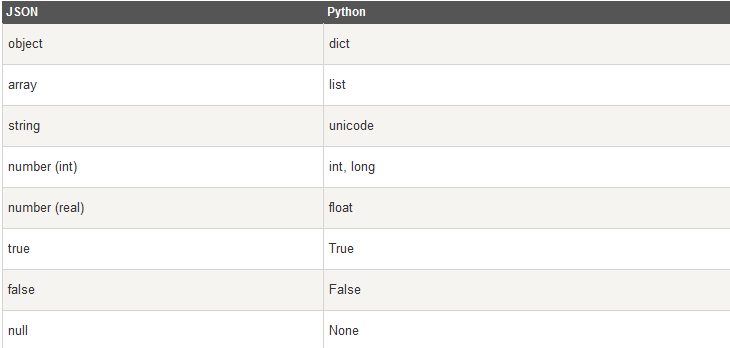
迭代对