原文:http://hi.baidu.com/tibelf/item/8b463d15edfdf10bd1d66d83
看到在进行c格式的二进制文件读取的过程中,用到了struct.unpack方法,因此开始找struct模块的一些相关解释,网上没有看到很清晰的说明,那就根据Python v2.6.5 documentation自己写一个好了。
这个struct主要是用来处理C结构数据的,读入时先转换为Python的字符串类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~
一般输入的渠道来源于文件或者网络的二进制流。
在转化过程中,主要用到了一个格式化字符串(format strings),用来规定转化的方法和格式。
下面来谈谈主要的方法:
struct.pack(fmt,v1,v2,.....)
将v1,v2等参数的值进行一层包装,包装的方法由fmt指定。被包装的参数必须严格符合fmt。最后返回一个包装后的字符串。
struct.unpack(fmt,string)
顾名思义,解包。比如pack打包,然后就可以用unpack解包了。返回一个由解包数据(string)得到的一个元组(tuple),即使仅有一个数据也会被解包成元组。其中len(string) 必须等于calcsize(fmt),这里面涉及到了一个calcsize函数,再后面谈到。
struct.calcsize(fmt)
这个就是用来计算fmt格式所描述的结构的大小。
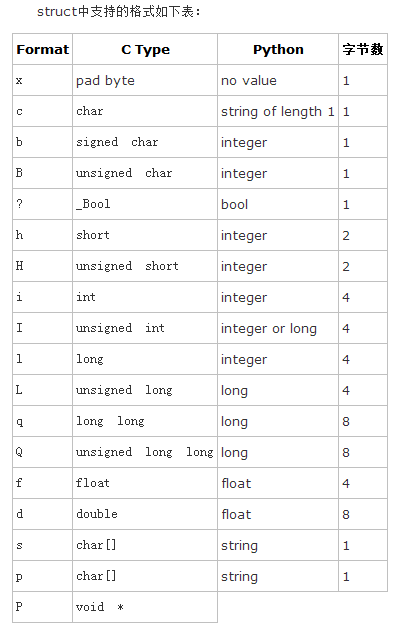
格式字符串(format string)由一个或多个格式字符(format characters)组成,对于这些格式字符的描述参照Python manual如下
Formatc TypePythonNotexpad byteno value ccharstring of length 1 bsignedcharinteger Bunsignedcharinteger ?_Boolbool(1)hshortinteger Hunsignedshortinteger iintinteger Iunsignedintinteger or long llonginteger Lunsignedlonglong qlonglonglong(2)Qunsignedlonglonglong(2)ffloatfloat ddoublefloat schar[]string pchar[]string Pvoid*long
说到这里,大家可能都有点迷糊了,那就看一段小代码
import struct
# native byteorder
buffer = struct.pack("ihb", 1, 2, 3)
print repr(buffer)
print struct.unpack("ihb", buffer)
# data from a sequence, network byteorder
data = [1, 2, 3]
buffer = struct.pack("!ihb", *data)
print repr(buffer)
print struct.unpack("!ihb", buffer)
Output:
'x01x00x00x00x02x00x03'
(1, 2, 3)
'x00x00x00x01x00x02x03'
(1, 2, 3)
首先将参数1,2,3打包,打包前1,2,3明显属于python数据类型中的integer,pack后就变成了C结构的二进制串,转成python的string类型来显示就是'x01x00x00x00x02x00x03'。由于本机是小端('little-endian',关于大端和小端的区别请参照Google),故而高位放在低地址段。i 代表C struct中的int类型,故而本机占4位,1则表示为01000000;h 代表C struct中的short类型,占2位,故表示为0200;同理b 代表C struct中的signed char类型,占1位,故而表示为03。
其他结构的转换也类似,有些特别的可以参考Manual。
在Format string 的首位,有一个可选字符来决定大端和小端,列表如下:
@nativenative=nativestandard<little-endianstandard>big-endianstandard!network (= big-endian)standard
如果没有附加,默认为@,即使用本机的字符顺序(大端or小端),对于C结构的大小和内存中的对齐方式也是与本机相一致的(native),比如有的机器integer为2位而有的机器则为四位;有的机器内存对其位四位对齐,有的则是n位对齐(n未知,我也不知道多少)。
还有一个标准的选项,被描述为:如果使用标准的,则任何类型都无内存对齐。
比如刚才的小程序的后半部分,使用的format string中首位为!,即为大端模式标准对齐方式,故而输出的为'x00x00x00x01x00x02x03',其中高位自己就被放在内存的高地址位了。
原文:http://blog.csdn.net/gracioushe/article/details/5915900
Python中按一定的格式取出某字符串中的子字符串,使用struck.unpack是非常高效的。
1. 设置fomat格式,如下:
# 取前5个字符,跳过4个字符后,再取3个字符
format = '5s 4x 3s'
2. 使用struck.unpack获取子字符串
import struct
print struct.unpack(format, 'Test astring')
#('Test', 'ing')
来个简单的例子吧,有一个字符串'He is not very happy',处理一下,把中间的not去掉,然后再输出。
import struct
theString = 'He is not very happy'
format = '2s 1x 2s 5x 4s 1x 5s'
print ' '.join(struct.unpack(format, theString))
输出结果:
He is very happy
利用unpack(),读入一个bin文件,rawstring是一个str型的字串:
rawfile = open("lcd.raw","rb")
rawstring = rawfile.read()
rawdata = struct.unpack(len(rawstring)*'B',rawstring)
在此处将rawstring转成Byte型数据得到一个rawdata的元组进行处理。