推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴趣,因此大量的用户行为数据就成为推荐系统的重要组成部分和先决条件。对于很多像百度、当当这样的网站来说,这或
许不是个问题,因为它们目前已经积累了大量的用户数据。但是对于很多做纯粹推荐系统的网站(比如Jinni和Pandora),或者很多在开始阶段就希望有个性化推荐应用的网站来说,
如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动的问题。
1、问题描述
1)冷启动问题(cold start)主要分3类:
用户冷启动 用户冷启动主要解决如何给新用户做个性化推荐的问题。当新用户到来时,我们没有他的行为数据,所以也无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
物品冷启动 物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
系统冷启动 系统冷启动主要解决如何在一个新开发的网站上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题。
2)对于这3种不同的冷启动问题,有不同的解决方案。一般来说,可以参考如下解决方案:
提供非个性化的推荐 非个性化推荐的最简单例子就是热门排行榜,我们可以给用户推荐热门排行榜,然后等到用户数据收集到一定的时候,再切换为个性化推荐。
利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
利用用户的社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品的用户。
在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
2、利用用户注册信息
用户的注册信息分3种:
人口统计学信息 包括用户的年龄、性别、职业、民族、学历和居住地。
用户兴趣的描述 有一些网站会让用户用文字描述他们的兴趣。
从其他网站导入的用户站外行为数据 比如用户通过豆瓣、新浪微博的账号登录,就可以在得到用户同意的情况下获取用户在豆瓣或者新浪微博的一些行为数据和社交网络数据。
基于注册信息的个性化推荐流程基本如下:
(1) 获取用户的注册信息;
(2) 根据用户的注册信息对用户分类;
(3) 给用户推荐他所属分类中用户喜欢的物品。
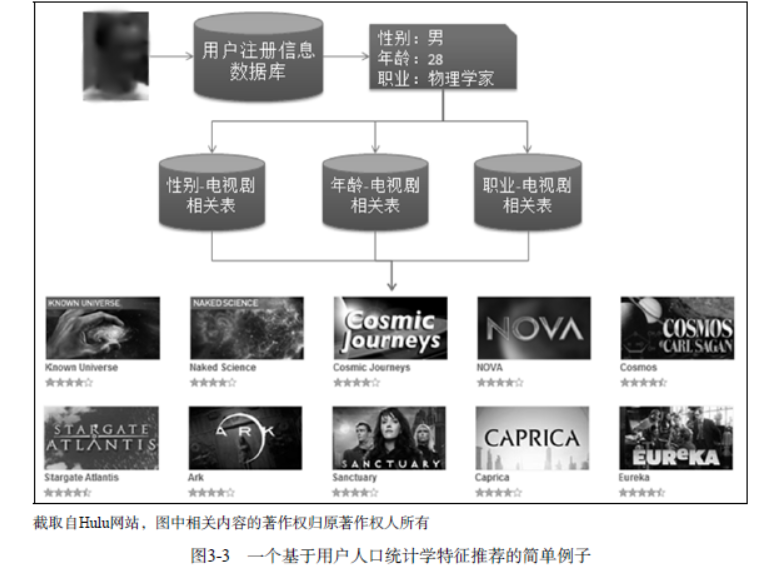

利用的用户人口统计学特征越多,越能准确地预测用户兴趣。同时,预测用户对音乐的兴趣时,国家比年龄、性别特征影响更大。
这一点是显然的,比如中国的年轻人和美国的年轻人喜欢的音乐差异是很大的。
3)选择合适的物品启动用户的兴趣
解决用户冷启动问题的另一个方法是在新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品,让用户反馈他们对这些物品的兴趣,然后根据用户反馈给提
供个性化推荐。很多推荐系统采取了这种方式来解决用户冷启动问题。
对于这些通过让用户对物品进行评分来收集用户兴趣,从而对用户进行冷启动的系统,它们需要解决的首要问题就是如何选择物品让用户进行反馈。【类似于外呼问卷调查,如何为设计问题】
一般来说,能够用来启动用户兴趣的物品需要具有以下特点:
比较热门 如果要让用户对一个物品进行反馈,前提是用户知道这个物品是什么东西。以电影为例,如果一开始让用户进行反馈的电影都很冷门,而用户不知道这些电影的情节和内容,也就无法对它们做出准确的反馈。
具有代表性和区分性 启动用户兴趣的物品不能是大众化或老少咸宜的,因为这样的物品对用户的兴趣没有区分性。还以电影为例,用一部票房很高且广受欢迎的电影做启动物品,
可以想象的到的是几乎所有用户都会喜欢这部电影,因而无法区分用户个性化的兴趣。
启动物品集合需要有多样性 在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,为了匹配多样的兴趣,我们需要提供具有很高覆盖率的启动物品集合,这些
物品能覆盖几乎所有主流的用户兴趣。
4)利用物品的内容信息
物品冷启动需要解决的问题是如何将新加入的物品推荐给对它感兴趣的用户。物品冷启动在新闻网站等时效性很强的网站中非常重要,因为那些网站中时时刻刻都有新加入的物品,而且每
个物品必须能够在第一时间展现给用户,否则经过一段时间后,物品的价值就大大降低了。a.
a. 首先需要指出的是,UserCF算法对物品冷启动问题并不非常敏感。
对于UserCF算法就需要解决第一推动力的问题,即第一个用户从哪儿发现新的物品。只要有一小部分人能够发现并喜欢新的物品,UserCF算法就能将这些物品扩散到更多的用户中。解决第一推动力
最简单的方法是将新的物品随机展示给用户,但这样显然不太个性化,因此可以考虑利用物品的内容信息,将新物品先投放给曾经喜欢过和它内容相似的其他物品的用户。
b. 对于ItemCF算法来说,物品冷启动就是一个严重的问题了。
因为ItemCF算法的原理是给用户推荐和他之前喜欢的物品相似的物品。ItemCF算法会每隔一段时间利用用户行为计算物品相似度表(一般一天计算一次),在线服务时ItemCF算法会将之前计算好的物品相关度矩阵放在内存中。因此,当新物品加入时,内存中的物品相关表中不会存在这个物品,从而ItemCF算法无法推荐新的物品。解决这一问题的办法是频繁更新物品相似度表,但基于用户行为计算物品相似度是非常耗时的事情,主要原因是用户行为日志非常庞大。而且,新物品如果不展示给用户,用户就无法对它产生行为,通过行为日志计算是计算不出包含新物品的相关矩阵的。为此,我们只能利用物品的内容信息计算物品相关表,并且频繁地更新相关表(比如半小时计算一次)。
----------
物品的内容信息多种多样,不同类型的物品有不同的内容信息。如果是电影,那么内容信息一般包括标题、导演、演员、编剧、剧情、风格、国家、年代等。如果是图书,内容信息一般包含标题、作者、出版社、正文、分类等。
一般来说,物品的内容可以通过向量空间模型①表示,该模型会将物品表示成一个关键词向量。如果物品的内容是一些诸如导演、演员等实体的话,可以直接将这些实体作为关键词。但如果内容是文本的形式,则需要引入一些理解自然语言的技术抽取关键词。对于中文,首先要对文本进行分词,将字流变成词流,然后从词流中检测出命名实体(如人名、地名、组织名等),这些实体和一些其他重要的词将组成关键词集合,最后对关键词进行排名,计算每个关键词的权重,从而生成关键词向量。
利用物品内容,得到物品的相似度之后,可以利用上一章提到的ItemCF算法的思想,给用户推荐和他历史上喜欢的物品内容相似的物品。
内容过滤算法忽视了用户行为,从而也忽视了物品的流行度以及用户行为中所包含的规律,所以它的精度比较低,但结果的新颖度却比较高。
而协同过滤算法由于数据稀疏的影响,不能从用户行为中完全统计出这一特征,所以协同过滤算法反而不如利用了先验信息的内容过滤算法。这一点也说明,如果用户的行为强烈受某一内容属性的影响,那么内容过滤的算法还是可以在精度上超过协同过滤算法的。不过这种强的内容特征不是所有物品都具有的,而且需要丰富的领域知识才能获得,所以很多时候内容过滤算法的精度比协同过滤算法差。不过,这也提醒我们,如果能够将这两种算法融合,一定能
够获得比单独使用这两种算法更好的效果。 [协同过滤 和 内容过滤 算法 结合]
向量空间模型在内容数据丰富时可以获得比较好的效果。以文本为例,如果是计算长文本的相似度,用向量空间模型利用关键词计算相似度已经可以获得很高的精确度。但是,如果文本很短,关键词很少,向量空间模型就很难计算出准确的相似度。如何建立文章、话题和关键词的关系是话题模型(topic model)研究的重点。代表性算法是LDA算法。
任何模型都有一个假设,LDA作为一种生成模型,对一篇文档产生的过程进行了建模。话题模型的基本思想是,一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题应该用什么词描述,从而最终用词写成一篇文章。因此,文章和词之间是通过话题联系的。
LDA中有3种元素,即文档、话题和词语。每一篇文档都会表现为词的集合,这称为词袋模型(bag of words)。每个词在一篇文章中属于一个话题。令D为文档集合,D[i]是第i篇文档。w[i][j]是第i篇文档中的第j个词。z[i][j]是第i篇文档中第j个词属于的话题.
LDA的计算过程包括初始化和迭代两部分。首先要对z进行初始化,而初始化的方法很简单,假设一共有K个话题,那么对第i篇文章中的第j个词,可以随机给它赋予一个话题。
在初始化之后,要通过迭代使话题的分布收敛到一个合理的分布上去。
LDA可以很好地将词组合成不同的话题。这里我们引用David M. Blei在论文中给出的一个实验结果。他利用了一个科学论文摘要的数据集,该数据集包含16 333篇新闻,共23 075个不同的
单词。通过LDA,他计算出100个话题并且在论文中给出了其中4个话题排名最高(也就是p(w|z)最大)的15个词。LDA可以较好地对词进行聚类,找到每个词的相关词。
在使用LDA计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具
有较高的相似度,反之则认为两个物品的相似度较低。计算分布的相似度可以利用KL散度:

5) 发挥专家的作用
很多推荐系统在建立时,既没有用户的行为数据,也没有充足的物品内容信息来计算准确的物品相似度。那么,为了在推荐系统建立时就让用户得到比较好的体验,很多系统都利用专家进
行标注。这方面的代表系统是个性化网络电台Pandora和电影推荐网站Jinni。
Pandora是一个给用户播放音乐的个性化电台应用。众所周知,计算音乐之间的相似度是比较困难的。首先,音乐是多媒体,如果从音频分析入手计算歌曲之间的相似度,则技术门槛很高,
而且也很难计算得令人满意。其次,仅仅利用歌曲的专辑、歌手等属性信息很难获得令人满意的歌曲相似度表,因为一名歌手、一部专辑往往只有一两首好歌。为了解决这个问题,Pandora雇
用了一批懂计算机的音乐人进行了一项称为音乐基因的项目①。他们听了几万名歌手的歌,并对这些歌的各个维度进行标注。最终,他们使用了400多个特征②(Pandora称这些特征为基因)。标
注完所有的歌曲后,每首歌都可以表示为一个400维的向量,然后通过常见的向量相似度算法可以计算出歌曲的相似度。