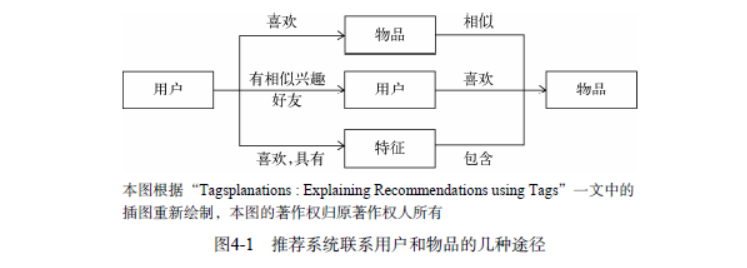
荐系统的目的是联系用户的兴趣和物品,这种联系需要依赖不同的媒介。目前流行的推荐系统基本上通过3种方式联系用户兴趣和物品。如图4-1所示,
第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,这就是前面提到的基于物品的算法。
第二种方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,这是前面提到的基于用户的算法。
除了这两种方法,第三种重要的方式是通过一些特征(feature)联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品。
这里的特征有不同的表现方式,比如可以表现为物品的属性集合(比如对于图书,属性集合包括作者、出版社、主题和关键词等),也可以表现为隐语义向量(latent factor vector),这可以通过前面提出的隐语义模型习得到。本章将讨论一种重要的特征表现方式——标签。
根据维基百科的定义,标签是一种无层次化结构的、用来描述信息的关键词,它可以用来描述物品的语义。根据给物品打标签的人的不同,标签应用一般分为两种:一种是让作者或者专
家给物品打标签;另一种是让普通用户给物品打标签,也就是UGC(User Generated Content,用户生成的内容)的标签应用。
1、UGC 标签系统的代表应用
1) delicious
2) CiteULike
3) Last.fm 标签云
4) 豆瓣
豆瓣是中国著名的评论和社交网站,同时也是中国个性化推荐领域的领军企业之一。豆瓣在个性化推荐领域进行了广泛尝试,标签系统也是其尝试的领域之一。它允许用户对图书和电影打
标签,借此获得图书和电影的内容信息和语义,并用这种信息改善推荐效果。比如,对《数据挖掘导论》在豆瓣被用户打标签的情况。最多的几个标签分别是数据挖掘、计算机、计算机科学、数据分析、IT数据分析等。这些标签准确地概括了这本书的内容信息。
标签系统的最大优势在于可以发挥群体的智能,获得对物品内容信息比较准确的关键词描述,而准确的内容信息是提升个性化推荐系统性能的重要资源。
2、标签系统中的推荐问题:
1)为什么要进行标注:
有些用户标注是给内容上传者使用的(便于上传者组织自己的信息),而有些用户标注是给广大用户使用的(便于帮助其他用户找到信息)。另一个维度是功能维度,有些标注用于更好地
组织内容,方便用户将来的查找,而另一些标注用于传达某种信息,比如照片的拍摄时间和地点等。
2)用户如何打标签:
在互联网中,尽管每个用户的行为看起来是随机的,但其实这些表面随机的行为背后蕴含着很多规律。
前面几章都提到,用户行为数据集中用户活跃度和物品流行度的分布都遵循长尾分布(PowerLaw分布)。
因此,我们首先看一下标签流行度的分布。我们定义的一个标签被一个用户使用在一个物品上,它的流行度就加一。
标签的流行度分布也呈现非常典型的长尾分布,它的双对数曲线几乎是一条直线。
3)用户打什么样的标签:
Scott A. Golder 总结了Delicious上的标签,将它们分为如下几类。
表明物品是什么
表明物品的种类
表明谁拥有物品
表达用户的观点
用户相关的标签
用户的任务
3、基于标签的推荐系统
用户用标签来描述对物品的看法,因此标签是联系用户和物品的纽带,也是反应用户兴趣的重要数据源,如何利用用户的标签数据提高个性化推荐结果的质量是推荐系统研究的重要课题。
一个用户标签行为的数据集一般由一个三元组的集合表示,其中记录(u, i, b) 表示用户u给物品i打上了标签b。当然,用户的真实标签行为数据远远比三元组表示的要复杂,比如用户打标签
的时间、用户的属性数据、物品的属性数据等。但是本章为了集中讨论标签数据,只考虑上面定义的三元组形式的数据,即用户的每一次打标签行为都用一个三元组(用户、物品、标签)表示。
一个最简单的算法:
拿到了用户标签行为数据,相信大家都可以想到一个最简单的个性化推荐算法。这个算法的描述如下所示:
统计每个用户最常用的标签。
对于每个标签,统计被打过这个标签次数最多的物品。
对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
算法的改进
前面这个公式倾向于给热门标签对应的热门物品很大的权重,因此会造成推荐热门的物品给用户,从而降低推荐结果的新颖性。另外,这个公式利用用户的标签向量对用户兴趣建模,其中
每个标签都是用户使用过的标签,而标签的权重是用户使用该标签的次数。这种建模方法的缺点是给热门标签过大的权重,从而不能反应用户个性化的兴趣。这里我们可以借鉴TF-IDF的思想,
对这一公式进行改进。
n 记录了标签b被多少个不同的用户使用过。这个算法记为TagBasedTFIDF。
n 记录了物品i被多少个不同的用户打过标签。这个算法记为TagBasedTFIDF++。
这一结果表明,适当惩罚热门标签和热门物品,在增进推荐结果个性化的同时并不会降低推荐结果的离线精度。
数据的稀疏性:
为了提高推荐的准确率,我们可能要对标签集合做扩展,比如若用户曾经用过“推荐系统”这个标签,我们可以将这个标签的相似标签也加入到用户标签集合中,比如“个性化”、“协同过滤”等标签。
进行标签扩展有很多方法,其中常用的有话题模型(topic model),不过这里遵循简单的原则介绍一种基于邻域的方法。
标签扩展的本质是对每个标签找到和它相似的标签,也就是计算标签之间的相似度。最简单的相似度可以是同义词。如果有一个同义词词典,就可以根据这个词典进行标签扩展。如果没有这个词典,我们可以从数据中统计出标签的相似度。进行标签扩展确实能够提高基于标签的物品推荐的准确率和召回率,但可能会稍微降低推荐结果的覆盖率和新颖度。
标签清理:
不是所有标签都能反应用户的兴趣。
标签清理的另一个重要意义在于将标签作为推荐解释。如果我们要把标签呈现给用户,将其作为给用户推荐某一个物品的解释,对标签的质量要求就很高。首先,这些标签不能包含没有意
义的停止词或者表示情绪的词,其次这些推荐解释里不能包含很多意义相同的词语。
一般来说有如下标签清理方法:
去除词频很高的停止词;
去除因词根不同造成的同义词,比如 recommender system和recommendation system;
去除因分隔符造成的同义词,比如 collaborative_filtering和collaborative-filtering。
4、基于图的推荐算法
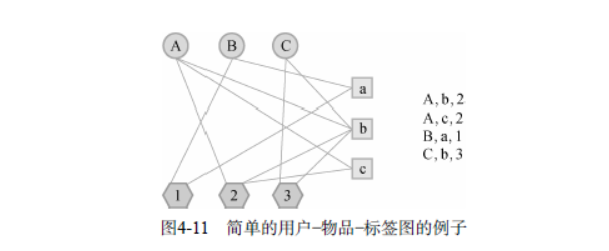
我们需要将用户打标签的行为表示到一张图上。我们知道,图是由顶点、边和边上的权重组成的。而在用户标签数据集上,有3种不同的元素,即用户、物品和标签。因此,我们需要定义3种不同的顶点,即用户顶点、物品顶点和标签顶点。然后,如果我们得到一个表示用户u给物品i打了标签b的用户标签行为(u,i,b),那么最自然的想法就是在图中增加3条边,首先需要在用户u对应的顶点v(u)和物品i对应的顶点v(i)之间增加一条边(如果这两个顶点已经有边相连,那么就应该将边的权重加1),同理,在v(u)和v(b)之间需要增加一条边,v(i)和v(b)之间也需要边相连接
图4-11是一个简单的用户—物品—标签图的例子。该图包含3个用户(A、B、C)、3个物品(a、b、c)和3个标签(1、2、3)。
在定义出用户—物品—标签图后,我们可以用第2章提到的PersonalRank算法计算所有物品节点相对于当前用户节点在图上的相关性,然后按照相关性从大到小的排序,给用户推荐排名最高的N个物品。
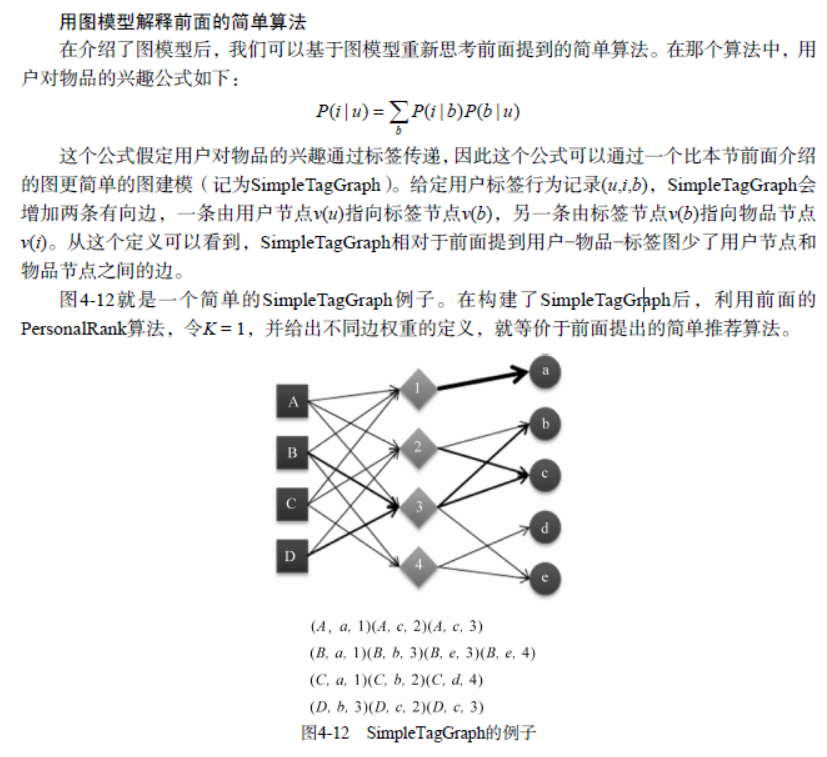
基于标签的推荐解释
基于标签的推荐其最大好处是可以利用标签做推荐解释,这方面的代表性应用是豆瓣的个性化推荐系统.
豆瓣通过标签云,展示了用户的所有兴趣,然后让用户自己根据他今天的兴趣选择相关的标签,得到推荐结果,从而极大地提高了推荐结果的多样性,使得推荐结果更容易满足用户多样的兴趣。
同时,标签云也提供了推荐解释功能。用户通过这个界面可以知道豆瓣给自己推荐的每一本书都是基于它认为自己对某个标签感兴趣。而对于每个标签,用户总能通过回忆自己之前的行为知道自己是否真的对这个标签感兴趣。
设计精妙之处:
我们知道,要让用户直观上感觉推荐结果有道理是很困难的,而豆瓣将推荐结果的可解释性拆分成了两部分,首先让用户觉得标签云是有道理的,然后让用户觉得从某个标签推荐出某本书也是有道理的。因为生成让用户觉得有道理的标签云比生成让用户觉得有道理的推荐图书更加简单,标签和书的关系就更容易让用户觉得有道理,从而让用户最终觉得推荐出来的书也是很有道理的。
作者调查了用户对不同类型标签的看法:
RelSort 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签,给出了用户对标签的兴趣和标签与物品的相关度,但标签按照和物品的相关度排序。
PrefSort 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签,给出了用户对标签的兴趣和标签与物品的相关度,但标签按照用户的兴趣程度排序。
RelOnly 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签,给出了标签与物品的相关度,且标签按照和物品的相关度排序。
PrefOnly 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签,给出了用户对标签的兴趣程度,且标签按照用户的兴趣程度排序。
总结问卷调查的结果,作者得出了以下结论:
用户对标签的兴趣对帮助用户理解为什么给他推荐某个物品更有帮助;
用户对标签的兴趣和物品标签相关度对于帮助用户判定自己是否喜欢被推荐物品具有同样的作用;
物品标签相关度对于帮助用户判定被推荐物品是否符合他当前的兴趣更有帮助;
客观事实类标签相比主观感受类标签对用户更有作用。
最后,作者询问了用户对4种不同推荐解释界面的总体满意度,结果显示PrefOnly > RelSort >PrefSort > RelOnly。
4、给用户推荐标签
为什么要给用户推荐标签
在讨论如何给用户推荐标签之前,首先需要了解为什么要给用户推荐标签。一般认为,给用户推荐标签有以下好处。
方便用户输入标签 让用户从键盘输入标签无疑会增加用户打标签的难度,这样很多用户不愿意给物品打标签,因此我们需要一个辅助工具来减小用户打标签的难度,从而提高用户打标签的参与度。
提高标签质量 同一个语义不同的用户可能用不同的词语来表示。这些同义词会使标签的词表变得很庞大,而且会使计算相似度不太准确。而使用推荐标签时,我们可以对词表进行选择,首先保证词表不出现太多的同义词,同时保证出现的词都是一些比较热门的、有代表性的词。
如何给用户推荐标签
第0种方法就是给用户u推荐整个系统里最热门的标签(这里将这个算法称为PopularTags)
第1种方法就是给用户u推荐物品i上最热门的标签(这里将这个算法称为ItemPopularTags)
第2种方法是给用户u推荐他自己经常使用的标签(这里将这个算法称为UserPopularTags)
第3种算法是前面两种的融合(这里记为HybridPopularTags),该方法通过一个系数将上面的推荐结果线性加权,然后生成最终的推荐结果
实验结论:
PopularTags、UserPopularTags、ItemPopularTags 3种算法在N = 10 时的准确率和召回率。
如表中结果所示,ItemPopularTags具有最好的准确率和召回率,这一点和直观想法是符合的。因为用户的兴趣是广泛的,假设用户对编程和武侠小说有兴趣,那么用户在给一本武侠小说打标
签时,肯定不会参考自己对编程书打的标签,而会更多地参考关于武侠小说的常用标签。因此ItemPopularTags肯定比UserPopularTags的精度要高。
下面来看一下HybridPopularTags算法,表4-12给出了HybridPopularTags算法在不同线性融合系数下的准确率和召回率。
在α=0.8的时候,HybridPopularTags取得了最好的准确度(准确率=25.15%,召回率=68.30%)。而且这个精度超过了单独的ItemPopularTags和UserPopularTags算法的精度。考
虑到近70%的精度已经很高了,因此很多应用在给用户推荐标签时会直接给出用户最常用的标签,以及物品最经常被打的标签。
一类是我的标签,即我之前常用的标签,可以看到这一类中包含诸如历史、传记等和MongoDB毫无关系的标签。
另一类是常用标签,即别的用户给MongoDB打的最多的标签,可以看到这里面所有的标签都是和MongoDB相关的。
存在缺陷:
不过,前面提到的基于统计用户常用标签和物品常用标签的算法有一个缺点,就是对新用户或者不热门的物品很难有推荐结果。解决这一问题有两个思路。
1)第一个思路是从物品的内容数据中抽取关键词作为标签。这方面的研究很多,特别是在上下文广告领域①。本书3.4节也介绍了生成关键词向量的一些方法。
2)第二个思路是针对有结果,但结果不太多的情况。比如《MongoDB权威指南》一书只有一个用户曾经给它打过一个标签nosql,这个时刻可以做一些关键词扩展,加入一些和nosql相关的
标签,比如数据库、编程等。实现标签扩展的关键就是计算标签之间的相似度。

标签在推荐系统中的应用主要集中在两个问题上,一个是如何利用用户打标签的行为给用户推荐物品,另一个是如何给用户推荐标签。
借助标签进行问题转化:将用户和物品之间的关系转化为用户对标签的兴趣(tag preference)以及标签和物品的相关度(tag relevance)两种因素。