1.redis是什么?
redis(remote dictionary server):是一个以key-value形式存储于内存中的数据库. 提供了 String / List / Set / Sort Set /Hash 五种数据结构。
服务器在断电之后,仍然可以恢复到断电之前的状态。
简言之:Redis嘛,就是一种运行速度很快,并发很强的跑在内存上的NoSql数据库,支持键到五种数据类型的映射。
资料: 官网 : http://redis.io 中文网: http://www.redis.cn/ 相关文档: http://redisdoc.com/
知乎:https://zhuanlan.zhihu.com/p/81195864
2.redis特点?
线程模型:单线程-多路复用io模型
性能高:支持读 11万/秒 , 写 8万/秒
存储: 内存 ; RDB文件(二进制安全的真实数据) ; AOF文件(客户端的命令集合)
事务: 支持事务(每个客户端串行执行命令,其他客户端处于阻塞状态)
发布/订阅模式:
3.redis数据类型
String:动态字符串(每个key都是一个String)
编码方式:int / raw() /embstr
应用场景:普通的string场景
List:列表结构,有序可重复的结构。它拥有队列的特性。
编码方式:ziplist / linkedlist (如果数据量较小,且是数字或者字符串,则内部结构为 ziplist)
应用场景:普通的集合数据
Set:集合结构,不重复的集合结构。
编码方式:intset(整数集合) / hashtable
应用场景:普通的非重复集合数据;支持取交集、取并集等操作
Sort Set:有序集合结构,和Set比较起来,它是有序的。
编码方式:ziplist / skiplist
应用场景:有序不重复的集合数据
Hash:哈希结构,存储多个key:value的结构,此种结构可以存储对象 ; 如 HMSET user(key) username value1 password value2
编码方式:ziplist / hashtable
应用场景: 从关系型数据库取出一条数据,就可以让入到此种结构中
4.内存优化
redis提供内存回收策略,根据使用的情况可以选择适当的回收策略
redis提供内存共享策略,服务器启动时,会自动创建0-9999的数字对象,其他地方使用,可以直接引用。
本质:对内存的操作,其实是在每一个redis对象结构内都有一个count的属性,该属性记录了这个对象被引用的次数,如果为0,那么在内存回收时将回收该空间。
save参数调整:当满足条件时,触发SAVE命令,持久化到RDB文件
appendonly参数: 默认no ,若yes,则开启AOF文件持久化; BGREWRITEAOF 命令 持久化。其中appendsync参数调整具体的持久化策略,默认为每秒
内存回收策略:
5. 讲一讲为什么Redis这么快?
首先,采用了多路复用io阻塞机制
然后,数据结构简单,操作节省时间
最后,运行在内存中,自然速度快
6. Redis 为什么是单线程
Redis官方很敷衍就随便给了一点解释。不过基本要点也都说了,因为Redis的瓶颈不是cpu的运行速度,而往往是网络带宽和机器的内存大小。
再说了,单线程切换开销小,容易实现既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
如果万一CPU成为你的Redis瓶颈了,或者,你就是不想让服务器其他核闲置,那怎么办?
那也很简单,你多起几个Redis进程就好了。Redis是keyvalue数据库,又不是关系数据库,数据之间没有约束。
只要客户端分清哪些key放在哪个Redis进程上就可以了。redis-cluster可以帮你做的更好。
7. 单线程可以处理高并发请求吗?
当然可以了,Redis都实现了。有一点概念需要澄清,并发并不是并行。
相关概念:
并发性I/O流,意味着能够让一个计算单元来处理来自多个客户端的流请求。
并行性,意味着服务器能够同时执行几个事情,具有多个计算单元。
8. 简述一下Redis值的五种类型
String 整数,浮点数或者字符串
Set 集合
Zset 有序集合
Hash 散列表
List 列表
9. 有序集合的实现方式是哪种数据结构?
跳跃表。
请列举几个用得到Redis的常用使用场景?
缓存,毫无疑问这是Redis当今最为人熟知的使用场景。再提升服务器性能方面非常有效; 排行榜,在使用传统的关系型数据库(mysql oracle 等)来做这个事儿,非常的麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单的搞定; 计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力; 好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能; 简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦; Session共享,以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。 一些频繁被访问的数据,经常被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis 是放在内存中的可以很高效的访问
Redis的数据淘汰机制
volatile-lru 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
volatile-ttl 从已设置过期时间的数据集中挑选将要过期的数据淘汰
volatile-random从已设置过期时间的数据集中任意选择数据淘汰
allkeys-lru从所有数据集中挑选最近最少使用的数据淘汰
allkeys-random从所有数据集中任意选择数据进行淘汰
noeviction禁止驱逐数据
Redis怎样防止异常数据不丢失?
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其它服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量很大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(Append Only File)的末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项:
选项同步频率always每个写命令都同步everysec每秒同步一次no让操作系统来决定何时同步
always 选项会严重减低服务器的性能;
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量
随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
讲一讲缓存穿透,缓存雪崩以及缓存击穿吧
缓存穿透:就是客户持续向服务器发起对不存在服务器中数据的请求。客户先在Redis中查询,查询不到后去数据库中查询。
缓存击穿:就是一个很热门的数据,突然失效,大量请求到服务器数据库中
缓存雪崩:就是大量数据同一时间失效。
打个比方,你是个很有钱的人,开满了百度云,腾讯视频各种杂七杂八的会员,但是你就是没有netflix的会员,然后你把这些账号和密码发布到一个你自己做的网站上,然后你有一个朋友每过十秒钟就查询你的网站,发现你的网站没有Netflix的会员后打电话向你要。你就相当于是个数据库,网站就是Redis。这就是缓存穿透。
大家都喜欢看腾讯视频上的《水果传》,但是你的会员突然到期了,大家在你的网站上看不到腾讯视频的账号,纷纷打电话向你询问,这就是缓存击穿
你的各种会员突然同一时间都失效了,那这就是缓存雪崩了。
解决方法:
缓存穿透:
1.接口层增加校验,对传参进行个校验,比如说我们的id是从1开始的,那么id<=0的直接拦截;
2.缓存中取不到的数据,在数据库中也没有取到,这时可以将key-value对写为key-null,这样可以防止攻击用户反复用同一个id暴力攻击
缓存击穿:
最好的办法就是设置热点数据永不过期,拿到刚才的比方里,那就是你买腾讯一个永久会员
缓存雪崩:
1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2.如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
嗦一下Redis中的Master-Slave模式
连接过程
- 主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
- 从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
- 主服务器每执行一次写命令,就向从服务器发送相同的写命令。
主从链
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。
为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
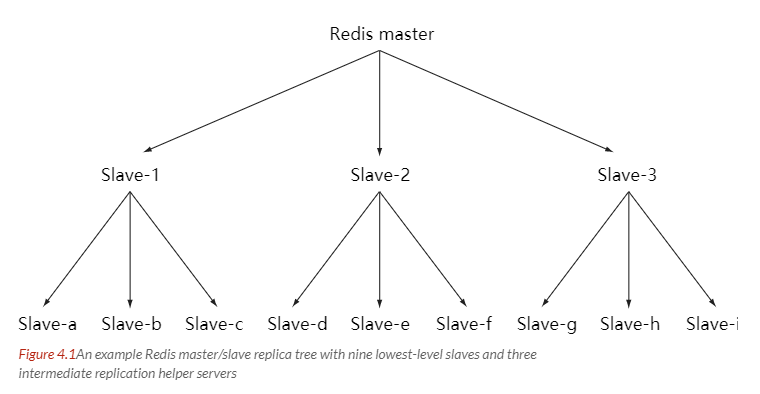
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
分片
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,... ,有不同的方式来选择一个指定的键存储在哪个实例中。
最简单的方式是范围分片,例如用户 id 从 0~1000 的存储到实例 R0 中,用户 id 从 1001~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
根据执行分片的位置,可以分为三种分片方式:
客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
服务器分片:Redis Cluster
感谢整理: https://zhuanlan.zhihu.com/p/81195864
java 使用Redis 实例: https://www.redis.net.cn/tutorial/3525.html