一,引言
今天分享一个新的Azure 服务-----Azure Data Factory(Azure 数据工厂),怎么理解,参考根据官方解释-----数据工厂解释:大数据需要可以启用协调和操作过程以将这些巨大的原始数据存储优化为可操作的业务见解的服务。 Azure 数据工厂是为这些复杂的混合提取-转换-加载 (ETL)、提取-加载-转换 (ELT) 和数据集成项目而构建的托管云服务。
说简单点,Azure Data Factory 可以创建和计划数据驱动型工作,也就是 Pineline,从不同的数据源(如:Azuer Storage,File, SQL DataBase,Azure Data Lake等)中提取数据,进行加工处理,进行复杂计算后,将这些有价值的数据可以归档,存储到不同的目标源(如:Azuer Storage,File, SQL DataBase,Azure Data Lake等)
--------------------我是分割线--------------------
1,Azure Data Factory(一)入门简介
2,Azure Data Factory(二)复制数据
3,Azure Data Factory(三)集成 Azure Devops 实现CI/CD
4,Azure Data Factory(四)集成 Logic App 的邮件通知提醒
5,Azure Data Factory(五)Blob Storage 密钥管理问题
二,正文
Azure Data Factory 中的Pipeline 通常执行以下三个步骤:
1,连接,收集:连接,收集是指在构建 pipeline 时需要有数据源,然后再将数据源中提取出来的数据进行加工处理,通过使用 Data Factory 中的 pipeline ,添加 “Activites” 操作,将数据从本地和云的源数据存储移到云的集中数据存储进行进一步的分析。
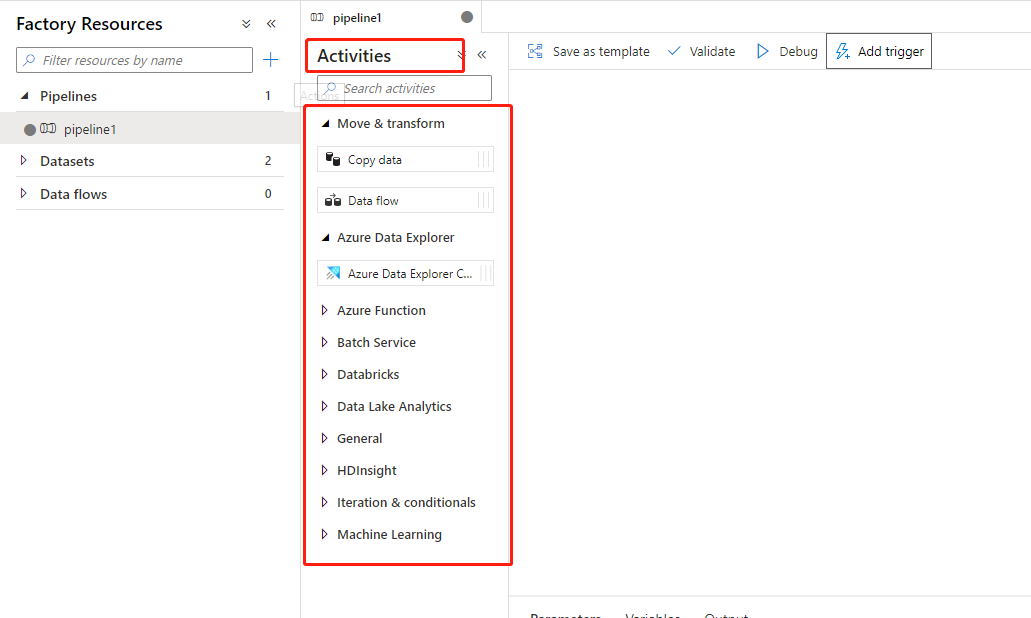
2,转换和扩充:将DataSet 中收集到的数据源的数据,可以使用一些其他的服务,例如 DataB ,Machine Learning进行数据处理,转化,可以将这些数据转化成有价值的,可信的生产环境的数据
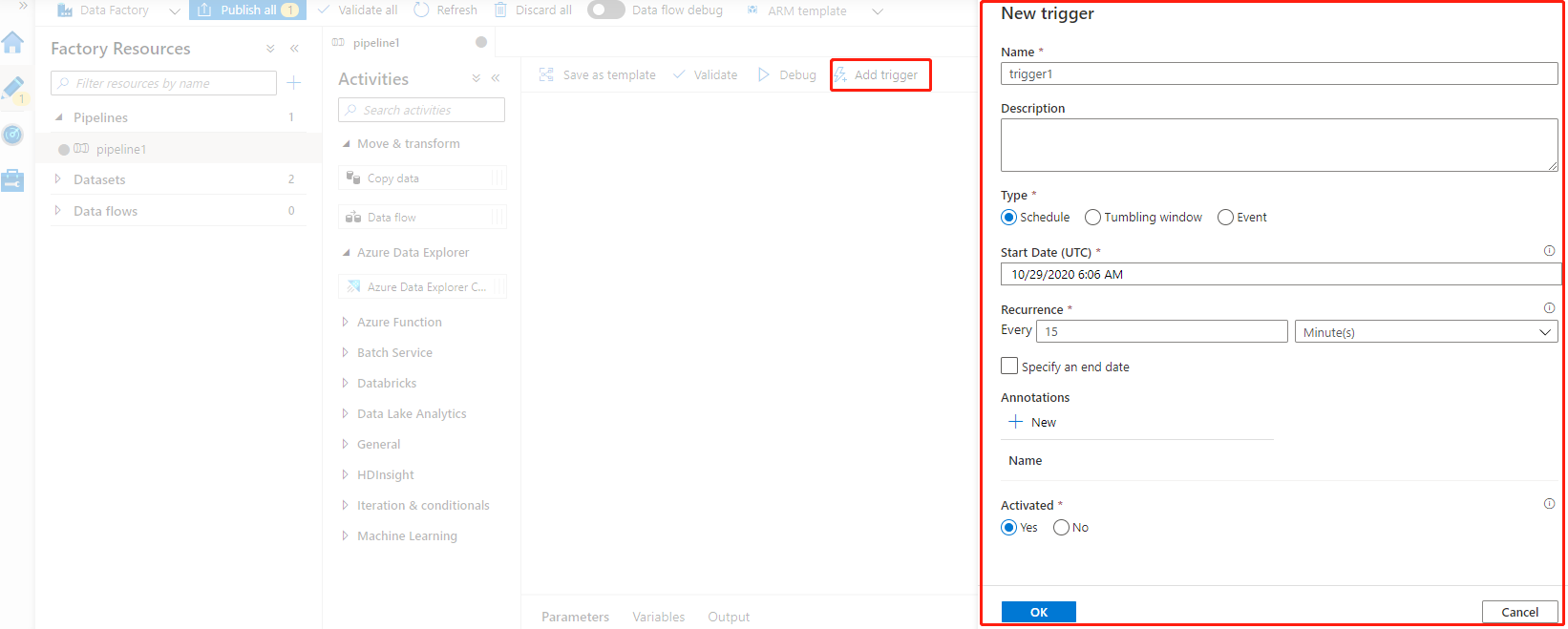
3,发布:这里的发布,并不是指代码的发布,而是指手动触发将转化、处理好的数据传送到目标源,同时可以设置Trgger ,定时执行发布计划。
Azure Data Factory 中一些关键组件:
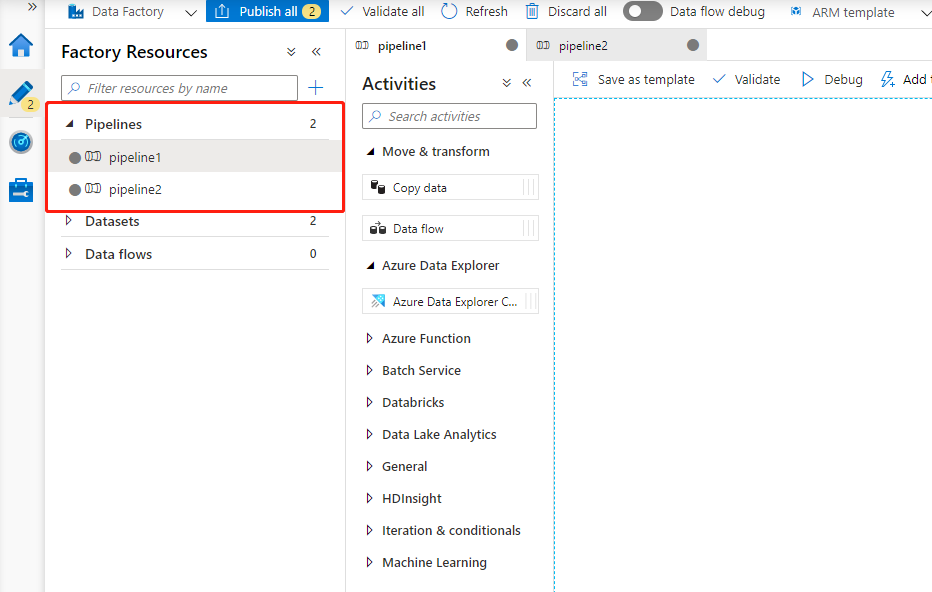
1,pipeline:这里的 pipeline 要和Azure DevOps 中的 pipeline 概念上有些类似,它是指我们的Azure Data Factory 可以包含一个或者多个 pipeline 。pipeline是有多个Activites组成,来执行一项任务的。如下图所示,这里显示多个pipeline。
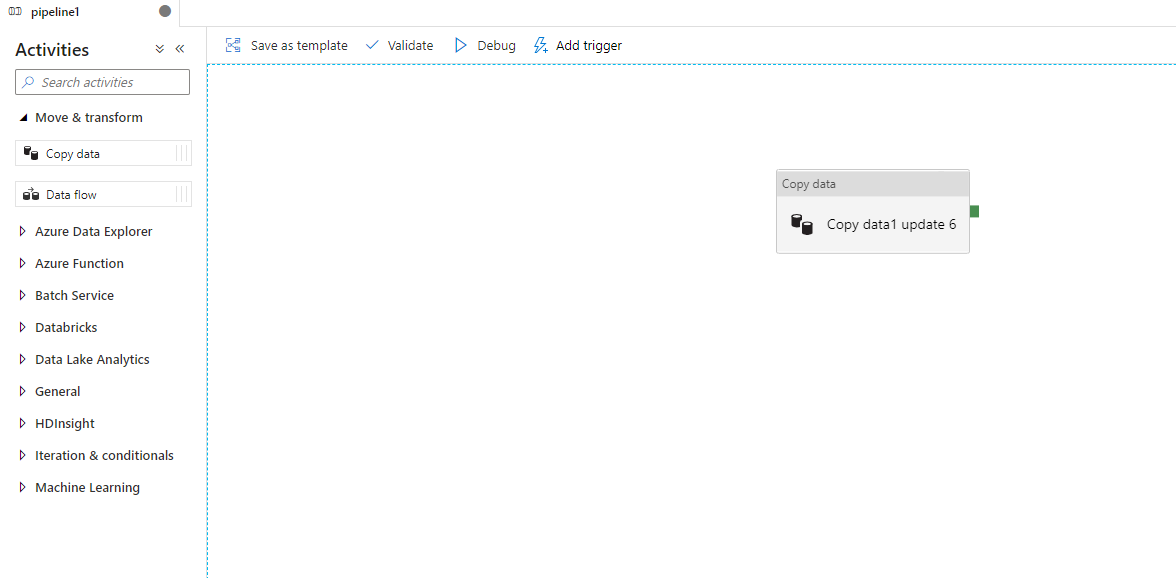
2,Activities:一个pipeline 可以有多个 Activities,这些是对数据执行的一些动作,例如 复制数据,如下图,当前 Pipeline 中包含了一个 Copy data
3,datasets(数据集):简单理解,就是包含了 数据源、目标源。数据集可识别不同数据存储(如表、文件、文件夹和文档)中的数据,使用零个或多个 "datset" 作为输入,一个或多个 "dataset" 作为输出。
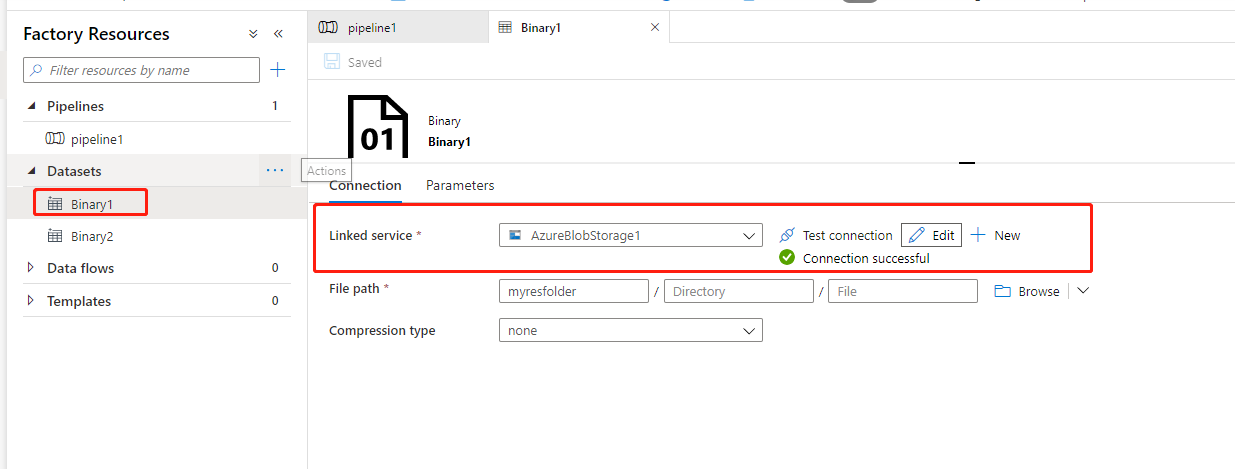
4,linked services:链接服务就好比链接字符串,密钥等信息,用于定义Azure Data Factory 链接到外部资源时所需哟啊的连接信息,如下图链接服务指链接到Azure Storage Account 所需要的连接字符串。
同时,点击 “Test connection” 进行测试,是否可以正常连接。
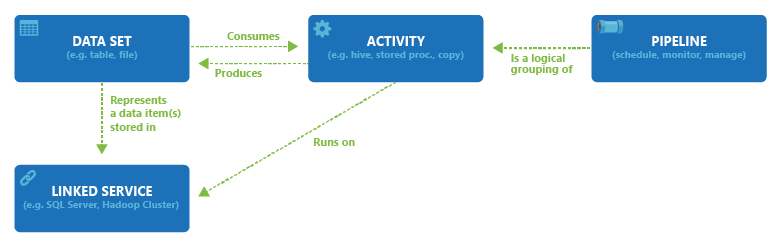
Data Factory 中 Data Set,Activity,Linked Service,Pipeline 直接的关系
Azure Data Factory不存储任何数据。我们可以使用它用于创建数据驱动型工作流,在支持的数据存储之间协调数据的移动(创建一个包含 pipiline 的 Data Factory,将数据从 Blob1 存储移动到 Blob2 存储)。 它还可以用于在其他区域或本地环境中通过计算服务来处理数据。 它还允许使用编程方式及 UI 机制来监视和管理工作流。
三,结尾
今天只是对 Azure Data Factory 有一个初步的认识,以及可以用来做什么,下一篇文章实际创建Aure Data Factory,通过创建 pipeline 配置将 storage1 的数据复制到 storage2 中。
参考资料:Azure Data Factory(英文),Azure Data Factory(中文)
作者:Allen
版权:转载请在文章明显位置注明作者及出处。如发现错误,欢迎批评指正。