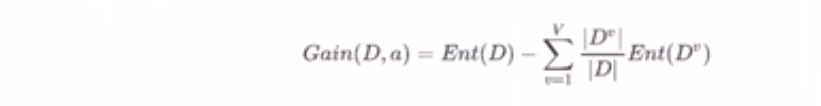决策树有分类树与回归树两种
本节重要记录了分类树
构建决策树的准备工作:
特征选择
选取对训练数据具有分类能力的特征。
利用香农熵(克劳德 香农)
熵(杂乱程度)是表示随机变量不确定性的度量
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值(数学期望)。
熵越小(不纯度)越低
熵越高,信息的不纯度就越高,也就是混合的数据就越多。
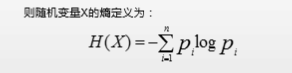
条件熵
条件熵要有条件
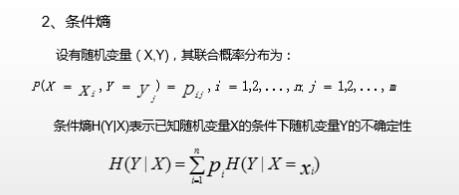
信息增益
父节点的信息熵与其下所有子节点总信息熵之差。子节点的总信息熵不能是简单的求和,而要加以修正。
(原始数据的熵减去所有修正后的子节点之和)

假设离散属性a有V个可能的取值(al,a,……,aV}.若使用a对样本数据集D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为a”的样本,记为D”.我们可根据信息篇的计算公式计算出D”的信息熵,再考虑到不同的分支节点所包含的样本数不同,给分支节点赋予权重1/|D,这就是所谓的的修正。
信息熵增益计算
第0列的信息增益