第一讲 布尔检索Boolean Retrieval
主要内容:
-
信息检索概述
-
倒排记录表
-
布尔查询处理
一、信息检索概述
什么是信息检索?
Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
信息检索是从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文档)的过程。
Document –文档
Unstructured – 非结构化
Information need –信息需求
Collection—文档集、语料库
二、倒排记录表
1、什么是布尔查询?
布尔查询是指利用 AND, OR 或者 NOT操作符将词项 连接起来的查询
如:信息 AND 检索
2、一个信息检索的例子(莎士比亚全集)

不到100万单词,假设每个英文单词平均长度为8字节,则整个全集不到10MB
查询需求:
莎士比亚的哪部剧本包含Brutus及Caesar但是不包含Calpurnia?
查询的布尔表示:
Brutus AND Caesar AND NOT Calpurnia
解决方案:
方法一:暴力方法
从头到尾扫描所有剧本,对每部剧本判断它是否包含Brutus AND Caesar ,同时又不包含Calpurnia
不足之处:
-
速度超慢 (特别是大型文档集)
-
处理NOT Calpurnia 并不容易(不到末尾不能停止判断)
-
不太容易支持其他操作 (e.g., 寻找靠近countrymen的单词Romans)
-
不支持检索结果的(灵活)排序 (排序时只返回较好的结果)
优点:
-
实现简单
-
很容易支持文档动态变化
方法二:倒排记录表
词项-文档(term-doc)关联矩阵
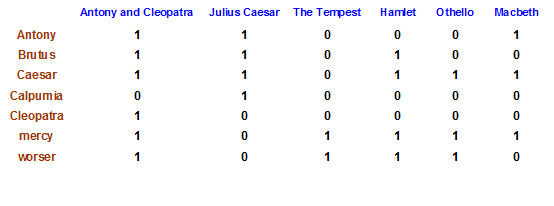
若某剧本包含某单词,则该位置为1,否则为0.
-
关联矩阵的每一列(对应一篇文档)都是 0/1向量,每个0/1都对应一个词项
-
关联矩阵的每一行(对应一个词项)也可以看成一个0/1向量,每个0/1代表该词项在相应文档中的出现与否
-
给定查询Brutus AND Caesar AND NOT Calpurnia
取出三个词项对应的行向量 ,并对Calpurnia 的行向量求反,最后按位进行与操作
110100 AND 110111 AND 101111 = 100100.
问题:当出现更大的文档集???
-
假定N = 1 百万篇文档(1M), 每篇有1000个词(1K)
-
假定每个词平均有6个字节(包括空格和标点符号),那么所有文档将约占6GB 空间.
-
假定词汇表的大小(即词项个数) M = 500K
此时,词项-文档矩阵将非常大!!!
-
矩阵大小为 500K x 1M=500G
-
但是该矩阵中最多有10亿(1G)个1:词项-文档矩阵高度稀疏(sparse)
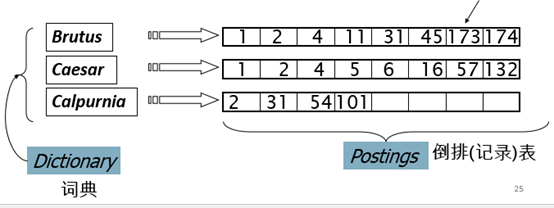
更好的办法:仅仅记录1的位置,即倒排索引
-
对每个词项t, 记录所有包含t的文档列表.
-
每篇文档用一个唯一的 docID来表示,通常是正整数,如1,2,3…
-
磁盘上,顺序存储方式比较好,便于快速读取
-
内存中,采用链表或者可变长数组方式
-
倒排记录表按docID排序
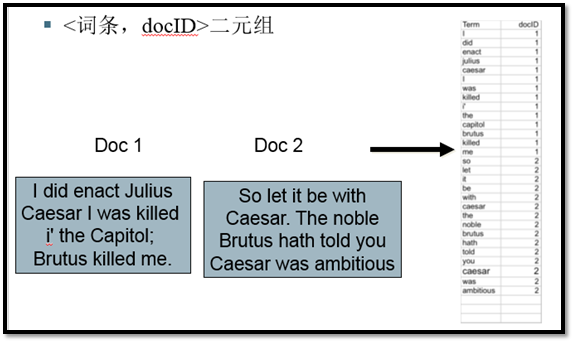
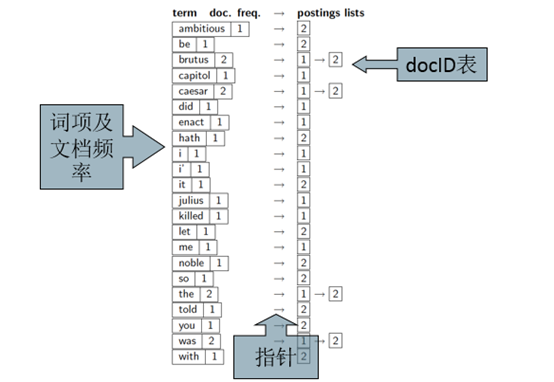
索引构建过程:
1、词条序列:<词条,docID>二元组
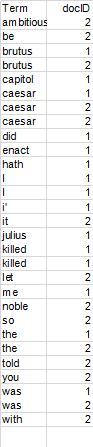
2、排序
按词项排序,然后每个词项按docID排序

-
词典&倒排记录表
-
某个词项在单篇文档中的多次出现会被合并
-
拆分成词典和倒排记录表两部分
-
每个词项出现的文档数目(doc frequency, DF)会被加入

3、布尔查询的处理
假定索引已经构建好了,如何利用索引来处理查询?
AND查询的处理:
考虑如下查询(从简单的布尔表达式入手):
Brutus AND Caesar
-
在词典中定位 Brutus
-
返回对应倒排记录表(对应的docID)
-
在词典中定位Caesar
-
再返回对应倒排记录表
-
合并(Merge)两个倒排记录表,即求交集

合并过程:
每个倒排记录表都有一个定位指针,两个指针同时从前往后扫描, 每次比较当前指针对应倒排记录,然后移动某个或两个指针。合并时间为两个表长之和的线性时间

-
假定表长分别为x 和y, 那么上述合并算法的复杂度为 O(x+y)
-
关键原因: 倒排记录表按照docID排序
-
上述合并算法的伪代码:

其它布尔查询的处理
-
OR表达式:Brutus OR Caesar
-
两个倒排记录表的并集
-
NOT表达式: Brutus AND NOT Caesar
-
两个倒排记录表的减
一般的布尔表达式
(Brutus OR Caesar) AND NOT (Antony OR Cleopatra)
查询处理的效率问题
-
查询处理中是否存在处理的顺序问题?
-
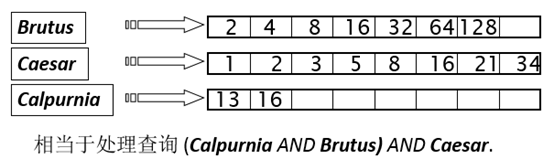
考虑n 个词项的 AND
-
对每个词项,取出其倒排记录表,然后两两合并
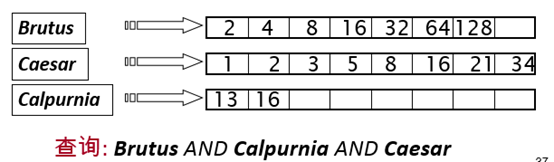
- 按照表从小到大(即df从小到大)的顺序进行处理: 每次从最小的开始合并

布尔检索的优点:
构建简单,或许是构建IR系统的一种最简单方式
布尔检索的缺点:
-
布尔查询构建复杂,不适合普通用户。构建不当,检索结果过多或者过少
-
没有充分利用词项的频率信息
-
不能对检索结果进行排序