主要内容:
1、什么是基于用户的协同过滤
2、python实现
1、什么是基于用户协同过滤:
协同过滤:Collaborative Filtering,一般用于推荐系统,如京东,亚马逊等电商网站上的“购买该物品的用户还喜欢/购买”之类的栏目都是根据协同过滤推荐出来的。
基于用户的协同过滤:User-based CF,通过不同用户对item(物品)的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。
这里介绍一种最简单的过滤方法:最近邻,即找到与某用户最相似的用户,将该用户喜欢的物品(而某用户并未评分的物品)推荐给某用户。
缺点:
1、用户少,物品多,并不是每个用户都对每个物品进行过评分,因此存在缺失值;
2、如果相似的用户和被推荐的用户评分的物品都相同,会出现无物品推荐的情况;
细节:
衡量相似性:曼哈顿距离,欧几里得距离等(简单,后续介绍其他相似度的计算方法)
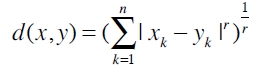
当r=1,为曼哈顿距离;当r=2,为欧几里得距离。
2、Python实现
场景:基于用户对一些书籍的评分,来为某些用户推荐书籍;
数据:如下表
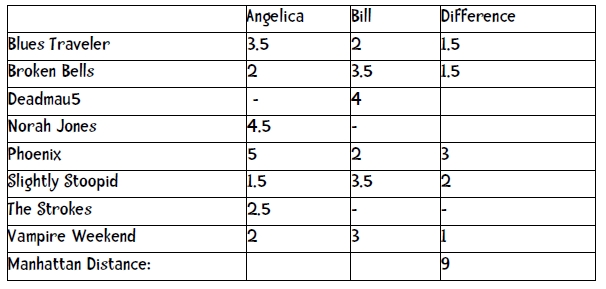
实现:
Python(有关python的语法就不介绍了,直接贴出代码)
# # FILTERINGDATA.py # # Code file for the book Programmer's Guide to Data Mining # http://guidetodatamining.com # Ron Zacharski # from math import sqrt users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0, "Norah Jones": 4.5, "Phoenix": 5.0, "Slightly Stoopid": 1.5, "The Strokes": 2.5, "Vampire Weekend": 2.0}, "Bill":{"Blues Traveler": 2.0, "Broken Bells": 3.5, "Deadmau5": 4.0, "Phoenix": 2.0, "Slightly Stoopid": 3.5, "Vampire Weekend": 3.0}, "Chan": {"Blues Traveler": 5.0, "Broken Bells": 1.0, "Deadmau5": 1.0, "Norah Jones": 3.0, "Phoenix": 5, "Slightly Stoopid": 1.0}, "Dan": {"Blues Traveler": 3.0, "Broken Bells": 4.0, "Deadmau5": 4.5, "Phoenix": 3.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 2.0}, "Hailey": {"Broken Bells": 4.0, "Deadmau5": 1.0, "Norah Jones": 4.0, "The Strokes": 4.0, "Vampire Weekend": 1.0}, "Jordyn": {"Broken Bells": 4.5, "Deadmau5": 4.0, "Norah Jones": 5.0, "Phoenix": 5.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 4.0}, "Sam": {"Blues Traveler": 5.0, "Broken Bells": 2.0, "Norah Jones": 3.0, "Phoenix": 5.0, "Slightly Stoopid": 4.0, "The Strokes": 5.0}, "Veronica": {"Blues Traveler": 3.0, "Norah Jones": 5.0, "Phoenix": 4.0, "Slightly Stoopid": 2.5, "The Strokes": 3.0} } def manhattan(rating1, rating2): """Computes the Manhattan distance. Both rating1 and rating2 are dictionaries of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}""" distance = 0 commonRatings = False for key in rating1: if key in rating2: distance += abs(rating1[key] - rating2[key]) commonRatings = True if commonRatings: return distance else: return -1 #Indicates no ratings in common def minskowski(rating1,rating2): distance=0 commonRatings=Flase for key in rating1: for key in rating2: distance+=pow(abs(rating1[key]-rating2[key]),r) commonRatings=True if commonRatings: return pow(distance,1/r) else: return 0 #indicates no ratings in common def computeNearestNeighbor(username, users): """creates a sorted list of users based on their distance to username""" distances = [] for user in users: if user != username: distance = manhattan(users[user], users[username]) #distance = minskowski(users[user], users[username], 2) distances.append((distance, user)) # sort based on distance -- closest first distances.sort() return distances def recommend(username, users): """Give list of recommendations""" # first find nearest neighbor nearest = computeNearestNeighbor(username, users)[0][1] recommendations = [] # now find bands neighbor rated that user didn't neighborRatings = users[nearest] userRatings = users[username] for artist in neighborRatings: if not artist in userRatings: recommendations.append((artist, neighborRatings[artist])) # using the fn sorted for variety - sort is more efficient return sorted(recommendations, key=lambda artistTuple: artistTuple[1], reverse = True) # examples - uncomment to run print( recommend('Hailey', users)) #print( recommend('Chan', users))
3、参考文献:
http://www.guidetodatamining.com/chapter2/