DynamoDB Consistency Models
Eventually Consistent Reads
Consistency across all copies of data is usually reached within a second
Best for read perforamnce
Strongly Consistent Reads
A strongly consistent read always reflects all successful writes. Writes are reflected across all 3 locations at once.
Best for read consistency
ACID Transactions
DynamoDB Transactions provide the ability to perform ACID Transactions (Atomic, Consistent, Isolated, Durable) Read or write multiple items across multiple tables as an all or nothing operations.
Goo for payment process.
Primary Keys
Partition Key
A unique attribute.
Composite Key
- Partition Key + Sort Key
When partition key is not unique.
For example: Forum posts, Users post multiple messages.
Combination of:
- User_ID
- Sort key (timestamp)
2. A Unique Combination
Items in the table may have the same partition key, but they must have a differnet sort key.
3. Storage
All items with the same partition key are stored together and then sorted according to the sort key value.

Access Control
- IAM
- IAM Permission: access and create DynamoDB tables
- IAM Roles: Enabling temporary access to DynamoDB
Restricting User Access
You can also use a special IAM Condtion to restrict user access to only their own records.


IAM condition paramter dynamodb:LeadingKeys allow users to access only the itmes where partition key value matches their User_ID
Indexes Deepdive
Flexible Querying
Query based on an attribute that is not the primary key.
DynamoDB allows you to run a query on non-primary key attributes using global secondary indexes and local secodnary index.
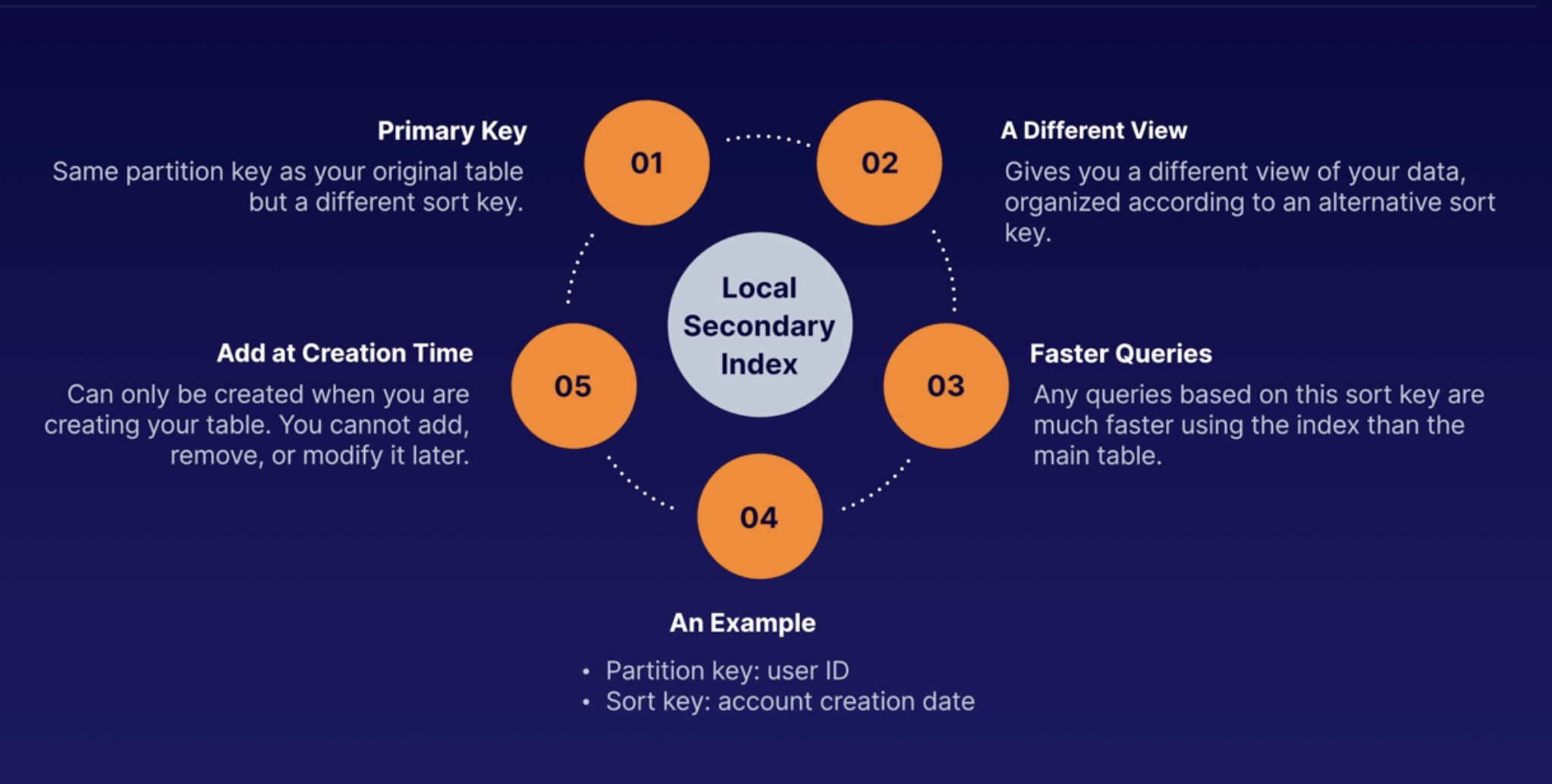
Local Secondary Index
- Must be created when creating the table
- Same partition key and different sort key to your table
Gloabl Secondary Index
- Different partition key and different sort key to your table
- Can be created any time
- Creates copy of the data in a table (data is available via GSI after some delay)

Creating indexes in DynamoDB
1. Create table with Partition key and sort key
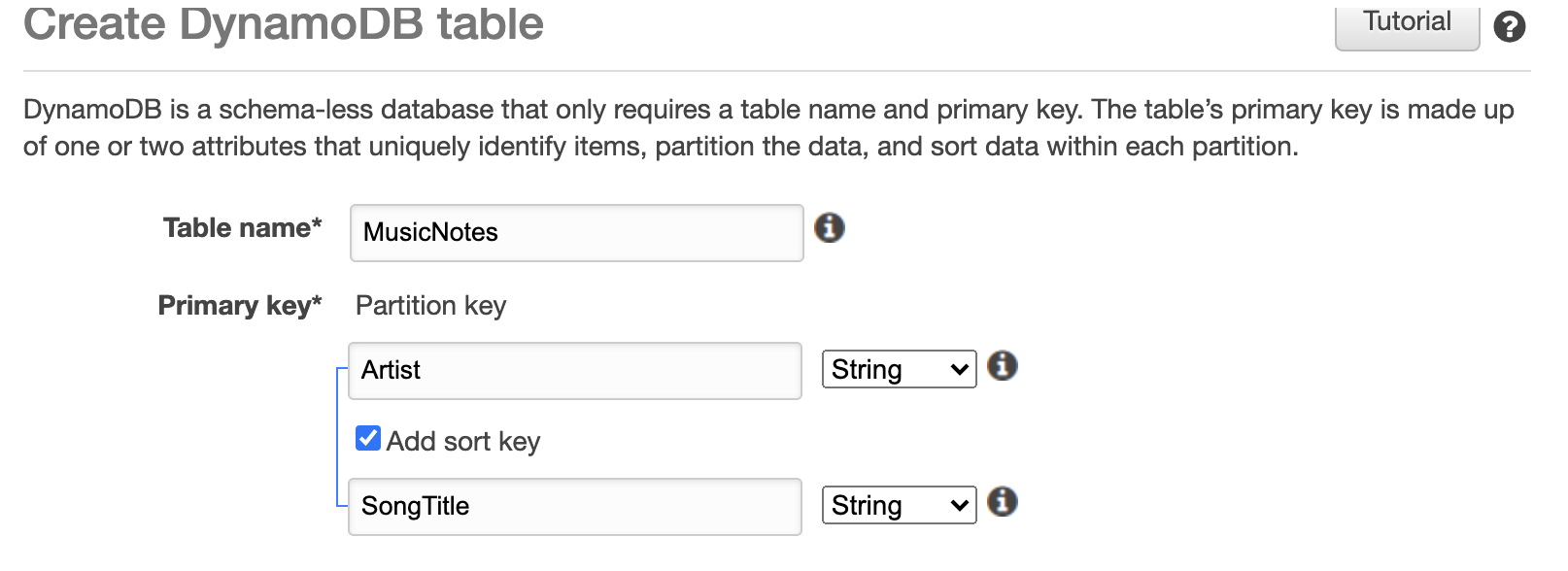
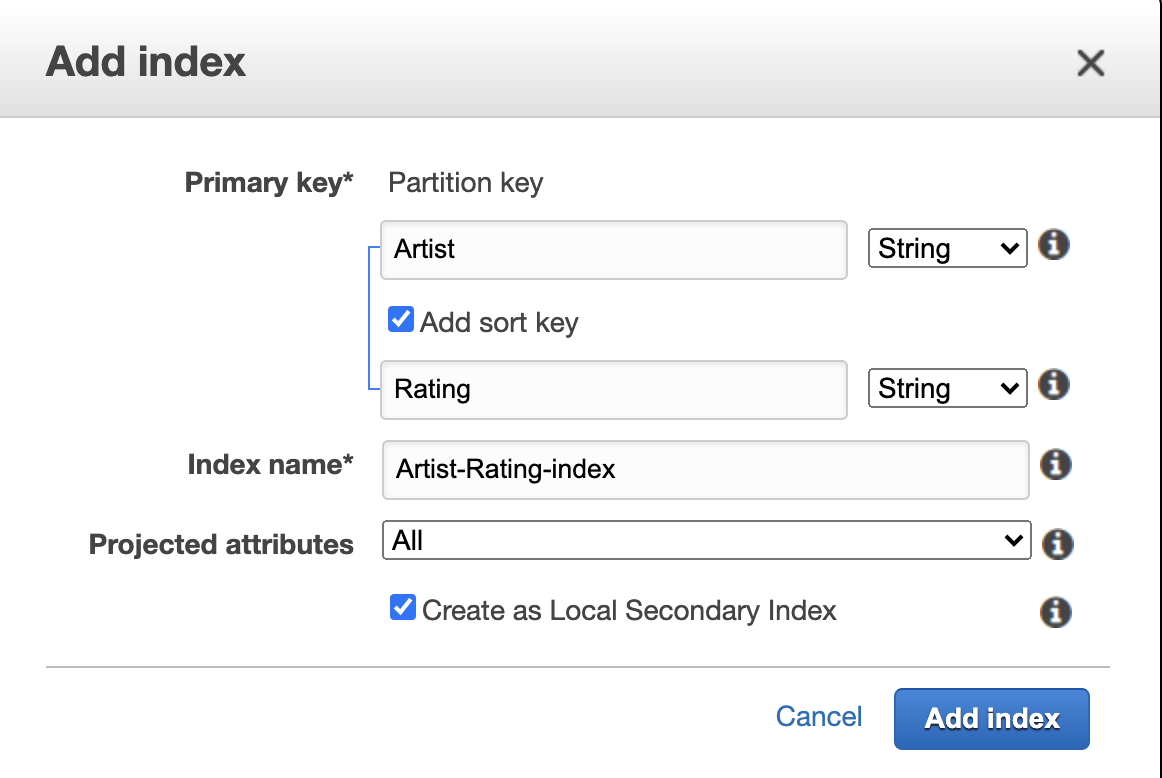
2. Add Local secondary Indexes (LSI)
Recall that for LSI, the partition key is the same as Primary key's partiion key, when this can only be created during creating new table.
Remeber to check the checkbox for LSI
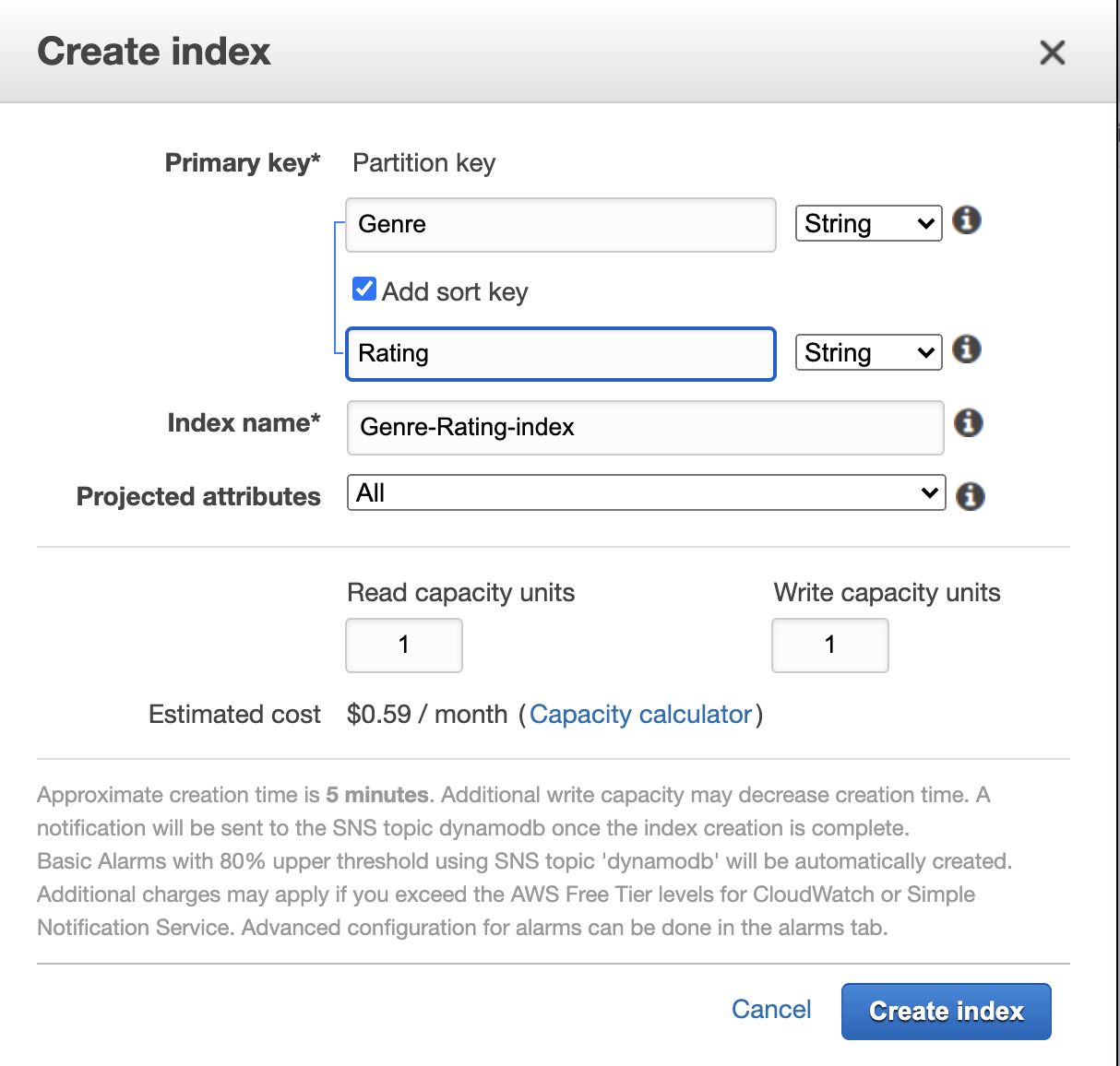
3. After creating table, we can create Global secondary index
Recll that GSI can be created any time, the partiion key can be different from Primary key's partition key.
4. GSI can ONLY be used by CLI / SDK, not possible yet with GUI.
Therefore when you do Query, you can only see the LSI and Primary key.

Scan vs Query
Query
A query find items in a table based on the primary key attribute and a distinct value to search for.

Scan
A scan operation examines every item in the table. By default, it returns all data attributes.
Use the ProjectionExpression parameter to refine the scan to only return the attributes you want.
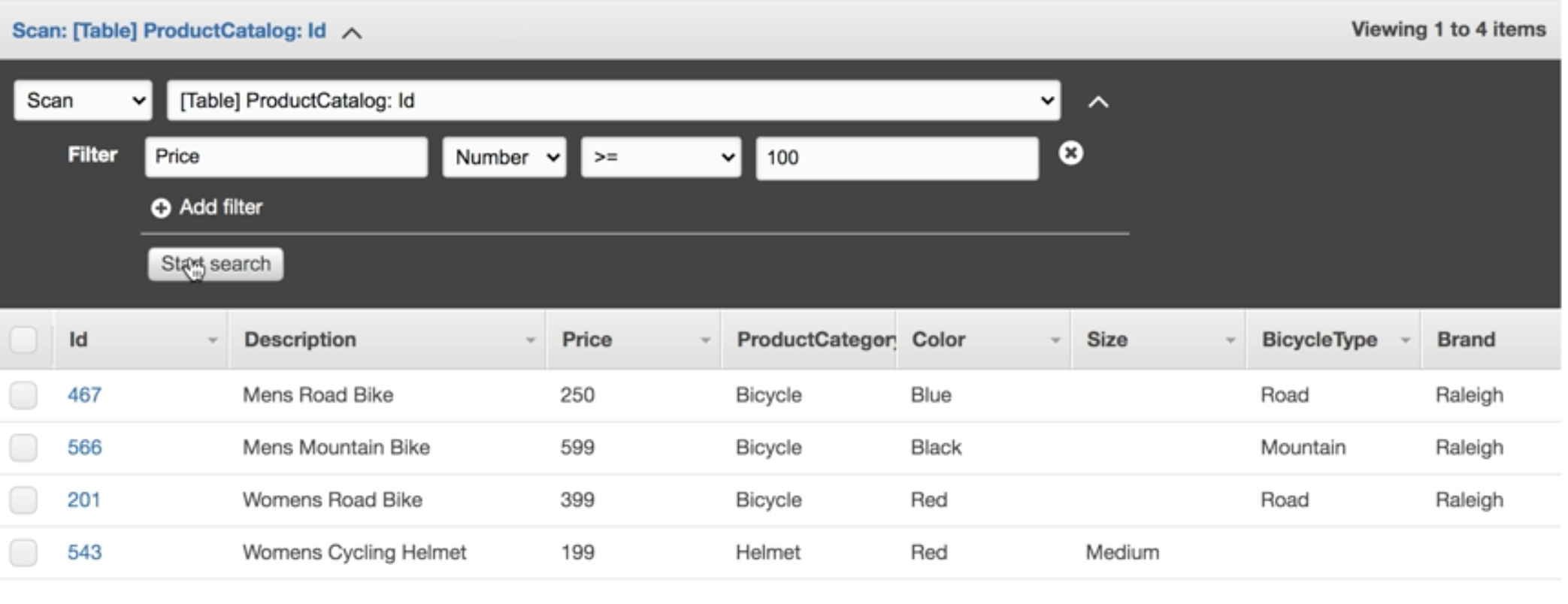
Query vs Scan
- Query is More efficient Than a Scan: Because A Scan dump the entire table and filters out the values to provide the desired result, removing the unwanted data.
- Extra Step: Adds an extra step of remoing the data you don't want. As table grows, the scan operation takes longer.
- Provisioned Thoughput: A scan operation on a large table can use up the provisioned throughput for a large table in just a single operation.
Improving Performance
- Set a smaller page size (e.g page size of 40 items)
- Running a larger number of smaller operations will allow other requests to succeed iwthout throttling.
- AVOID SCANS!
- Design tables in a way that you can use the Query, Get, or BatchGetItem APIs.
Improving Scan Performance
- Isolate scan operations to specific tables and segregate them from your mission critical traffic. Even if that means writing data to 2 different tables
- By default, a scan operation processes data sequentially in returning 1MB increments before moving on to retrieve the next 1 MB of data. It can only scan one partition at a time.
- You can configure DynamoDB to use Parallel scans instead of logically dividing a table or index into segments and scanning each segment in parallel
- Best to AVOID parallel scans if your table or index is already incurring heavy read / write activity from other applications.
DynamoDB Provisioned Throuhhput
DynamoDB Provisioned Throughput is measured in Capacity Units.
When you create your table, you specify your requirements in terms of Read Capacity Units and Write Capacity Units.
Write Capacity Units
1 * 1KB write per second
Strongly Consistent Reads
1 * 4KB read per second
Eventually Consistent
2 * 4KB per second
Your application needs to read 80 items per second, each item is 3 KB in size. You need strongly consistent reads. How many read capacity units will you need?
1. Calculate the size of each item / 4 KB -> 3KB/4KB = 0.75, round to 1, so need 1 read capacity unit
2. Multiply by the number of read operations per second -> 80 * 1 = 80
How about eventually consistent read?
Stongly consistent read / 2 -> 80 / 2 = 40
You want to write 100 items per scond. Each item is 512 bytes in size, how many write capacity units do you think you will need?
512byte/1KB = 0.5
round to 1
100 * 1 = 100
DynamoDB Low-Level API
Doc: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.LowLevelAPI.html
DynamoDB provide SDK for many programming language, but if there is no such SDK for your project using langauge, you can use low-level API to using DynamoDB
The Amazon DynamoDB low-level API is the protocol-level interface for DynamoDB. At this level, every HTTP(S) request must be correctly formatted and carry a valid digital signature.
The low-level DynamoDB API uses JavaScript Object Notation (JSON) as a wire protocol format.
Requet Format:
POST / HTTP/1.1 Host: dynamodb.<region>.<domain>; Accept-Encoding: identity Content-Length: <PayloadSizeBytes> User-Agent: <UserAgentString> Content-Type: application/x-amz-json-1.0 Authorization: AWS4-HMAC-SHA256 Credential=<Credential>, SignedHeaders=<Headers>, Signature=<Signature> X-Amz-Date: <Date> X-Amz-Target: DynamoDB_20120810.GetItem { "TableName": "Pets", "Key": { "AnimalType": {"S": "Dog"}, "Name": {"S": "Fido"} } }
- The
Authorizationheader contains information required for DynamoDB to authenticate the request. Need to sign the request using AWS access keys and Signature Version 4 - The
X-Amz-Targetheader contains the name of a DynamoDB operation:GetItem. - The payload (body) of the request contains the parameters for the operation, in JSON format. For the
GetItemoperation, the parameters areTableNameandKey.
DynamoDB API
It is important to know about what apis you can use for DynamoDB.
Such as GetItem, BatchGetItem, PutItem, UpdateItem, ConditionalWrites, ConditionalDelete
Here we just memetion Conditional write/delete:
- Accept a write / update only if conditions are respected, otherwise reject
- Help with concurrent access to items
- No performacne impact
DynamoDB Indexes and Throttling
GSI:
- if the writes are throttled on GSI, then the main table will be throttle
- Event if the WCU on the main tables are fine
- We need to choose GSI partition key carefully
- Make sure GSI has enough WCU as well
GSI creates a NEW Table, when creating the GSI, you need to define RCU / WCU as well.
DynamoDB Concurrency
- DynamoDB has a feature called "Conditional Update / Delete"
- That means that you can ensure an item hasn't changed before altering it
- That makes DynamoDB an Optimistic locking / concurrency database
DynamoDB On-Demand Capacity
DynamoDB Accelerator (DAX)
Solve the Hot Key Problem (too many reads)
TTL for 5 mins
DynamoDB Accelerator (or DAX) is a fully managed, clustered in-memory cache for DynamoDB.
Delivers up to 10x read performance improvement. Microsecond performance for millions of requests per second.

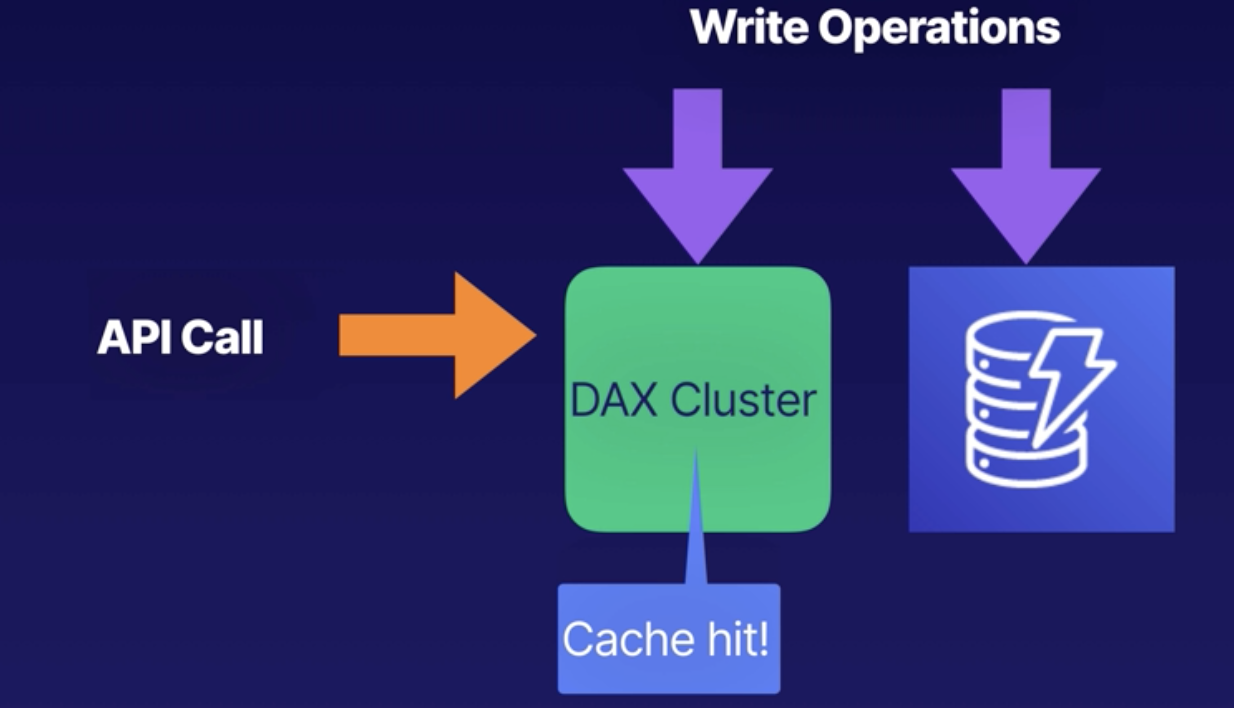
How does it work?
DAX is a write-through caching service. Data is written to the cache and the backend store at the same time.
This allows you to point your DynamoDB API calls at the DAX cluster first.
If the item you are query is in the cache (cache hit), DAX return the result to application.
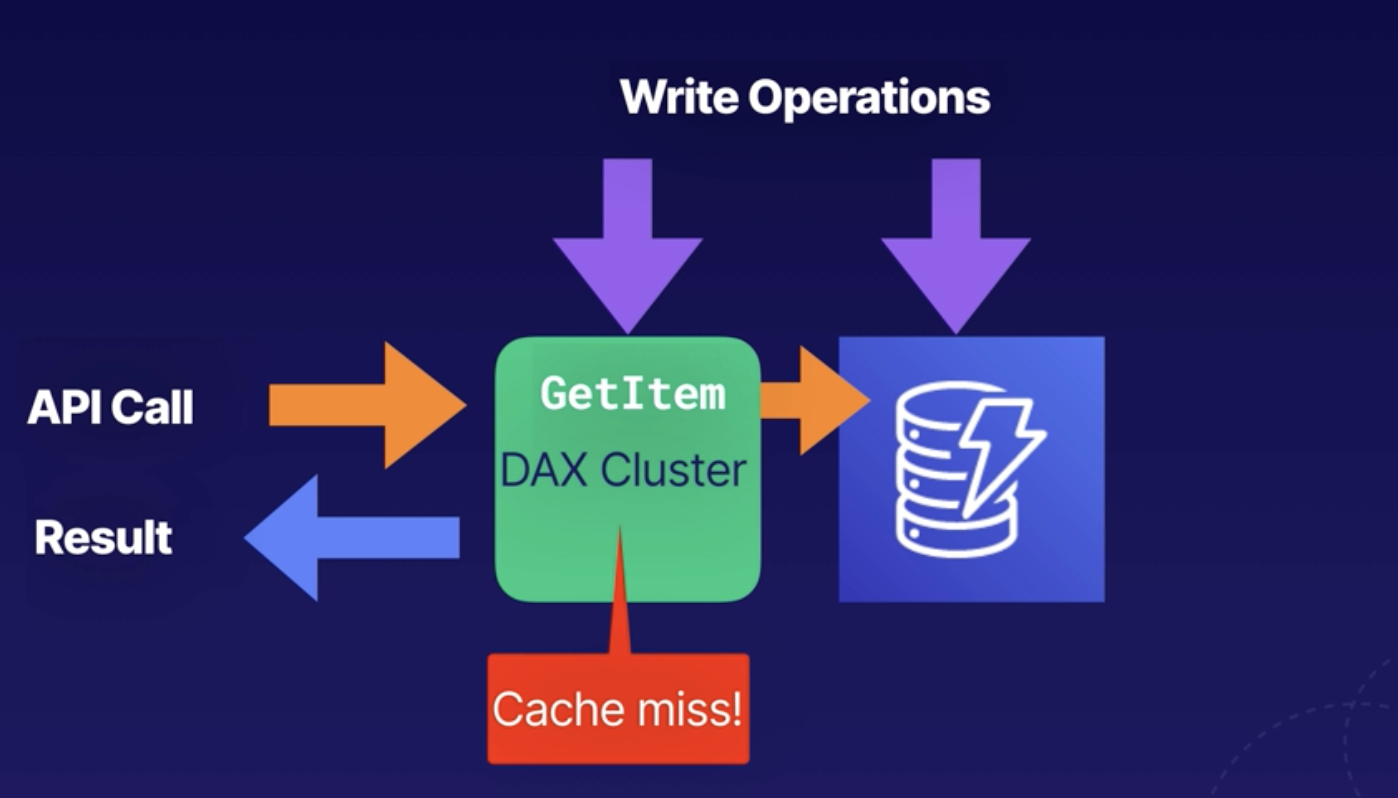
If the item is not available (cache miss), then DAX performs an eventually consistent GetItem operation against DynamoBD and returns the result of the API call.
When is DAX Not suitable?
Caters for eventually consistent reads only.
- Not suitable for applications that require stronly consistent reads.
- Not suitable for applications which are mainly write-intensive
- Application that do not perform many read operations.
- Applications that do not require microsecond response times
DAX vs ElastiCache
- DAX: caching individual object for Query or Scan for simple use cases
- ElastiCachce: more advance, store aggregation result, so next time you don't need to do the same query, just return the result.
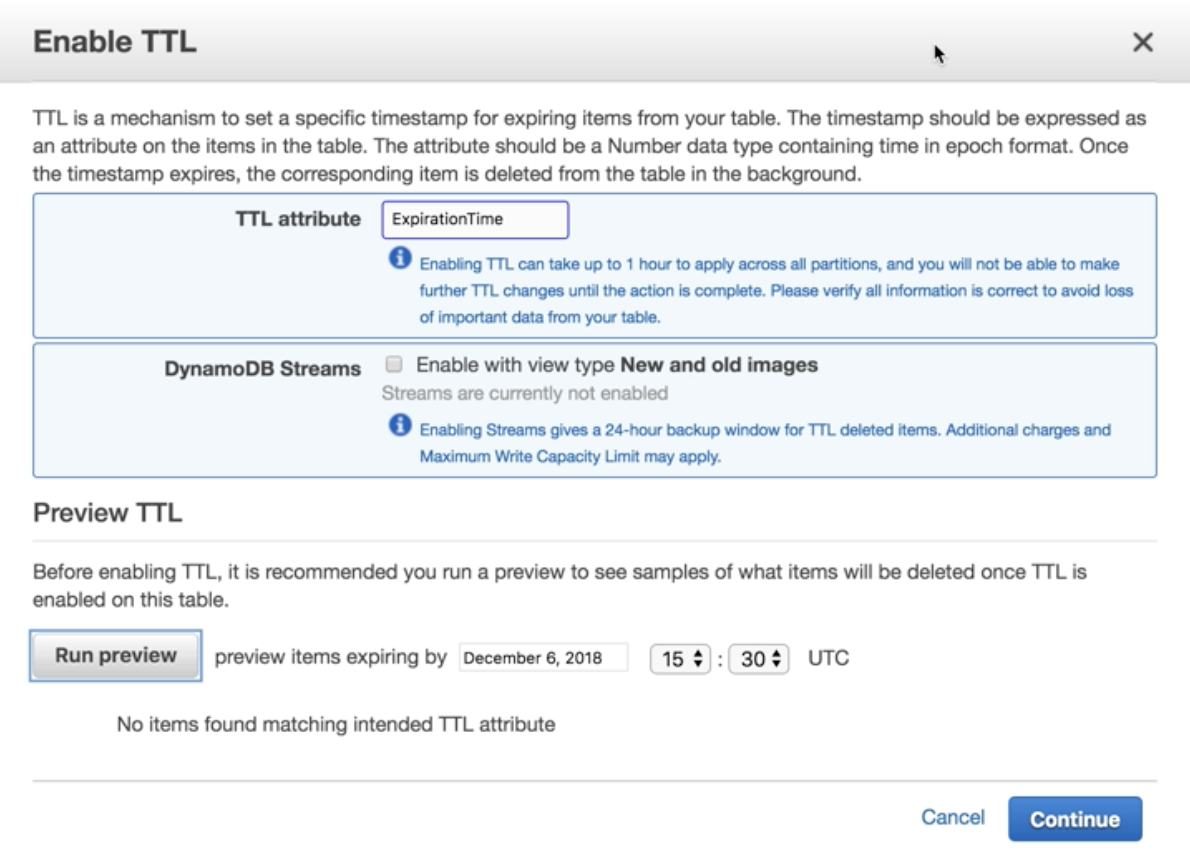
DynamoDB Time To Live (TTL)
Defines an expiry time of your data. Expired itmes marked for deletion in next 48 hours.
- Greate for removing irrlevant or old data, (e.g, session data, event logs, and temporary data)
- Reduces the cost of your table by automatically removing data which is no longer relevant.
DynamoDB Streams
Good for trigger Lambda event.

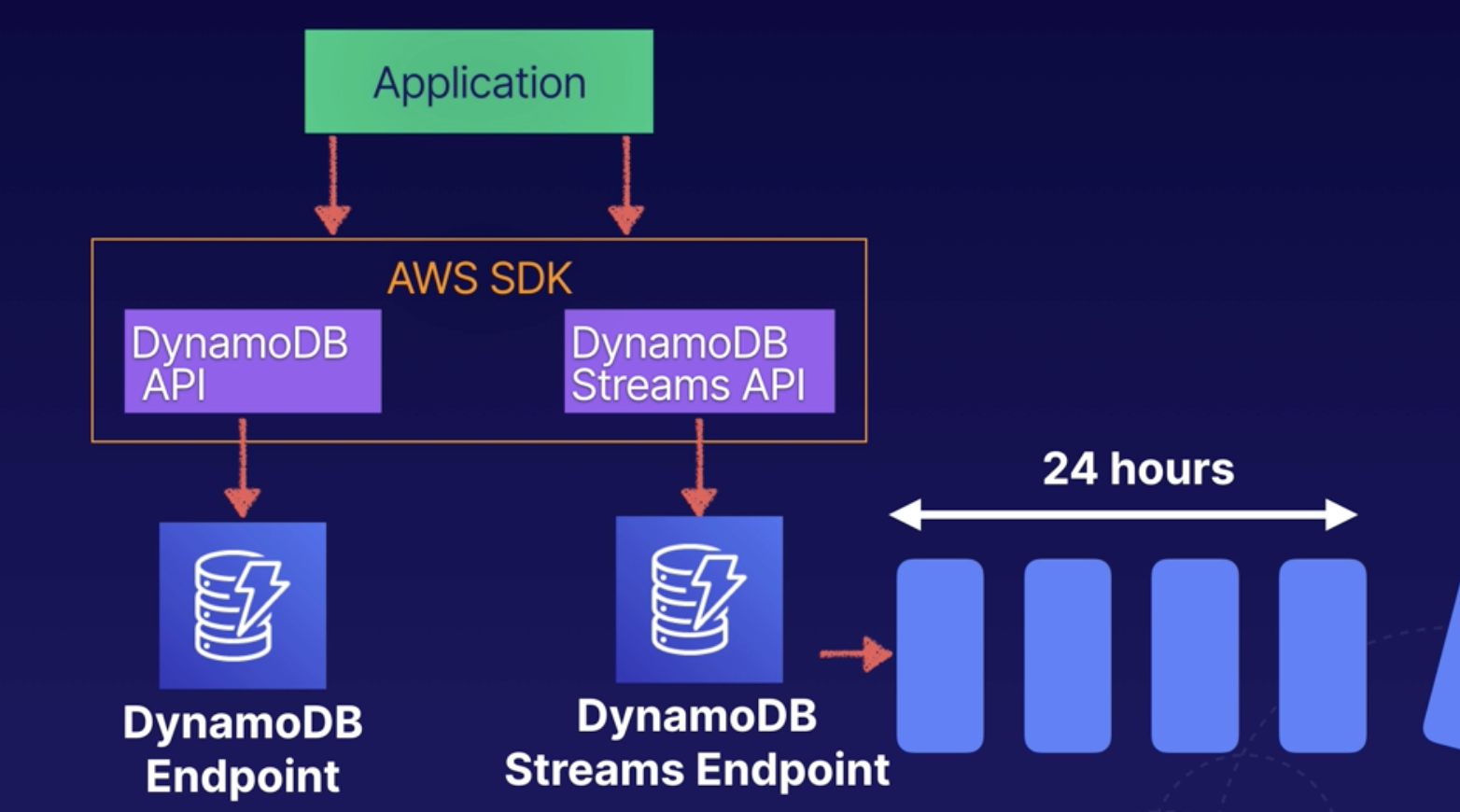
Recoreds are not retroactively populated in a stream after enabling it. Only the future data after enabled stream.
4 Different Stream types
- KEYS_ONLY: Only the key attributes of the modified item
- NEW_IMAGE: The entire item, as it appears after it was modfiied
- OLD_IMAGE: The entire item, as it apperared before it was modified
- NEW_AND_OLD_IMAES: Both the new and the old images of the item
DynamoDB Exponential Backoff Exam

- ProvisionedThroughputExceeded: ProvisionedThroughputExceededException error means the number of requests is too high.
- Better Flow Control: Exponential backoff improves flow by retrying requests using progressively longer waits.
- Every AWS SDK: Exponential backoff is a feature of every AWS SDK and applies to many serices within AWS.

Atomic is mainly increase / descrese by the number
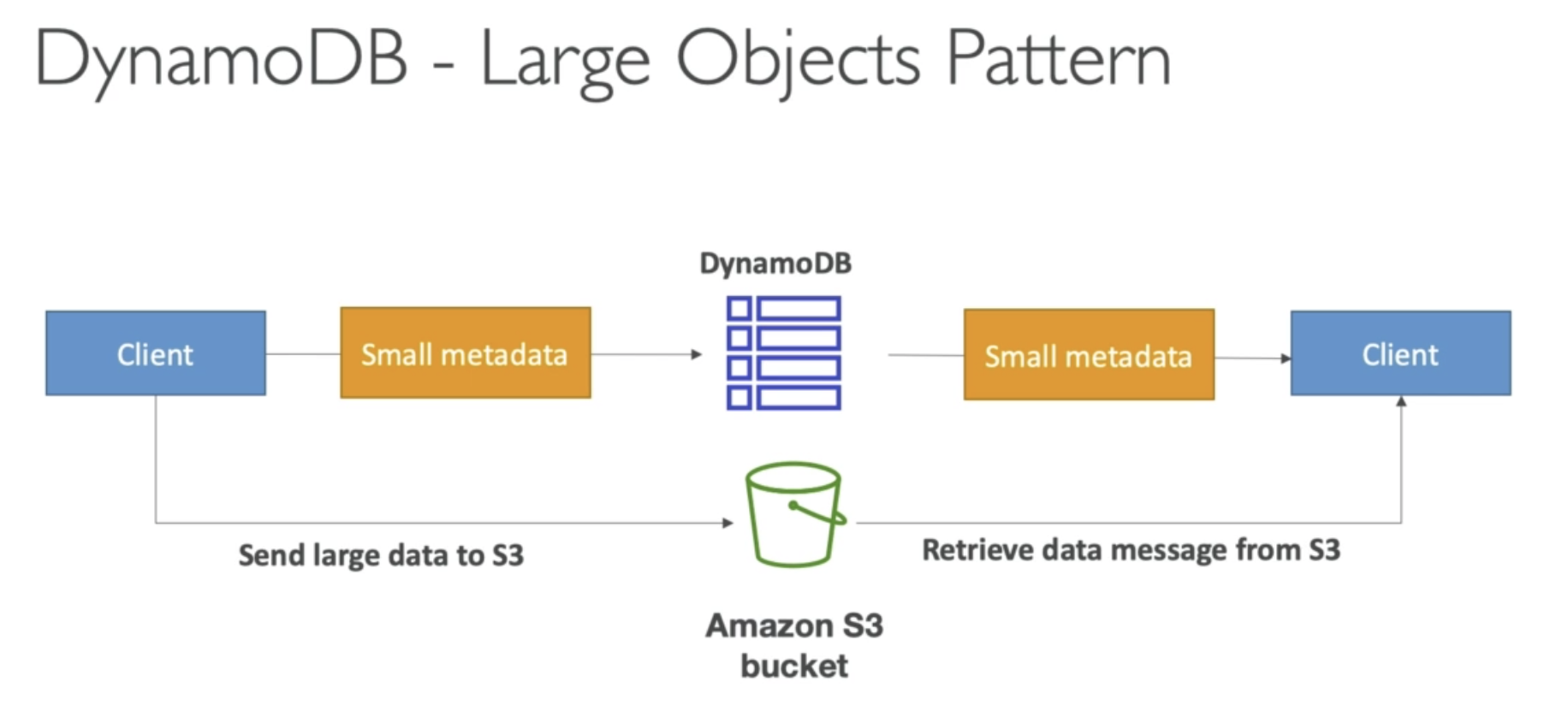
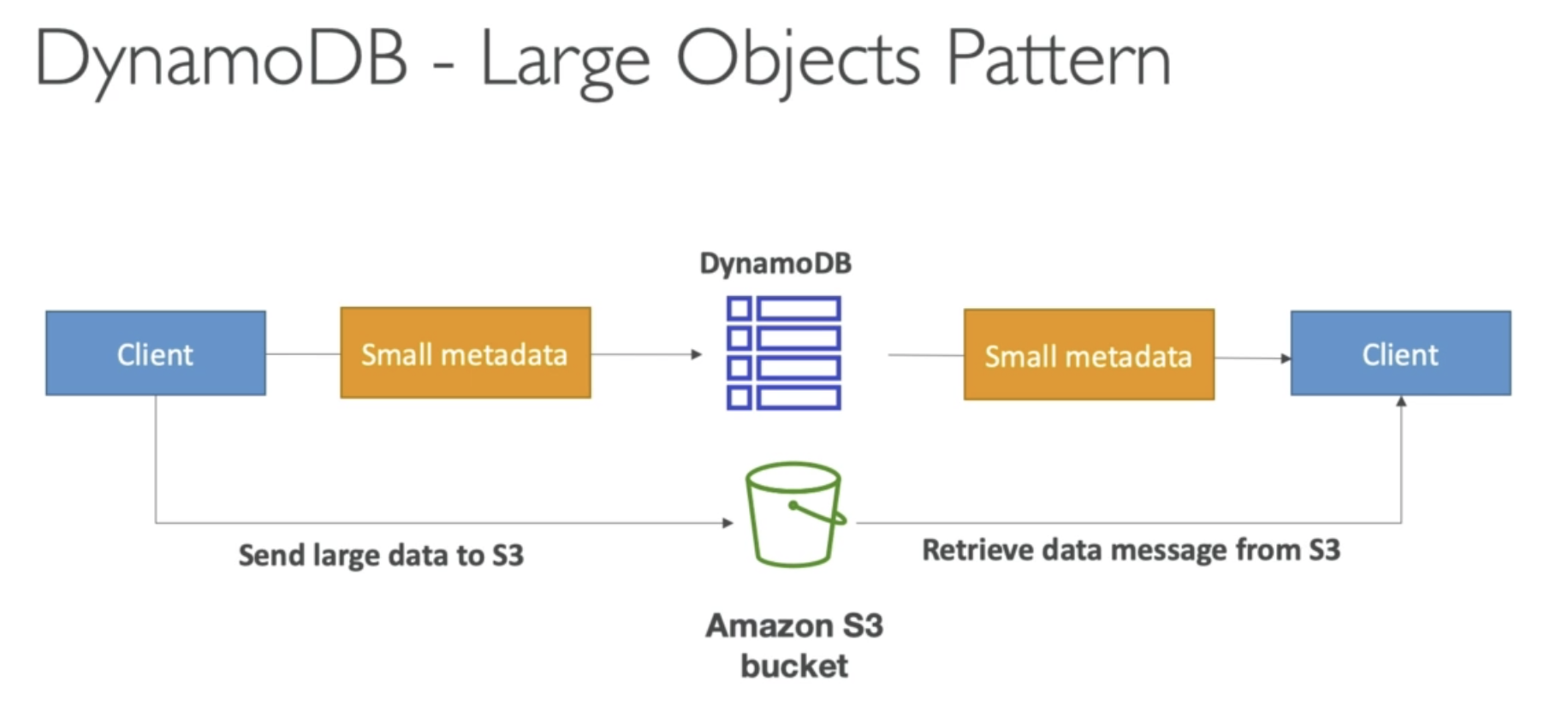
Using DynamoDB, max size is 400KB for each item.
If larger than 400KB, you need to save the item into S3.
Then save the metadata into DynamoDB table.
Then clinet will get object from S3.

If we save itme into S3, we lost the search functionality. Way to solve it is trigger a Lambda function, write metadata into DynamoDB then we can do the searching in DynamoDB table.

- Clean Table: best is drop table and recreate table
- Copy a Table: best is create a backup and restore the backup into a new table name
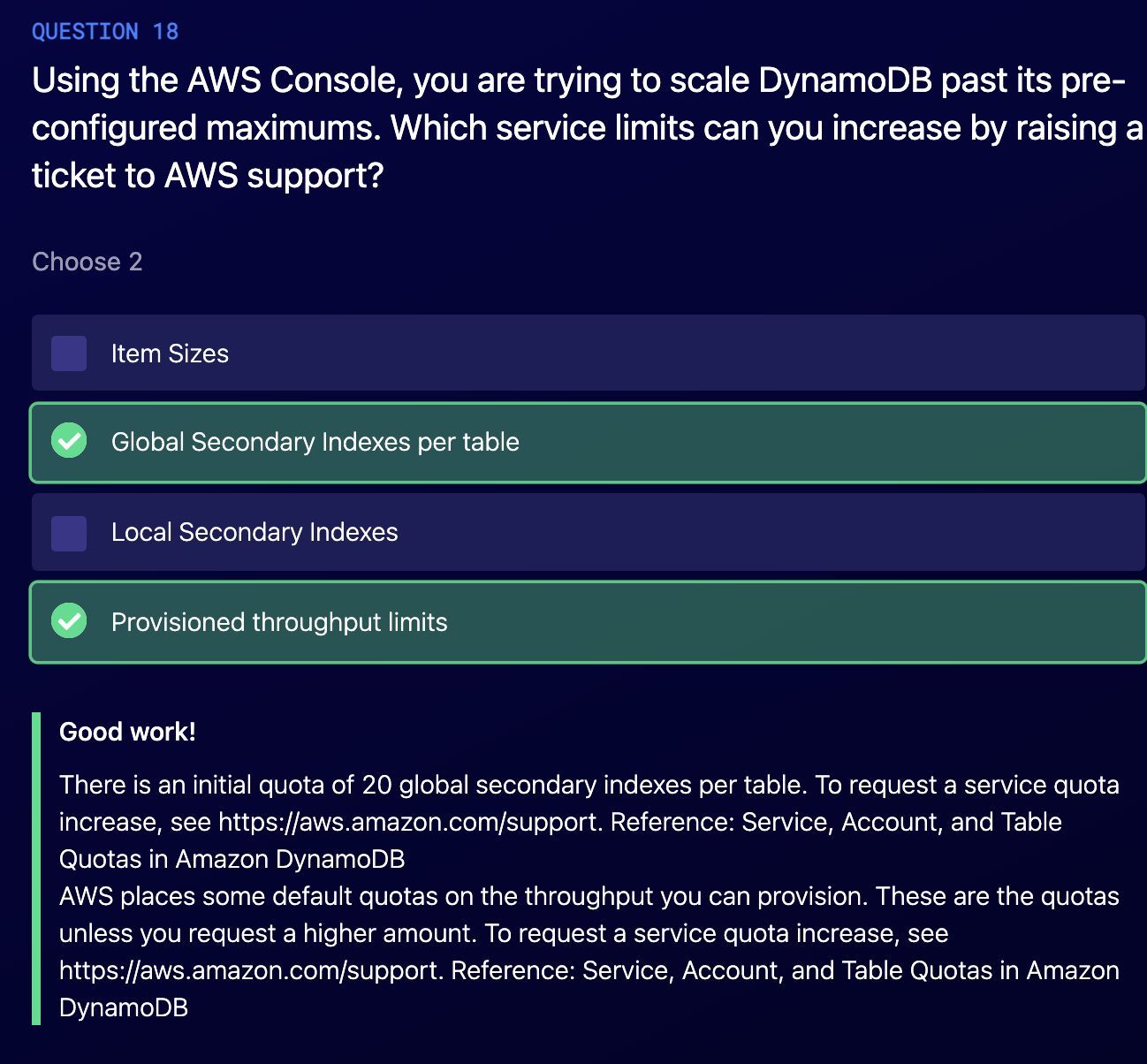
Global Secondary indexes has a limit 20.


You need use filter, by default there is no filter.

https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_Query.html
Only `GetItem`, `UpdateItem`, `DeleteItem` for single item
And `BatchGetItem`, `BatchExecuteStatement`, `BatchWriteItem`.

(Item size / read size) * itemPreSecond / 2 (if eventually consistent)
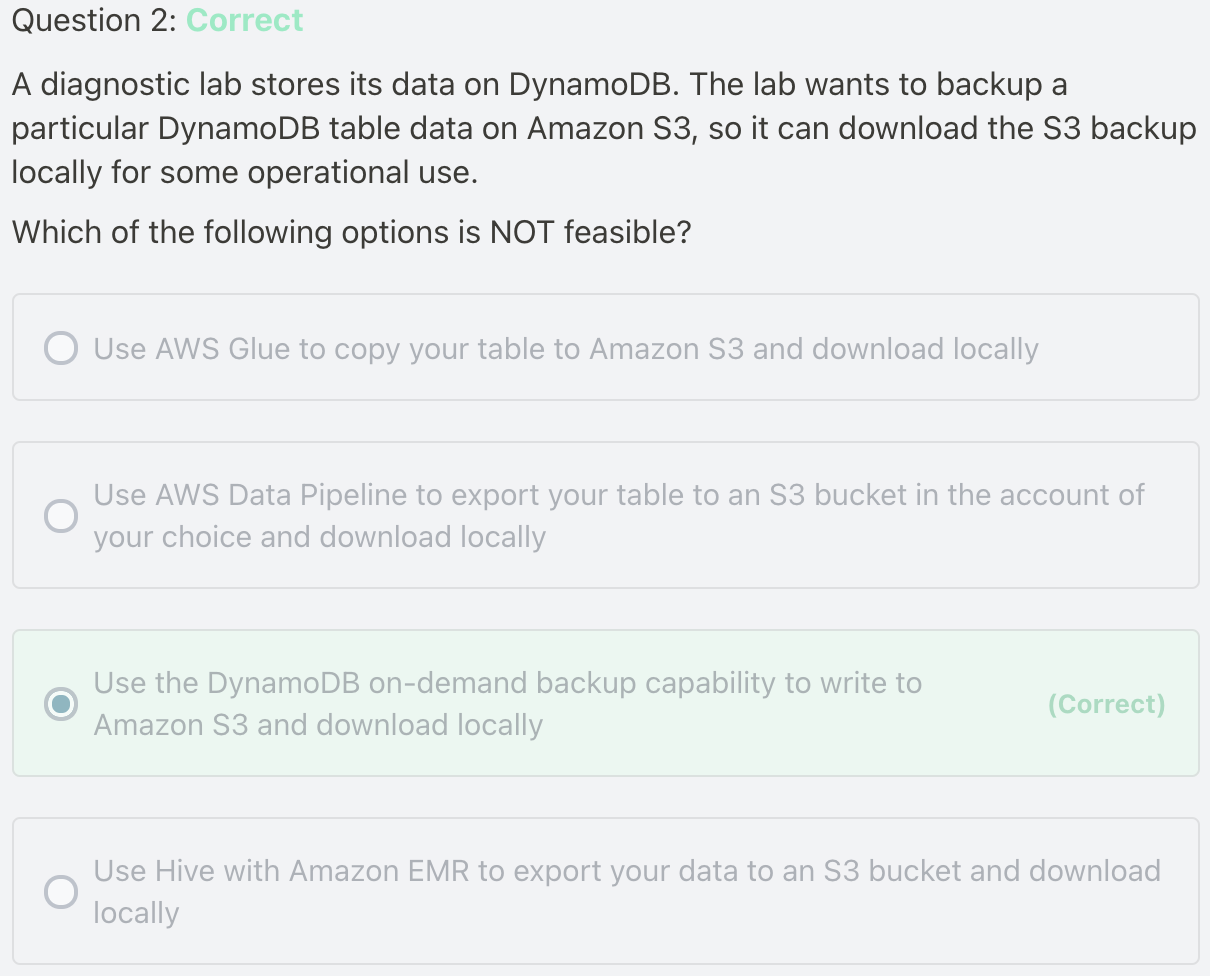
Refer: How can I back up a DynamoDB table to Amazon S3?
DynamoDB offers two built-in backup methods:
- On-demand: Create backups when you choose.
- Point-in-time recovery: Enable automatic, continuous backups.
Both of these methods use Amazon S3. However, you don't have access to the S3 buckets that are used for these backups. The DynamoDB Export to S3 feature is the easiest way to create backups that you can download locally or use in another AWS service. If you need more customization, use AWS Data Pipeline, Amazon EMR, or AWS Glue instead.
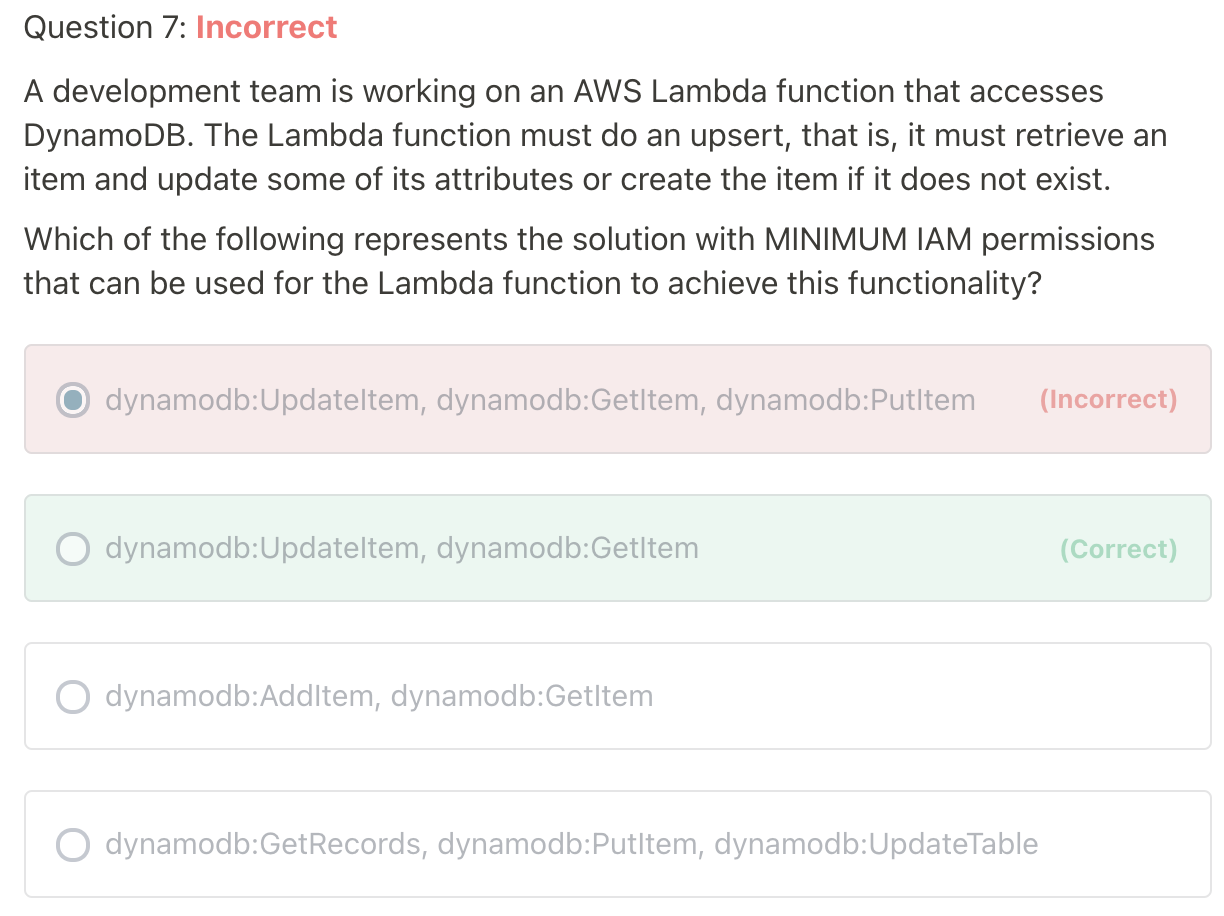
Ref: https://docs.aws.amazon.com/service-authorization/latest/reference/list_amazondynamodb.html
PutItem: Creates a new item, or replaces an old item with a new item
UpdateItem: Edits an existing item's attributes, or adds a new item to the table if it does not already exist
According to the desc: "..it must retrieve an item and update some of its attributes or create the item if it does not exist" - upateItem is enough. We don't have the usecase for replace one item, therefore PutItem is not necessary.
For the ConditionCheck action, you can use the
dynamodb:ConditionCheckpermission in IAM policies.
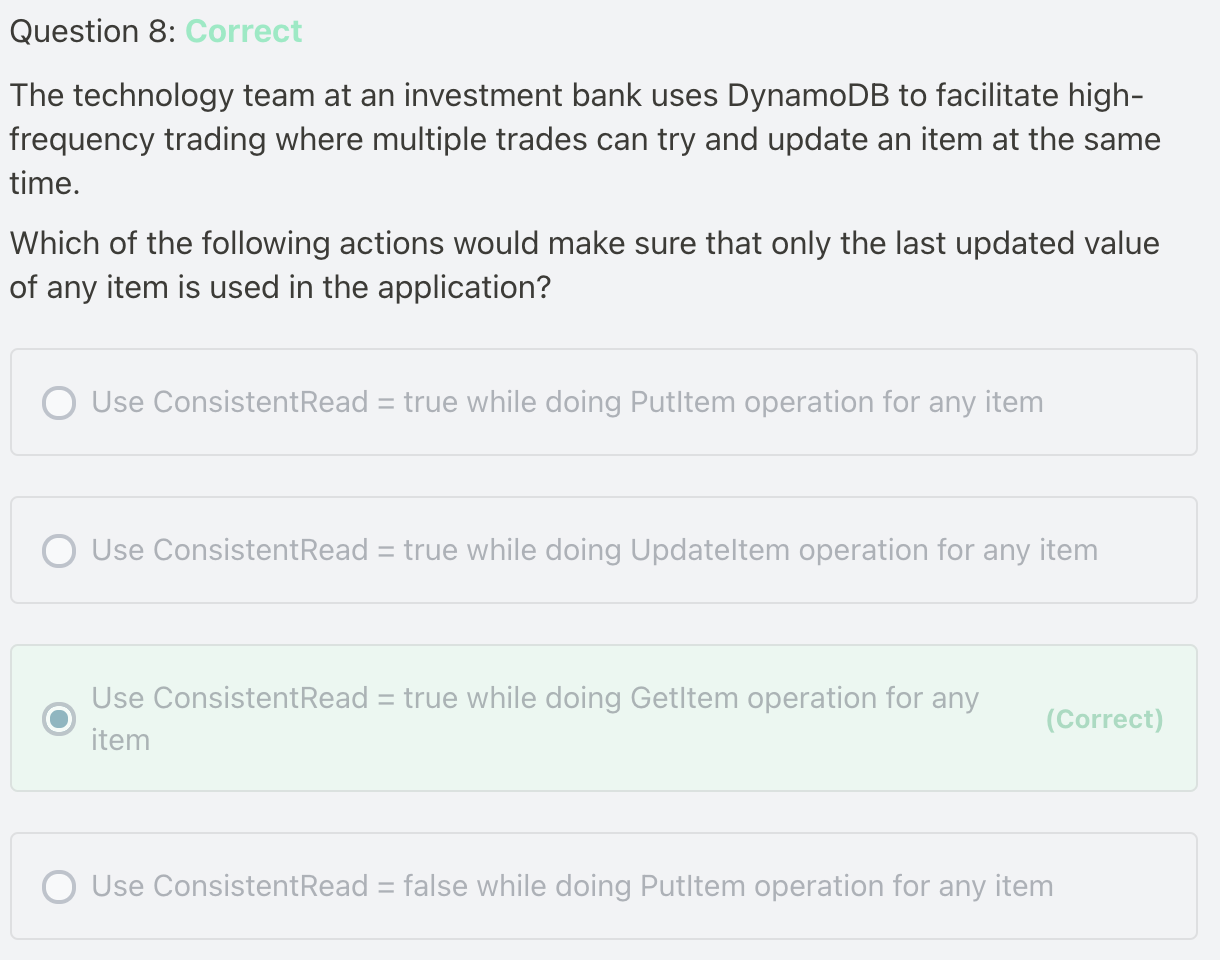
ConsistentRead = true: mean use Strongly Consisten read. Because by default, DynamoDB use Eventually consisten read.
And the parameter is only used for reading data, not for modify the data.