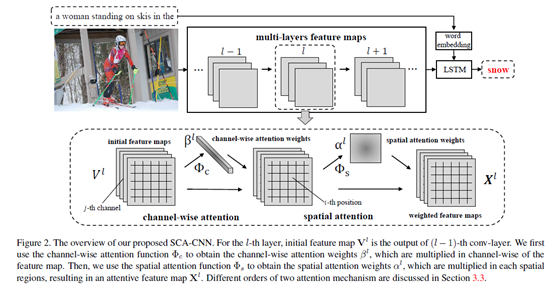
1. SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning(2017 CVPR)
主要研究方向:大多数现有的基于注意力的图像字幕模型只考虑了空间特征,本文是对同一层的feature map(特征图)加入了权重考虑。
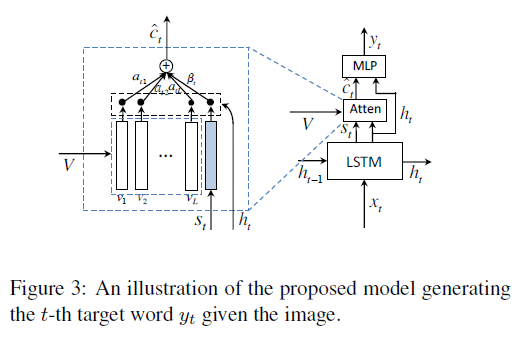
2. Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning(2017 CVPR)
主要研究内容: 更多的关注实体词之间的连词,比如“of”等。
解决思路:在框架中加入一个哨兵门,能够决定在生成实体词的时候应该注意图片,在生成连接词的时候,应该关注于语言。
Most methods force visual attention to be active for every generated word. However, the decoder likely requires little to no visual information from the image to predict non-visual words such as “the” and “of”.