from: https://zhuanlan.zhihu.com/p/105542913
摘要:前缀树(retrival, 简称trie)是一种可以支持快速模式检索的数据结构。在trie的基础上,一些人发展出了各种各样的压缩版本,比如双数组前缀树(Double-Array Trie, DAT)。DAT是各版本trie中,检索速度最快、压缩效率最高的一种,是高性能分词器存储词汇表时的首选。本文主要介绍DAT的基本思想、查询过程、构建过程和维护方法,对它的优劣势和适用场景进行了分析,最后用python语言实现了一个DAT、以具体地展示它的各个方面。
1. 引言
在信息检索领域,人们设计了多种多样的数据结构来提供各种各样的功能,以解决生产里出现的各种各样的需求。比如,在搜索引擎里,我们需要把序列数据(关键词或查询语句)妥善地存储起来,并且支持快速的查询,为此人们提出了前缀树(trie, 也叫字典树)。
2. 前缀树
前缀树的定义可以参考
李鹏宇:前缀树的简单实现zhuanlan.zhihu.com
。我们主要关心的,是前缀树的实现,即其节点和边的存储形式,以及模式的查询方式。
2.1. 基于哈希映射的trie
我们可以使用哈希映射来存储前缀树中,一个节点与其前驱节点的链接关系,进而实现一个基于哈希映射的trie。这是一种比较符合直觉的实现方式。
以散列表为例,哈希映射的查询动作,由映射和判断组成。查询动作耗时主要分布在映射环节,即使用哈希函数将数据映射为列表中的地址,因此基于哈希映射的trie的查询动作时间复杂度是O(k),其中k为待匹配模式串的长度。这个结构已经很快了。
2.2. 基于数组的trie
一些人希望进一步优化trie的查询性能,并为此提出了基于数组的trie,包括4数组trie、3数组trie和双数组trie。双数组trie是这类trie中,空间复杂度和时间复杂度最好的版本,应用较多。它把前缀树看做一个有限自动机——每个节点是状态机的状态,节点存储的字符是状态机的输入。状态机从一个节点出发,接收当前节点存储的字符,就可以转换到下一个状态,即后驱节点。我们可以采用非常简单的状态转换公式,即加法。这样,双数组trie查询操作的时间复杂度仍然是O(k),但是由于基本操作的复杂度很低,理论上速度比基于哈希映射的trie快。
3. 双数组前缀树的查询
3.1. 一维数组与有限状态机
我们用一个一维数组base来存储两个信息:(1)数组的index表示状态(对应前缀树上每一个节点;index就是相应节点的唯一表示);(2)每一个index上存储的数值的绝对值,是一个位移量(后面我们会解释这个值的含义和用法)。为了实现基于加法的状态转换,我们直接使用字符的ASCII码来表示字符(当然也可以用一个字符-ID映射来得到字符的整数类型id)。从一个字符串的第t-1个字符出发,转换到第t个字符的过程,可以这样描述:
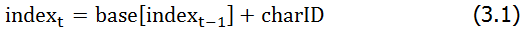
其中charID表示字符的ASCII码。这个式子所描述的动作,有点像循环神经网络(recurrent neural network, RNN)的神经元的行为,即基于模型过去的输出和当前时间的输入,计算当前的输出。
我们可以举一个例子来展示DAT的查询过程。
3.2. 双数组trie的查询过程
直观地看,DAT是一个自动机,其输入为上一个时间步的状态和当前时间的输入。每输入字符串的一个字符,自动机就基于这个字符以及之前时间步的状态,计算当前时间步的状态。我们基于自动机计算得到的状态来判断,目前已经输入的字符串,是否为词汇表某些词语的前缀——如果是,继续向自动机输入下一个字符;如果不是,说明词汇表没有收录这个字符串。
如表3-1,是一个简化版的字符编码表;3-2是一个简化版的词汇表。我们可以把词汇表存储到入一个基于hashmap的字典树,逻辑结构如图3-1。我们也可以把词汇表存储在一个双数组结构中,如表3-3。
表3-1 字符编码表示例

表3-2 词汇表

表3-3 两个一维数组的内容

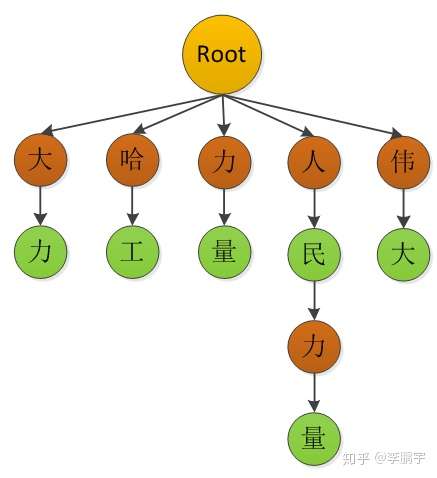 图3‑1 trie的逻辑结构
图3‑1 trie的逻辑结构
对结语hashmap的前缀树进行查询是比较容易的,只需要进行若干次map查询即可。那么,DAT的查询是否一样简单呢?
假如我想确认词语“人民”是否在词汇表中,需要这样查询:
(1) 初始状态是index=0;
(2) 向状态机输入”人”,得到下一个状态index=base[0] + 3=4。Check[4]=0,即新状态的前驱状态确实是0,表明词汇表中确实有一些首字为”人”的词语;
(3) 继续向状态机输入”民”,得到下一个状态index=base[4] + 4=5。Check[5]=4,即新状态的前驱状态确实是4,表明词汇表中确实有前缀为”人民”的词语。
(4) 正在检查的词语已经读取到词尾了,而Base[5]=-6<0,表明词汇中存在一个词语“人民”。也就是说,词汇表收录了正在检查的词语。
总的来说,DAT的查询操作非常简单快速。那么,base数组和check数组是什么,又是如何得到的呢?
3.3. base数组和check数组是什么?
如前所述,base数组里存储了两份信息:(1)index表示一个状态;(2)每个index处存储的整数,是计算后驱状态时,所需的偏移量。
Check数组里,存储的是一份校验信息,用于确认一个状态转移是否合法。
4. 双数组前缀树的构建
双数组前缀树的构建是一个相对比较复杂的过程,需要循序渐进地搞明白。
4.1. 构建DAT的基本思路
我们的任务是,把一个前缀树里所有的状态转移,存储到base数组中,并在check数组中存储对状态转移合法性的检验信息。
构建DAT的思路比较多,基本思路都是,在遍历前缀树的过程中,把遇到的状态转移存储到base数组里,如果遇到冲突就使用一定的策略解决冲突(增大相应位置存储的位移量,使前缀树中当前节点的所有后驱节点对应饿index为空)。
接下来介绍一种构建方法。
4.2. 一种DAT构建算法及其伪代码
我们首先把词汇表存储到一个基于hashmap的前缀树中(后面直接叫trie),结构如图3-1。
然后广度优先遍历这个trie,对每一个节点的操作是:
(1)当前节点对应base数组位置current_index,存储的偏移量默认是1。
(2)遍历当前节点的所有子节点,并检查各个子节点对应的base数组位置是否为空。如果全部为空,直接开始(3);如果有不为空的情况,加大base[current_index],直到所有子节点对应base数组位置为空,然后开始(3)。
(3)遍历当前节点的所有子节点,将它们存储到base数组中,并更新相应位置饿check数组信息。
我们可以用一个基于hashmap的trie来辅助DFS的进行。
4.3. DAT构建过程的展示
接下来,我们手工遍历图3-1所示的前缀树,并存储到双数组中。数组的初始大小是5,元素取值全部为0,表示“可用”。
4.3.1. 初始化所有词语的首字

4.3.2. 广度优先遍历trie
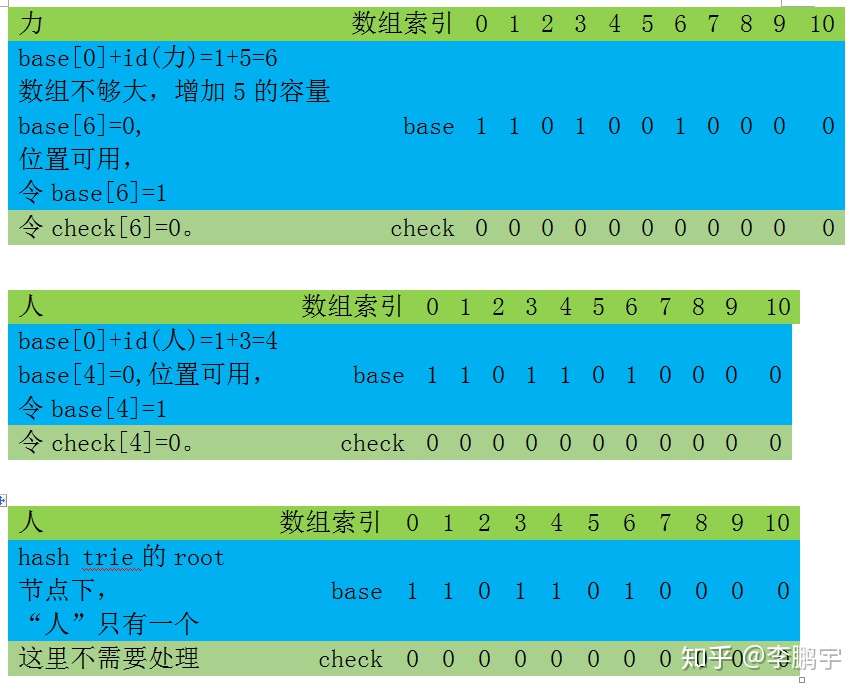
“大”前缀的所有子节点是[“力”]。我们现在检查这个前缀的末节点,和它的所有子节点构成的状态转移[“大力”],是否可以存储到base数组中:
(1) 使用3.2的方法,在base中查询前缀“大”,得到当前状态是index=base[0]+id(大)=1+2=3。
(2)那么自动机读取”力”后的状态是index’=base[3]+id(力)=1+5=6。
不好base[6]=1!=0,不可用,我们需要给”力”安排一个新的位置。只能修改base[3]的大小了,加一。
(3)那么自动机读取”力”后的状态是index’=base[3]+id(力)=2+5=7。运气不错,base[7]=0。我们可以零base[7]=1,表示“大力”这个前缀的末尾状态是7。感谢

的提示,这里将"1+5"更正为"2+5"。
(4)巧了,“力”字是“大力”这个词语的末尾字,对应trie中一个叶子节点,我们可以用一个符号来表示:令base[7]=-1。在以后的状态转移操作中,一律使用base[7]的绝对值来进行计算,而符号只用来判断是否为叶子节点。

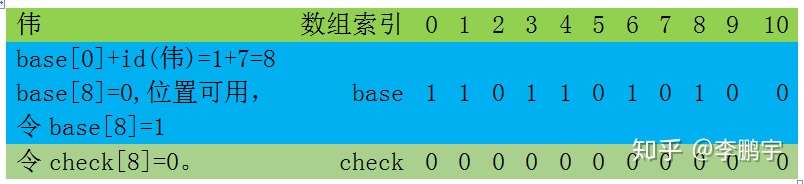
接下来,对trie中深度为1的其他节点采取类似操作。
然后,继续我们的广度优先遍历,直到所有深度对应的trie节点处理完毕。这时,base数组和check数组就可以支持3.2所描述的查询操作了。
4.4. 增删操作
一般来说,词汇表是需要经常更新的。比如说搜索引擎的分词器,需要尽快的完成各种新词的添加,以及一些无用词的删除。这就要求DAT有增删词语的功能。
增加词语的操作比较复杂。我们可能遇到一种非常幸运的情况,就是在添加词语的时候,没有遇到任何冲突,那就可以顺利添加了;更有可能的情况是,我们会在添加某个节点的时候,发现它的子节点在存储时会遇到冲突。在遇到冲突的情况下,我们需要把这个节点和它的子子孙孙,以及要添加的词语,都删掉,然后重新添加一遍。是的,这个操作非常慢。
删除词语的操作比较简单,把只属于这个词语的状态转移过程全部清空,即置为0即可。
4.5. DAT的优势和缺点
如2.2所述,DAT的特点就是查询快。
DAT的缺点比较多:
(1) 它的实现比较复杂,不能看出明显的逻辑结构、理解起来比较困难,不利于开发和维护活动的展开。
(2) 构建速度比较慢。因此,我们听说过用trie统计字符串频数,但是从没听说过用DAT统计。可以在初次加载词典的时候构建好DAT,然后缓存为文件,在以后的使用中直接加载缓存文件。
(3) 更新较慢。就像4.4所描述的,添加词语的操作具有较高的时间复杂度。当然,一些优化版本的DAT中,采用了其他形式的构建和更新策略,更新的速度会很快。
综上,DAT适合在高速查询、低速低频更新的场景中使用。
4.6. DAT的python实现
双数组前缀树的python实现可参考
https://github.com/lipengyuer/DataScience/blob/master/src/data_structure/DAT/DoubleArrayTrieTest4.py
5. 结语
假如我不太懂一个事物,那么我是无法把与它相关的机理讲透的,能做的就是把代码拿出来,作为笔记,以后“意会”就可以了。换句话说,如果我对一个知识点不太理解,那么在搞知识输出的时候,只能把实物摆出来、以隐性知识的形式来传播知识。
”隐性知识”是管理学里的一个概念,指的是“无法清晰表达,只可意会”的知识;相对地,还有一个“显性知识”,指的是可以用文字符号、数学符号等准确、清洗表达的知识。本文在介绍双数组前缀树的时候,主要以实物(即代码)的形式来展示,而没有用伪代码等形式详尽地说明DAT的构造过程,需要看这份笔记的人“意会”一下。因此这里有一部分内容没有讲透,是隐性知识。
隐性知识和显性知识的概念,可以应用到我们的知识管理和学习过程中。假如在学习过程中,只有我们把一部分内容掌握到非常好的程度,才有能力把该部分内容以显性知识的形式输出。否则,我们能输出的,就是“没有展开,没有讲透”的隐性知识。上大学的时候,班里比较勤奋的同学,比如隆兄,会在期末考试前给大家讲一下各门课程的内容。他们在讲课的过程中就复习了,还有我们这帮子人挑错,收货颇丰;当然主要是我们获益,能涨几分。隆兄们就是在利用知识输出的机会,考察自己的理解深度。
简单来说,我对DAT的理解还不太深,只能讲到这个程度啦。
注意:本文为李鹏宇(知乎个人主页https://www.zhihu.com/people/py-li-34)原创作品,受到著作权相关法规的保护。如需引用、转载,请注明来源信息:(1)作者名,即“李鹏宇”;(2)原始网页链接,即当前页面地址。如有疑问,可发邮件至我的邮箱:lipengyuer@126.com。