文章引起我关注的主要原因是在CoNLL03 NER的F1值超过BERT达到了93.09左右,名副其实的state-of-art。考虑到BERT训练的数据量和参数量都极大,而该文方法只用一个GPU训了一周,就达到了state-of-art效果,值得花时间看看。
一句话总结:使用BiLSTM模型,用动态embedding取代静态embedding,character-level的模型输出word-level的embedding. 每个词的embedding和具体任务中词所在的整句sequence都有关,算是解决了静态embedding在一词多义方面的短板,综合了上下文信息。
文章重点内容记录:
目前三种主流embedding:
A. 经典embedding
B. character-level 基于特定任务的embedding,不需要预训练,与任务的训练过程同步完成
C. 基于上下文的,由深度LSTM各层hidden state的线性组合而成的embedding
本文模型特点:
A. 模型以character为原子单位,在网络中,每个character都有一个对应的hidden state. -- 这个特点对需要多一步分词的中文来说可能有避免分词错误导致下游function继续错误的弊端。
B. 输出以word为单位的embedding, 这个embbeding由前向LSTM中,该词最后一个字母的hidden state 和反向LSTM中该词第一个字母的hidden state拼接组成,这样就能够兼顾上下文信息。具体说明见下图:
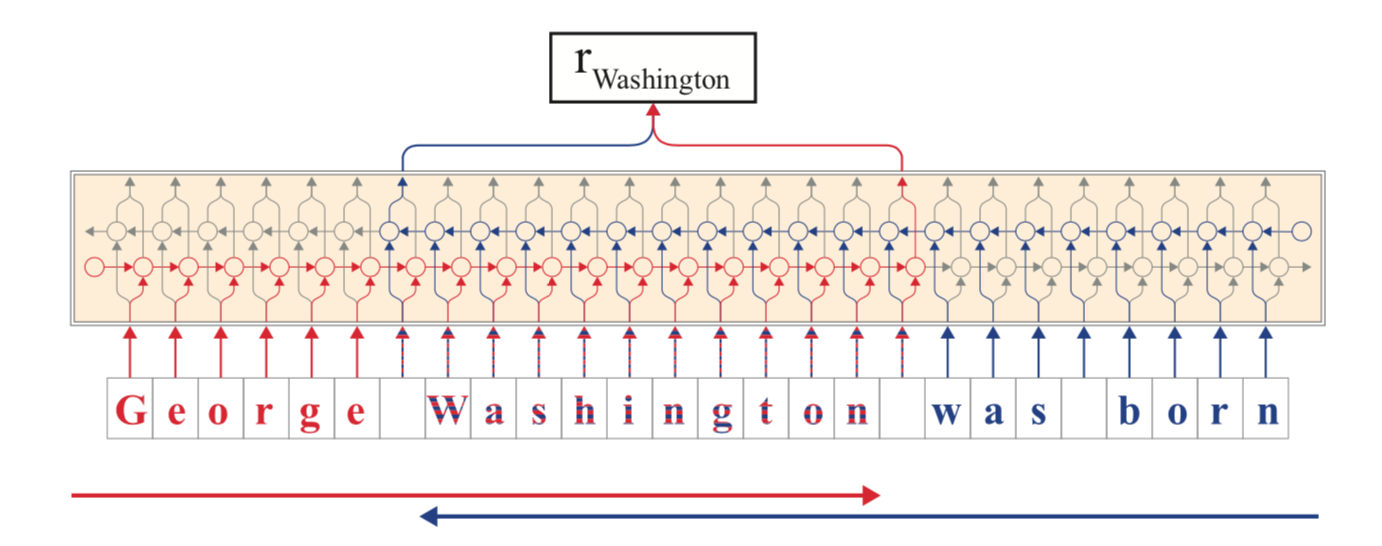
实验结果:
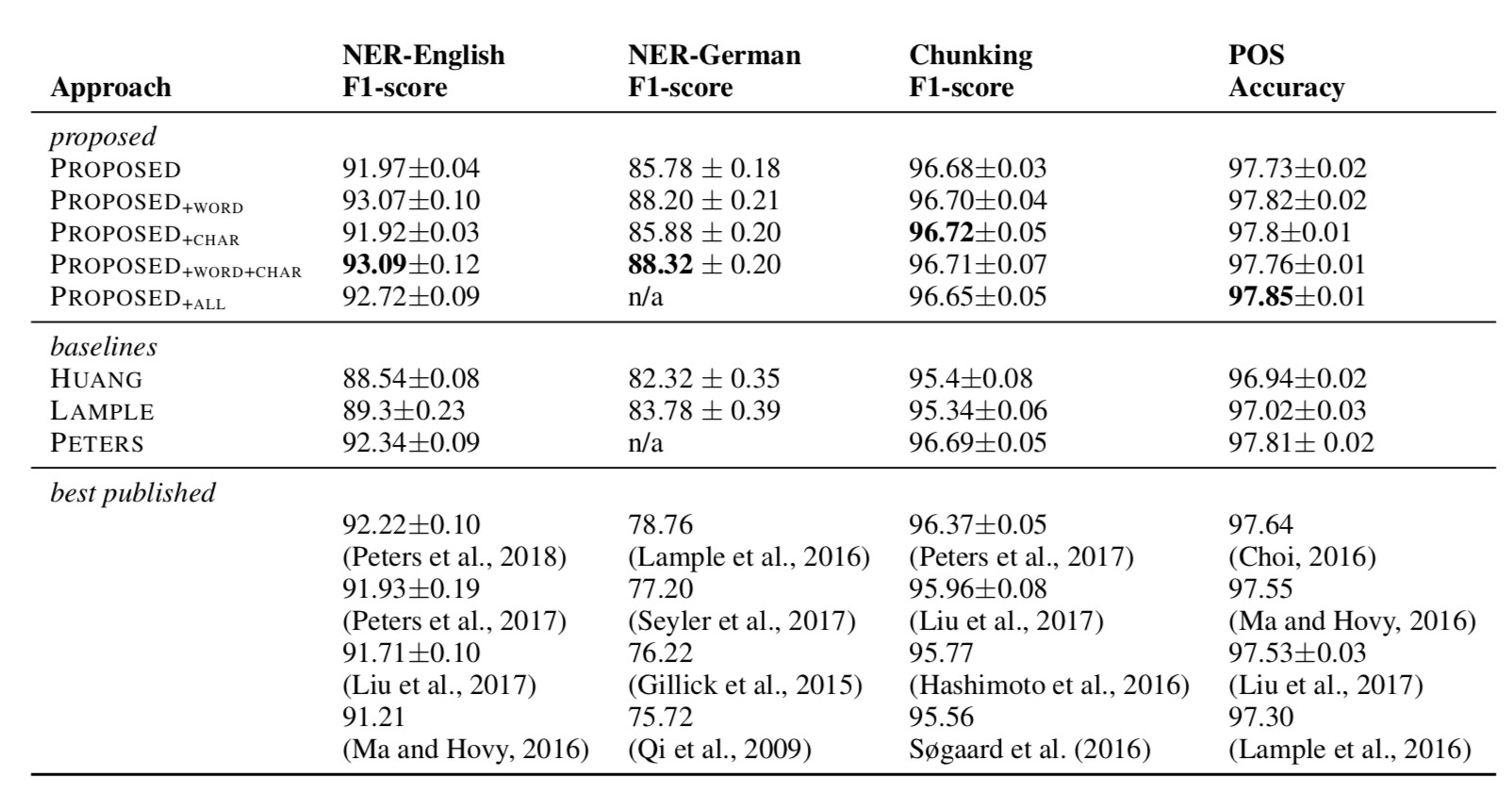
表格中PROPOSED表示文中提出的embedding, word代表经典预训练embedding, char表示任务相关的embedding,可以看出本文的动态embedding + 经典预训练embedding的组合最有效,char-embedding加不加基本没有影响。
模型训练相关参数:
语料库:英文 - 10亿词语料库 德文-5亿词语料库
训练过程: 1个GPU跑了一周
时间性能:
10个单词左右句子产生embedding需要10ms左右,20个单词句子基本就涨到20ms,对生产环境来说勉强可以接受。
正在尝试训一版中文动态embedding, 稍晚会补充结果。
如果有理解不到位的地方,欢迎指正。
原创文章,转载请注明出处。