介绍:
本问题是来自于课堂上老师关于贪心问题的第三讲.Huffman编码是最有效的二进制编码,其中贪心策略主要体现在根据频度来设置编码长度.最早在数据结构的便有学习到,当时采用的建树方式是带指针的结构体+小顶堆(使用小顶堆的优势在于堆是动态的,同时也有较高的效率——插入和删除并调整的效率约为O(lgN),查找最小的效率为O(1)),从理论上来说也是比较容易理解的.然而在一般的做题中我们实际只需要用数组模拟即可(好吧,其实也是因为没有学过c++里的堆模板).比较惭愧的是好久没写建树相关的内容了,差点不会写了,因此这里记录一下.
来源
Description
在课堂上,我们学习了哈夫曼编码的原理和实现方法,上实验课时也动手实现过,后来我们又追加介绍了哈夫曼编码的实际压缩和解压缩的实现方法,并且在课堂上也演示了,但当时我们却忽略了一个环节,那就是实际文件存储时,二进制是比特位,而存储的单位一般是字节,显示时又是按照十六进制的。现在给你一个已经用哈夫曼方法压缩过的十六进制文件,请你解压以便还原成原文。
Input
本问题有多组测试数据,第一行就是测试数据的组数nCase,对于每组测试数据,一共有四个部分,第一部分是一个字典(请注意,字典里可能含有空格!),原文本里面出现的任何字符一定在这个字典里面,并且已经按照使用频度从大到小顺序排列。第二部分是字典里相对应字符的使用频度。第三部分是待解压的行数n。第四部分是n行经过哈夫曼压缩的十六进制数组成的字符串。
Output
输出一共n行,每行就是对应输入的原文(请注意,输出的原文里可能含有空格!)。
Sample Input
1
AORST
60 22 16 13 6 4
5
7C
F3F2CC3C6FE24D3FC5AB7CC6
98BBD266C6FF81
FE6517F5B6663AF98FE2226676FA80
F317262FCFE662FC99D7D
Sample Output
AO
ASAO RST ATOAATS OSAATRR RRASTO
STROAR SSRTOAAA ||Error !
AASS TRAA RRRSSTA RASTAATTTSSSOOAOR
ASTRO STRAO AASSTRAO SSORAR
分析问题:
-
哈夫曼编码介绍
-
有以下一串字符编码:
11233324234我们需要对其进行二进制(因为哈夫曼编码就是一种二进制编码,依据老师的表述,如果去掉这一限制就很难称得上说有最好的编码了)压缩以使最后获得编码最小.
-
显然,基本的编码策略是针对不同的字符进行不同的编码压缩,让我们列出它们的种类和频度(这一字符在语句出现的次数)来进行比较一下,对于这个集合我们可以称为字典(包含了所有的字符):
序号 字符 频度 1 1 2 2 2 3 3 3 4 4 4 2 -
首先,我们需要建立对应的数学模型.设总的编码长度为wpl,每个字符的编码长度为(l_k),每个字符的频度(也就是权值)为(w_k),则(wpl=l_k*w_k)(0<=k<=字符的个数),其中(w_k)是确定的,为了使wpl最小,当(w_k)比较大的时候,我们需要使(l_k)尽量小.具体的解决思路便是贪心
-
贪心:每次我们取出两个最小的点,用这两个节点合并成为新的节点,新节点的权重是子节点的权重之和,如此反复直到只有一个子结点就构建了一个一棵树,我们称为哈夫曼树.
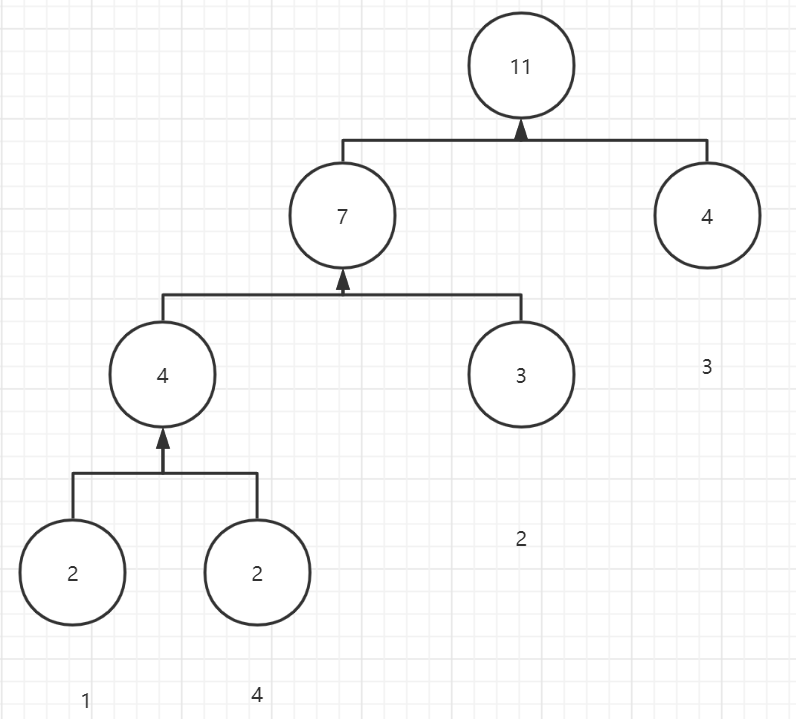
注:圆内的权重,圆外是对应字符
可以看到该树有一下几个特点:
- 是一棵二叉树且没有度为1的节点
- n个字符节点均为叶节点.由于我们每次总是去掉2个结点,增加一个节点直到最后生成的一个节点,所以最后会产生n-1个结点,共2n-1个结点
-
依据要求,关于编码我们可以确立两个基本的准则:
-
这个编码应该越简单越好
-
为了便于解析以及不引起混淆,一个编码不应该是另一个编码的前缀和
如对于:0,01这两个编码显然是无效的.
-
-
基于霍夫曼树,我们只要对树的左右边进行标号即可——左0右1或者左1右0,由此我们可以得出霍夫曼编码的另一个特定是不唯一.最终的编码(以左0右1为例):
序号 符号 Huffman编码 1 1 000 2 2 01 3 3 1 4 4 001
注:有时对于同一个字典可以构造不同形式的Huffman(如频度相同的字典),也就是异构的.
-
-
Huffman构造
- 数据结构:结构体数组,因为这里我们在意的仅仅是节点之间的父子关系,使用对应的属性记录即可.
- 求取最小值与倒数第二小的值:由于整道题的数据范围并不大,每一轮我们可以遍历一次,先判断当前数是不是小于最小值,如果小于,先将最小值赋值给倒数第二小的值,再将当前遍历到的值赋给最小值,否则将当前遍历到的值赋给倒数第二小的值.
-
解码
-
将原数据的十六进制编码转化为二进制编码:这里看到老师巧妙地使用了这个数组:
string hToBin[20] = {"0000","0001","0010","0011","0100","0101","0110","0111","1000","1001","1010","1011","1100","1101","1110","1111"}; -
转码:使用一个map,另外还有一个无法判断非法编码的问题,我们可以通过编码的最大长度进行判定.
-
-
扩展
-
有损压缩与无损压缩
无损压缩:如Huffman编码
有损压缩:如常见的mp4,mp3,牺牲了一些人耳不太敏感的频段.
-
#include <cstdio>
#include <iostream>
#include <cstring>
#include <algorithm>
#include <cmath>
#include <map>
#include <string>
#define INF 0x3f3f3f3f
using namespace std;
typedef long long ll;
const int N=1e3+10;
typedef struct{
int parent;
int left;
int right;
int weight;
char c;
bool used;
}Node;
Node arr[2*N];
int maxLen;
//将code向原文映射
map<string,string> codeMap;
void getCode(int index,string str);
string hexToBin(string str);
int max(int a,int b);
int main()
{
int n,t;
while(scanf("%d",&t)!=EOF){
while(t--){
//节点初始化
for(int i=0;i<2*N;i++){
arr[i].parent = 0;
arr[i].left = 0;
arr[i].right = 0;
arr[i].weight = 0;
arr[i].used = false;
arr[i].c = -1;
}
codeMap.clear();
char temp;
scanf("%*c%c",&temp);
n=0; //忘记初始化的垃圾!!!
while(temp!='
'){
arr[++n].c = temp;
// cout << "temp:" << temp << endl;
scanf("%c",&temp);
}
for(int i=1;i<=n;i++){
scanf("%d",&arr[i].weight);
// cout << "i:" << i << endl;
}
//做结构化的消解,(2*n-1)-(n)
arr[0].weight = INF;
int num=n; //记录所有节点个数
for(int i=1;i<=n-1;i++){
int minn=0,minn2=0;
for(int j=1;j<=num;j++){
if(arr[j].used==false&&arr[j].weight<arr[minn].weight){
//先将minn转换为minn2
minn2 = minn;
minn = j;
}else if(arr[j].used==false&&arr[j].weight<arr[minn2].weight){
minn2 = j;
}
}
if(minn == 0){
break;
}
//设置父节点
num++;
arr[num].weight = arr[minn].weight+arr[minn2].weight;
arr[num].left = minn;
arr[num].right = minn2;
//设置根节点
arr[minn].parent = num;
arr[minn].used = true;
arr[minn2].parent = num;
arr[minn2].used = true;
}
//进行编码
maxLen = 0; //最长编码长度
getCode(num,"");
//解析
int m;
scanf("%d",&m);
//cout << m << endl;
while(m--){
string str;
cin >> str;
str = hexToBin(str);
string temp = "";
int len = str.length();
for(int i=0;i < len;i++){
temp += str[i];
if(codeMap.count(temp) == 1){
cout << codeMap[temp];
temp = "";
}else if((int)temp.length() > maxLen){
// cout << "temp:" << temp << endl;
cout << "||Error !";
break;
}
}
if(temp != ""){
cout << "||Error !";
}
cout << endl;
}
}
}
return 0;
}
void getCode(int index,string str){
//递归出口,生成哈夫曼编码并且放在Map中
// cout << "index:" << index << " arr[index].c:" << arr[index].c << endl;
if(arr[index].c != -1){
codeMap[str] = arr[index].c;
//cout << "str:" << str << " index:" << index << endl;
maxLen = max(maxLen,str.length());
return ;
}
getCode(arr[index].left,str+'0');
getCode(arr[index].right,str+'1');
}
int max(int a,int b){
return a>b?a:b;
}
string hexToBin(string str){
//直接做映射,老师的这个方法确实不错
string hToBin[20] = {"0000","0001","0010","0011","0100","0101","0110","0111","1000","1001","1010","1011","1100","1101","1110","1111"};
string ans = "";
int len = str.length(),temp;
for(int i=0;i<len;i++){
if(str[i]>='A'){
temp = str[i]-'A'+10;
}else{
temp = str[i]-'0';
}
ans += hToBin[temp];
}
return ans;
}
注:由于写完已经错过了交题的时间,代码只通过了样例,恐怕还有些细节性的问题(对于这点我应该很有信心!!!)
注(11.25):代码已更新,因为没有去掉调试的两个内容导致错了好几发,最后还是提交成功了,但是之所以能ac的原因个人推测还是老师数据太弱了!