文件基本操作流程:
一、 创建文件对象
二、 调用文件方法进行操作
三、 关闭文件(注意:只有在关闭文件后,才会写入数据)
fh = open('李白诗句','w',encoding='utf-8')
fh.write('''弃我去者,昨日之日不可留;
乱我心者,今日之日多烦忧。
长风万里送秋雁,对此可以酣高楼。
蓬莱文章建安骨,中间小谢又清发。
''')
fh.close()
open()函数的不同模式:
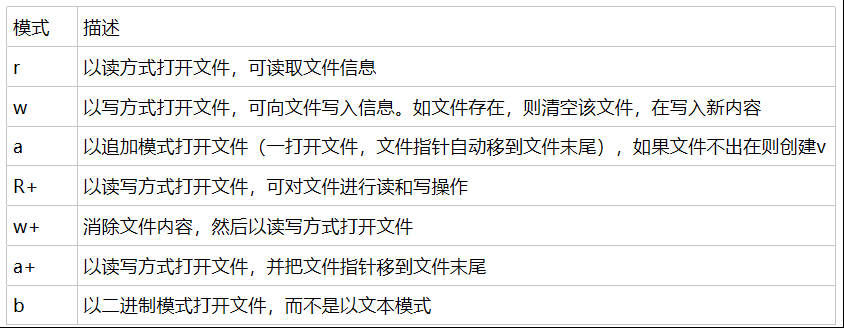
读操作
read() #默认显示所有文本
fh = open('李白诗句',encoding='utf-8')
print(fh.read())
>>> 弃我去者,昨日之日不可留;
乱我心者,今日之日多烦忧。
长风万里送秋雁,对此可以酣高楼。
蓬莱文章建安骨,中间小谢又清发。
read(4) #显示4个字符
fh = open('李白诗句',encoding='utf-8')
print(fh.read(4)) #显示4个字符
>>> 弃我去者
readline() #只读取一行,每次调用输出一行
fh = open('李白诗句',encoding='utf-8')
print(fh.readline())
['弃我去者,昨日之日不可留;]
readlines() #将文件中各行读出来,放到一个列表中返回。列表中每个元素都是文件的一行,并且都是字符串
fh = open('李白诗句',encoding='utf-8')
print(fh.readlines())
['弃我去者,昨日之日不可留;
', '乱我心者,今日之日多烦忧。
', '长风万里送秋雁,对此可以酣高楼。
', '
蓬莱文章建安骨,中间小谢又清发。
', '俱怀逸兴壮思飞,欲上青天览明月。
', '抽刀断水水更流,举杯消愁愁更愁。
', '人生在世不称意,明朝散发弄扁舟。']
写操作
write() #把文件写入缓冲区,当文件关闭时才会写入内存
对于大数据文件:
如果文件很大,乃至于内存空间不足,就不能继续使用 read()或者readlines()操作
因为文件是可迭代的对象,直接用 for 来迭代即可
fh = open('李白诗句',encoding='utf-8')
number = 0
for i in fh: # 这是for内部将f对象做成一个迭代器,用一行去一行。
number += 1
print(i.strip())
弃我去者,昨日之日不可留
乱我心者,今日之日多烦忧。
长风万里送秋雁,对此可以酣高楼。
蓬莱文章建安骨,中间小谢又清发。
其他操作方法:
1、tell() 查看光标当前的位置
2、seek()
seek(offset ,[whence]) 方法改变当前文件的位置
offset变量表示要移动的字节数。whence变量表示要从哪个位置开始偏移
注意:默认以文件的开头未参照物进行移动,即 whence = 0,这时候 offset 必须是大于等于0 的整数
当 whence = 1时,表示从当前位置开始计算偏移量。如果 offset 是负数,表示从当前位置向前移动;如果 offset 是正数,表示从当前位置向后移动
当 whence = 2时,表示相对文件末尾移动
3、使用 with 语句操作(在 with 语句中就不用close()了)
with open('李白诗句','r',encoding='utf-8') as fh:
print(fh.readline())
>>> 弃我去者,昨日之日不可留;
4、flush() 用来刷新缓冲区,将缓冲区中的数据立刻写入文件,同时清空缓冲区
5、truncate() 用于截断文件,如果指定了可选参数 size,则表示保留前size 个字节,删除 size 后面的所有字符。 如果没有指定 size,则从当前位置起截断。
不能在r模式下
在w模式下:先清空,再写,再截断
在a模式下:直接将指定位置后的内容截断