今天用油猴脚本vip一件解析看神奇队长。想到了问题,这个页面应该是找到了视频的api的接口,通过接口调用获取到了视频的地址。
那自己找腾讯视频地址多费劲啊,现在越来越多的参数,眼花缭乱的。
那我就找到这个能够解析vip视频的,解析网站的视频地址,不就OK了。
network上发现,这个视频是通过ts流的形式。

并且还有视频地址和index.m3u8,但是我们怎么获得这些20190527/参数呢。(m3u8中有一部电影的所有ts流参数)
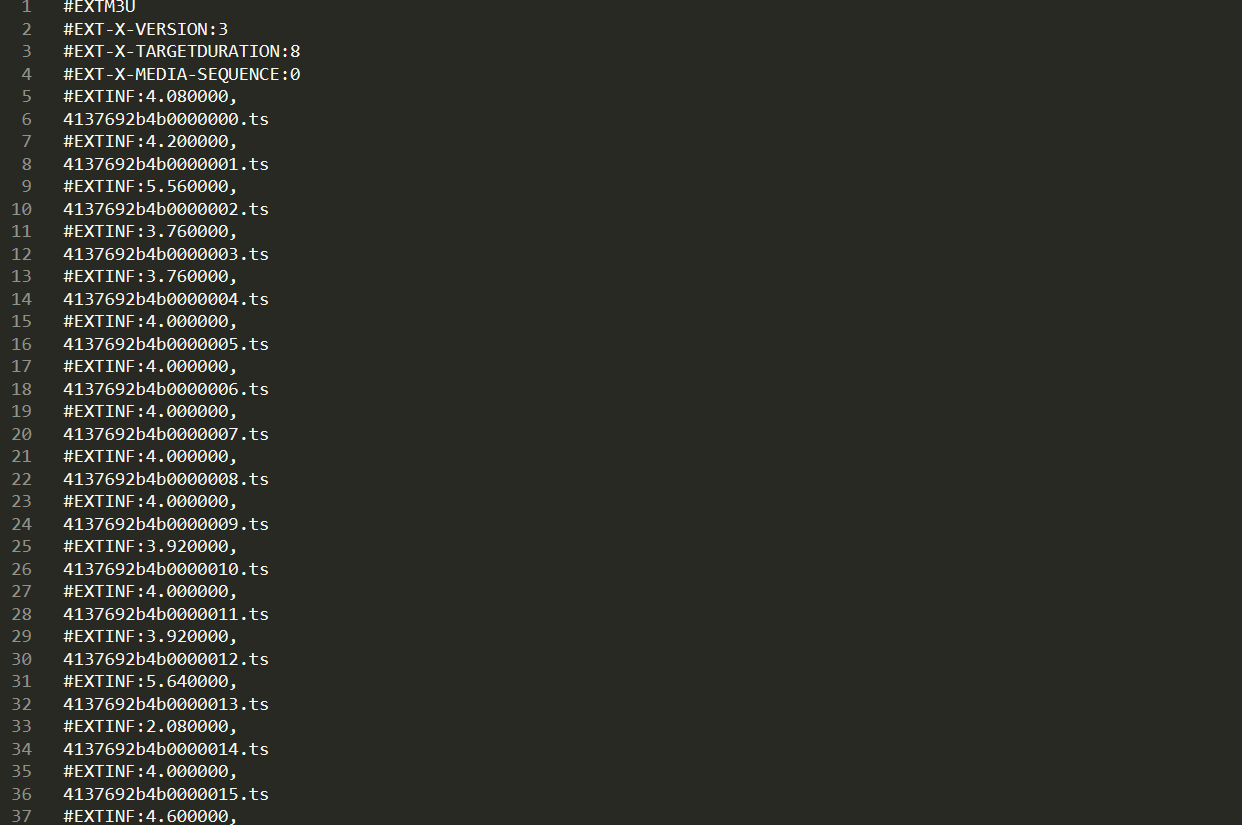
我找到了个api.php,即接口地址,访问,返回json数据。
url: http://p.p40.top/api.php?url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fxyne4253g35nak3%2Fm0031od9ekb.html


看到了视频流所在地址,然后访问地址,可以直接下载m3u8文件,文件中就是ts流参数了。
因此思路就是:用py模拟浏览器向解析网站的api.php请求你想看的vip视频的url即http://p.p40.top/api.php?url=https%3A%2F%2Fv.qq.com%2Fx%2Fcover%2Fxyne4253g35nak3%2Fm0031od9ekb.html
然后正则匹配到m3u8的地址,去请求后,下载到本地,打开匹配ts流的数字id。
发现视频地址就是api返回的json数据的url+/1000k/hls/xxx

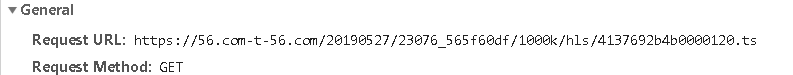
然后依次下载完ts流文件后,保存到本地。再转化成mp4,明儿实现。网上有些现成的。我试着改编下。
这样父母不需要怎么操作,我直接下下来本地给他们看就好了。嘿嘿
脚本如下:
# -*- coding: UTF-8 -*- import requests import re import os,shutil from urllib.request import urlretrieve from multiprocessing import Pool def cbk(a,b,c): '''''回调函数 @a:已经下载的数据块 @b:数据块的大小 @c:远程文件的大小 ''' per=100.0*a*b/c if per>100: per=100 print('%.2f%%' % per) def get_api_data(QQ_film_url): #正则匹配获取api返回的index.m3u8链接地址 api_url='http://p.p40.top/api.php' user_agent={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} get_url=api_url+'?url='+QQ_film_url print(get_url) response=requests.get(get_url,headers=user_agent).text pattern=re.compile('url.*?m3u8') get_data=pattern.findall(response)[0][6:].replace('\','') return get_data def m3u8_download(m3u8_url):#获取下载m3u8文件 if os.path.exists('F:\vip电影\index.m3u8')!=True:#判断文件是否已经存在,存在则不操作。不存在才下载。 urlretrieve(url=m3u8_url, filename=path, reporthook=cbk) else: print(path+'已存在') def get_ts():#通过m3u8文件,正则匹配需要的ts流 with open(path)as f: data=f.read() pattern=re.compile('.*.ts') get_ts_data=re.findall(pattern,data) return get_ts_data def ts_download(ts_list):#下载ts流 try: ts_url = m3u8_url[:-10]+'{}'.format(ts_list)#获取ts流 url地址 urlretrieve(url=ts_url, filename=path[:-10] + r'\' + '{}'.format(ts_url[-8:])) except Exception: print(ts_url+'保存文件错误') def pool(ts_list):#多进程爬取所有的ts流到文件夹中,参考的那个py脚本,没用过pool进程池 print('经过计算,需要下载%s个文件'%len(ts_list)) print(ts_list[0]) pool=Pool(16) pool.map(ts_download,[i for i in ts_list]) pool.close() pool.join() print('下载完成') ts_to_mp4() def ts_to_mp4(): print('dos实现ts合并为mp4') str = 'copy /b ' + r'F:vip电影' + '*.ts ' + ' '+ r'F:vip电影gogogo' + 'jingqi.mp4' os.system(str) if os.path.exists('F:\vip电影\gogogo\jingqi.mp4')==True: print('good job') path = 'F:\vip电影\index.m3u8' url = 'https://v.qq.com/x/cover/xyne4253g35nak3/m0031od9ekb.html' m3u8_url = get_api_data(url)[:-10] + '1000k/hls/index.m3u8' print(m3u8_url) m3u8_download(m3u8_url) ts_list = get_ts() if __name__ == '__main__': pool(ts_list)


成功,可能是多进程模块的问题,还是出现了将近15个文件错误。少了15个文件,但是为啥爬下来的时长比腾讯视频里的还长。
脚本还有很多地方都可以改进(锻炼自己写脚本的能力),改成类的调用,通过类中的self,一个函数接着一个函数调用。并且试试用多线程试试,多进程总有奇怪的问题,不统一。
看了一会儿,发现,观影视觉极差,我感觉丢失的不止是15个文件,音话都不同步了,是不是直接copy拼接命令有瑕疵。有待研究