1、在详细介绍 IOC 容器的工作原理前,这里先介绍一下实现 IOC 所用到的一些辅助类,包括BeanDefinition、BeanReference、PropertyValues、PropertyValue。按照顺序先从 BeanDefinition 开始介绍。BeanDefinition从字面意思上翻译成中文就是 “Bean 的定义”。从翻译结果中就可以猜出这个类的用途,即根据 Bean 配置信息生成相应的 Bean 详情对象。
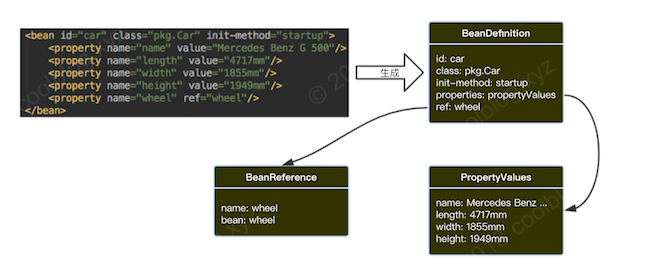
图2 根据 bean 配置生成 BeanDefinition
看完上图就对 BeanDefinition 的用途有了更进一步的认识。接下来我们来说说上图中的 ref 对应的 BeanReference 对象。BeanReference 对象保存的是 bean 配置中 ref 属性对应的值,在后续 BeanFactory 实例化 bean 时,会根据 BeanReference 保存的值去实例化 bean 所依赖的其他 bean。接下来说说 PropertyValues 和 PropertyValue 这两个长的比较像的类,首先是PropertyValue。PropertyValue 中有两个字段 name 和 value,用于记录 bean 配置中的标签的属性值。然后是PropertyValues,PropertyValues 从字面意思上来看,是 PropertyValue 复数形式,在功能上等同于 List。那么为什么 Spring 不直接使用 List,而自己定义一个新类呢?答案是要获得一定的控制权,看下面的代码:
public class PropertyValues {
private final List<PropertyValue> propertyValueList = new ArrayList<PropertyValue>();
public void addPropertyValue(PropertyValue pv) {
// 在这里可以对参数值 pv 做一些处理,如果直接使用 List,则就不行了
this.propertyValueList.add(pv);
}
public List<PropertyValue> getPropertyValues() {
return this.propertyValueList;
}
}
XML的解析过程:
BeanFactory 初始化时,会根据传入的 xml 配置文件路径加载并解析配置文件。但是加载和解析 xml 配置文件这种脏活累活,BeanFactory 可不太愿意干,它只想高冷的管理容器中的 bean。于是 BeanFactory 将加载和解析配置文件的任务委托给专职人员 BeanDefinitionReader 的实现类 XmlBeanDefinitionReader 去做。那么 XmlBeanDefinitionReader 具体是怎么做的呢?
(1)将 xml 配置文件加载到内存中
(2)获取根标签下所有的标签
(3)遍历获取到的标签列表,并从标签中读取 id,class 属性
(4)创建 BeanDefinition 对象,并将刚刚读取到的 id,class 属性值保存到对象中
(5)遍历标签下的标签,从中读取属性值,并保持在 BeanDefinition 对象中
(6)将 <id, BeanDefinition> 键值对缓存在 Map 中,留作后用
(7)重复3、4、5、6步,直至解析结束
注册 BeanPostProcessor:
BeanPostProcessor 接口是 Spring 对外拓展的接口之一,其主要用途提供一个机会,让开发人员能够插手 bean 的实例化过程。通过实现这个接口,我们就可在 bean 实例化时,对bean 进行一些处理。比如,我们所熟悉的 AOP 就是在这里将切面逻辑织入相关 bean 中的。正是因为有了 BeanPostProcessor 接口作为桥梁,才使得 AOP 可以和 IOC 容器产生联系。
XmlBeanDefinitionReader 在完成解析工作后,BeanFactory 会将它解析得到的 <id, BeanDefinition> 键值对注册到自己的 beanDefinitionMap 中。BeanFactory 注册好 BeanDefinition 后,就立即开始注册 BeanPostProcessor 相关实现类。这个过程比较简单:
(1)根据 BeanDefinition 记录的信息,寻找所有实现了 BeanPostProcessor 接口的类。
(2)实例化 BeanPostProcessor 接口的实现类
(3)将实例化好的对象放入 List中
(4)重复2、3步,直至所有的实现类完成注册
getBean 过程解析
在完成了 xml 的解析、BeanDefinition 的注册以及 BeanPostProcessor 的注册过程后。BeanFactory 初始化的工作算是结束了,此时 BeanFactory 处于就绪状态,等待外部程序的调用。
外部程序一般都是通过调用 BeanFactory 的 getBean(String name) 方法来获取容器中的 bean。BeanFactory 具有延迟实例化 bean 的特性,也就是等外部程序需要的时候,才实例化相关的 bean。这样做的好处是比较显而易见的,第一是提高了 BeanFactory 的初始化速度,第二是节省了内存资源。下面我们就来详细说说 bean 的实例化过程:
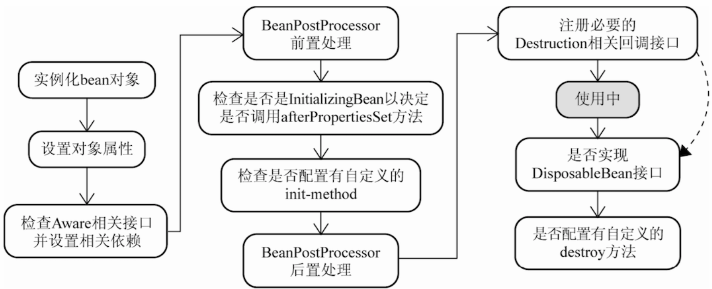
Spring Bean的实例化过程:
BeanFactory 的生命流程:
(1)BeanFactory 加载 Bean 配置文件,将读到的 Bean 配置封装成 BeanDefinition 对象
(2)将封装好的 BeanDefinition 对象注册到 BeanDefinition 容器中
(3)注册 BeanPostProcessor 相关实现类到 BeanPostProcessor 容器中
(4)BeanFactory 进入就绪状态
(5)外部调用 BeanFactory 的 getBean(String name) 方法,BeanFactory 着手实例化相应的 bean
(6)重复步骤 3 和 4,直至程序退出,BeanFactory 被销毁